关于携程网大数据平台的那点事!
携程作为一个大规模的在线票务服务公司,它的大数据工程师是怎样助其把繁杂大量的数据整理得有条不紊,保持公司的高效正常运作的呢?携程的做法,对其他需要构建实时大数据平台的公司,有没有借鉴作用呢?大圣众包威客平台(www.dashengzb.cn)为你一一道来。

一、携程处理大数据面临什么问题
众所周知,携程旅行网拥有国内外六十余万家会员酒店可供预订,已在17个大城市设立分公司,员工超过25000人。它还向超过9000万会员提供集酒店预订、机票预订、度假预订、商旅管理、特惠商户及旅游资讯在内的全方位旅行服务。
作为一家国内外著名的大规模的在线票务服务公司,携程是如何处理大量、复杂的数据的呢?它在处理这些杂乱的数据当中又面临着什么问题呢?
1.多
携程的业务部门非常多,业务形态差异也较大,变化也较快。原来的那种Batch形式的数据处理方式,已经很难满足各个业务的数据获取和分析的需要,他们需要更为实时地分析和处理数据。
2.杂
由于业务部门的技术力量参差不齐,而且各个部门的技术选型五花八门——消息队列有使用ActiveMQ、RabbitMQ、Kafka的;分析平台有使用Storm、Spark-streaming,甚至是自己写程序处理的,往往导致实时数据应用的稳定性难以保证。况且,他们的主要精力还要放在业务需求的实现上。
3.独
如果度假要使用酒店的实时数据,而两者的分析处理的系统不同,这样会导致数据和信息的共享不顺畅。
4.缺
缺少周边设施——像报警、监控这些东西,也是携程要面临的问题之一。
综上所述,携程亟需打造一个统一的实时大数据平台。
二、打造统一的实时大数据平台解决问题
得知问题的所在后,携程是怎样选择一个统一的实时大数据平台的呢?更具体地说,技术选型为何?
尽管很多技术选型可供选择,然而经过专业人士的分析,出于稳定和成熟度的考量,实时平台选择了Storm,消息队列确定了是Kafka。由此,构建平台正式开始!
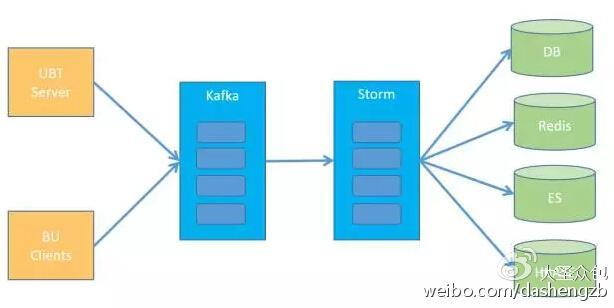
平台的架构图比较简单,就是从一些业务的服务器上收集日志或业务数据,然后实时写入Kafka里;Storm作业从Kafka读取数据并进行计算,然后把计算结果吐到各个业务线依赖的外部存储中。
三、这个统一的实时大数据平台的优势
Storm与Kafka强强联手,让这个统一的实时大数据平台满足了4个需求:
1.稳定性
我们都知道,稳定性是任何平台和系统的生命线。Storm与Kafka的配搭从资源控制上来说,保证了平台的稳定性。老实说,Storm在资源隔离方面做得并不是太好,所以需要对用户的Storm作业的并发做一些控制。具体的做法还是封装Storm的接口,将原来设定topology和executor并发的方法去掉,而把这些设置挪到Portal中。
下图为示例的代码:
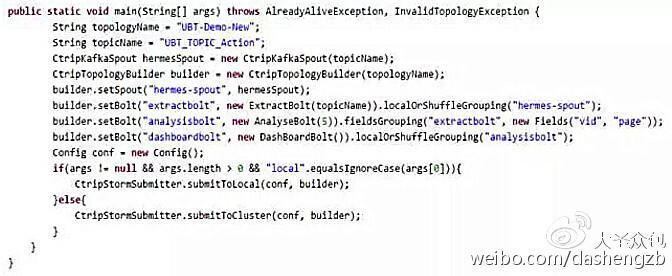
另外,还需要做一个统一的Portal方便用户管理,这样,用户可以查看Topic的相关信息,也可以用来管理自己的Storm作业,配置、启动、Rebalance、监控等一系列功能都能够在上面完成。
2.信息共享
统一的实时大数据平台能够方便信息的共享。这里的信息共享有两个层面的含义:一是数据的共享,二是应用场景的共享。
一般认为,数据共享的前提,是指用户要清晰地知道使用数据源的那个业务的含义,以及其中数据的Schema。这要求用户能够在一个集中的地方非常简便地看到这些信息。携程的解决方式是:
①使用Avro的方式定义数据的Schema,并将这些信息放在一个统一的Portal站点上;
②数据的生产者创建Topic,然后上传Avro格式的Schema;
③系统根据Avro的Schema生成Java类,并生成相应的JAR,再把JAR加入Maven仓库。
对于数据的使用者来说,他只需要在项目中直接加入依赖即可。
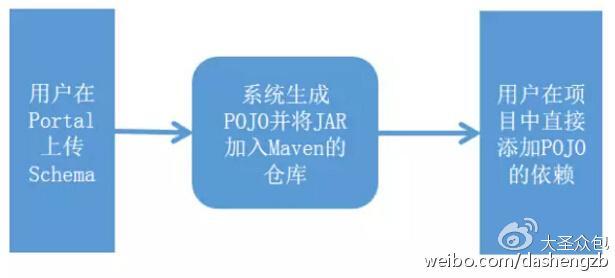
此外,还应封装Storm的API,帮助用户实现反序列化的过程。这样,用户只要继承一个类,然后制定消息对应的类,系统就能够自动完成消息的反序列化,在process方法中拿到的就是已经反序列化的对象,这对用户来说是非常方便的。
具体示例代码如下图:

3.及时性
当然,服务响应需要及时。用户在开发、测试、上线及维护的整个过程中,都会遇到各种各样的问题,都需要得到及时的帮助和支持。
4.完整性
完整的配套设施,包括测试环境,上线、监控和报警,都是一个统一的实时大数据平台所必须的。
通过对高新科技的钻研和应用,越来越多大规模的企业迈进大数据产业中,也引领着大数据产业生态的良性发展。
文/大圣众包平台
关键字:产品经理, storm
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
