世界模型又近了?MIT惊人研究:LLM已模拟现实世界,绝非随机鹦鹉!
LLM离世界模型,究竟有多远?
去年,MIT的一篇文章发现了惊人的结论:在LLM内部,存在一个世界模型。
LLM不仅学习了表面的统计数据,还学习了包括空间和时间等基本纬度的世界模型。

Llama-2-70B竟然能够描绘出研究人员真实世界的文字地图
不仅如此,MIT最近又发现:在LLM的深处,发展出了一种对现实的模拟,它们对语言的理解,已经远远超出了简单的模仿!

论文地址:https://arxiv.org/abs/2305.11169
具体来说,MIT计算机科学和人工智能实验室 (CSAIL)的两名学者发现——
尽管只用「预测下一个token」这种看似只包含纯粹统计概率的目标,来训练LLM学习编程语言,模型依旧可以学习到程序中的形式化语义。
这表明,语言模型可能会发展自己对现实的理解,以此作为提高其生成能力的一种方式。
因此,LLM在未来的某一天,可能会比今天更深层次地理解语言。
目前这篇文章已被ICML 2024接收,实验所用代码也已经公布在GitHub上。
仓库地址:https://github.com/charlesjin/emergent-semantics
01 没有眼睛,LLM就「看」不到吗?
如果让GPT-4去闻一下被雨水浸湿的露营地的味道,它会礼貌地拒绝你。

不过,它仍然会给你一个诗意的描述:有新鲜的泥土香气,和清爽的雨味,还有松树或湿树叶的痕迹。
GPT-4没见过下雨,也没有鼻子,但它能模仿大量训练数据中存在的文本。
缺少一双眼睛,是不是就意味着语言模型永远无法理解「狮子比家猫更大」?
LLM能理解现实世界和各种抽象概念吗?还是仅仅在「鹦鹉学舌」,纯粹依靠统计概率预测下一个token?
LLM的工作原理,依旧是未解之谜。AI圈的大佬们,时不时就要因为这个问题展开一场论战。
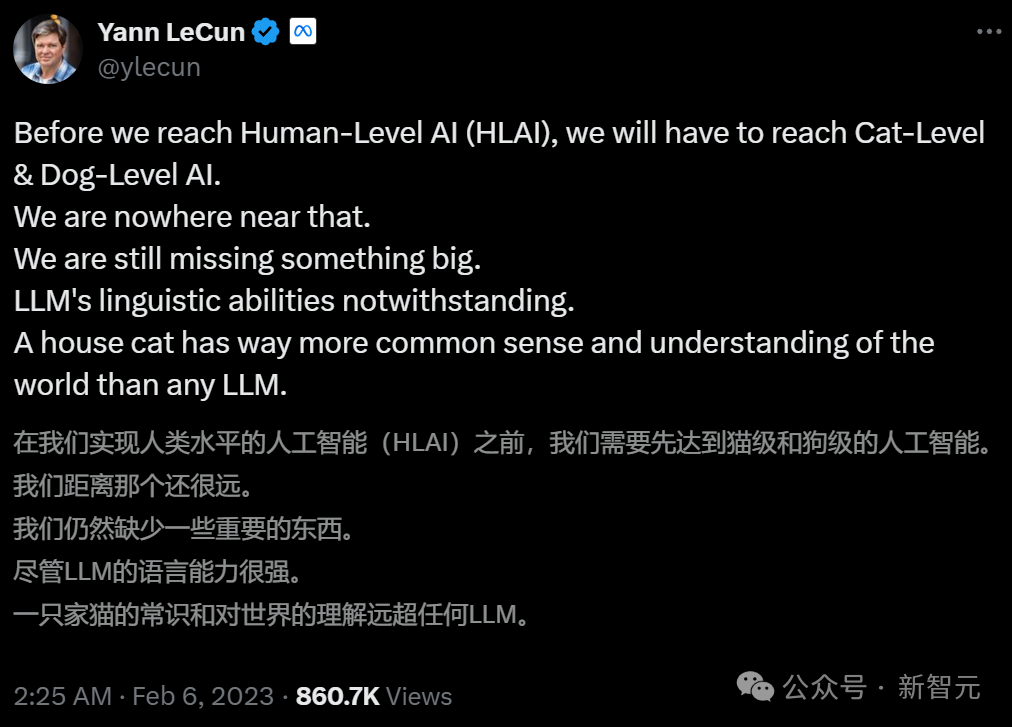
LeCun坚定认为,LLM的智能绝对被高估了!他最著名的论断,就是那句「大语言模型不如家里养的猫」。
「猫可以记忆,可以理解物理世界,可以计划复杂的行动,可以进行一定程度的推理,这实际上已经比最大的模型要好了,意味着我们在概念层面有重要的缺失,无法让机器像动物和人类一样聪明。」
没有感官,不耽误ChatGPT为你描述各种气味和图片;没有生活经验,很多用户依旧「遇事不决,ChatGPT解决」;看起来完全没有共情能力,Character.ai上的「心理学家」还是能俘获美国一千万青少年的心。
很多人将此解释为纯粹的统计现象,LLM只是在「鹦鹉学舌」,对大量训练语料中存在的文本进行模仿,并不是像人类一样拥有同等水平的智能或感知。
但现在,MIT的研究证明,并非如此!
LLM内部,绝对存在着对现实世界的理解。
02 LLM破解卡雷尔谜题,意味着什么
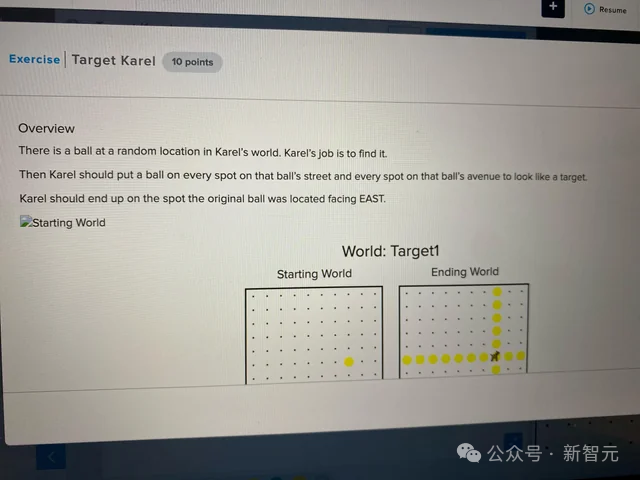
为了探究这个谜团,MIT CSAIL的研究者们,开发了一套小型卡雷尔谜题(Karel Puzzle)。

简单介绍下,什么是卡雷尔谜题
其中包括让模型用指令在模拟环境中控制机器人的行动。

卡雷尔语法规范
然后他们在训练LLM学习一种特定的解决方案,但没有演示其中的工作原理。
最后,作者提出了一种名为「探针」(probing)的机器学习技术,用于在模型生成新解决方案时,深入了解其中的「思维过程」。
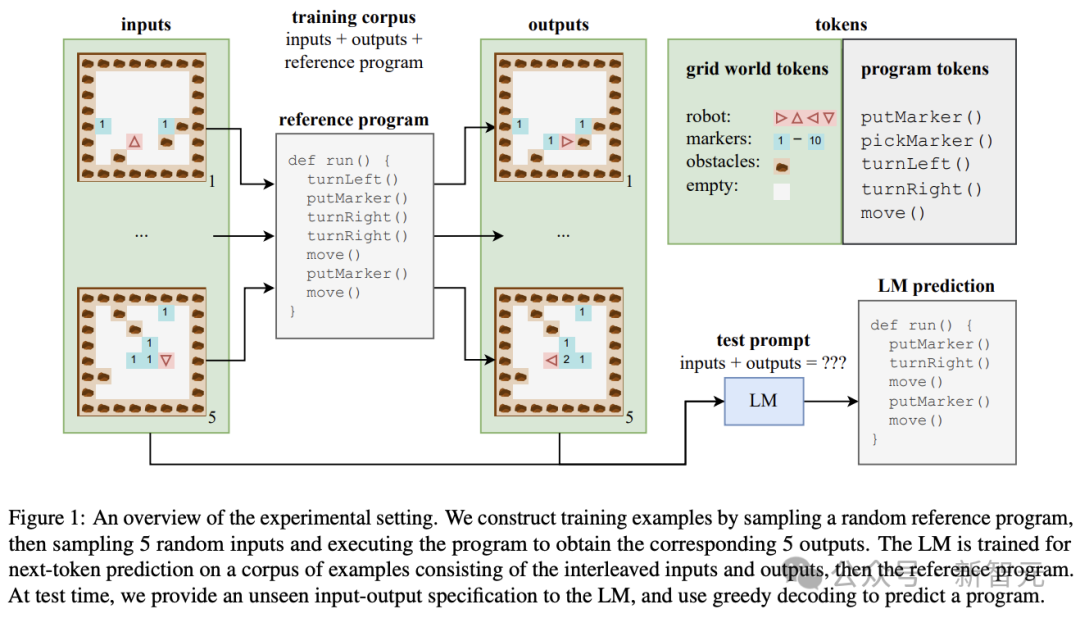
研究者通过对随机参考程序进行采样来构建训练示例,然后对5个随机输入进行采样并执行程序,以获得相应的5个输出。LM由交错输入和输出组成的示例语料库上进行下一个token预测训练,然后是参考程序。在测试时,研究者向LM提供看不见的输入输出规范,并使用贪婪解码来预测程序
在超过100万个随机谜题上进行训练后,研究人员发现,模型自发地形成了对底层模拟环境的概念!尽管训练期间,它们并没有接触过这方面的信息。
这个结果,不仅挑战了我们对LLM的固有印象,也质疑了我们对思维过程本质的认知——
在学习语义的过程中,究竟哪些类型的信息才是必需的?
实验刚开始时,模型生成的随机指令几乎无法运行;但完成训练时,指令的正确率达到了92.4%。
论文一作Jin表示,「这是一个非常激动人心的时刻,因为我们认为,如果语言模型能以这种准确度完成任务,我们也会期望,它能理解语言的含义。」
「这给了我们一个起点,来探索LLM是否确实能理解文本,现在我们看到,模型的能力,远不止于盲目地将单词拼接在一起。」
03 打开LLM的大脑
在这项实验中,Jin亲眼目睹了这一进展。
LLM为什么会认为,这些指令指的是这个意思?
他发现,LLM已经开发了自己的内部模拟,来模拟机器人如何响应每条指令而移动。
而随着模型解决难题的能力越来越高,这些概念也就变得越来越准确,这就表明:LM开始理解指令了。
不久之后,LLM就能始终如一地将各部分正确地拼接在一起,形成工作指令。
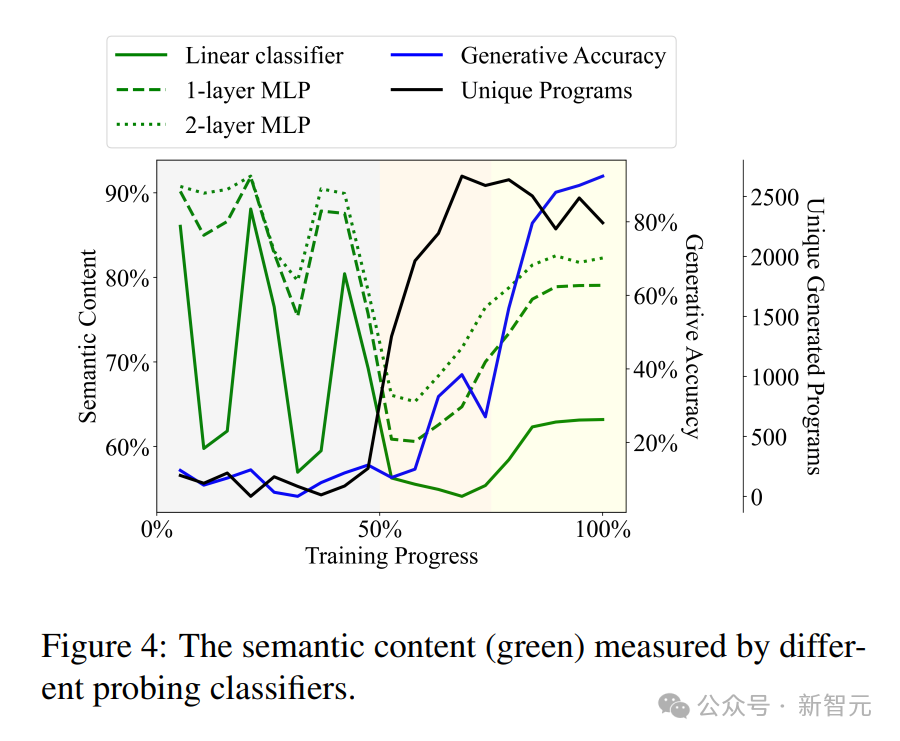
通过不同的探针分类器测量的语义内容(绿色)
1. 思维探针
而为上述发现做出主要贡献的,就是一种「思维探针」。
这是一种介入LLM思维过程的有效工具,论文将它称为「probing」。
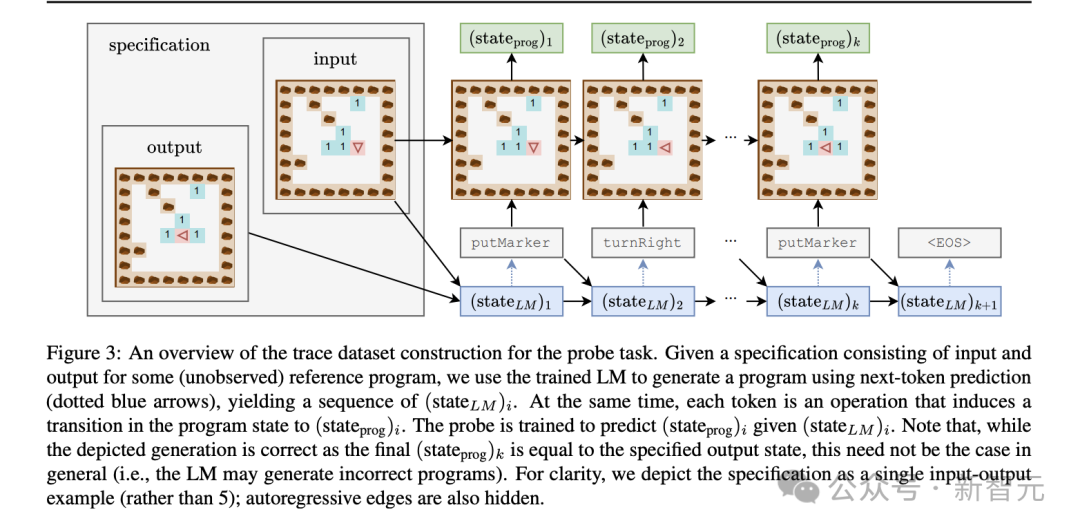
具体而言,LM的状态中包含输入和生成程序的纯语法层面的记录,但probe似乎可以学习理解其中的抽象解释。
实际的实验中,作者首先构建LLM的状态跟踪数据集,再用标准的监督学习方法训练一个小型模型作为探针,比如线性分类器或2层MLP。
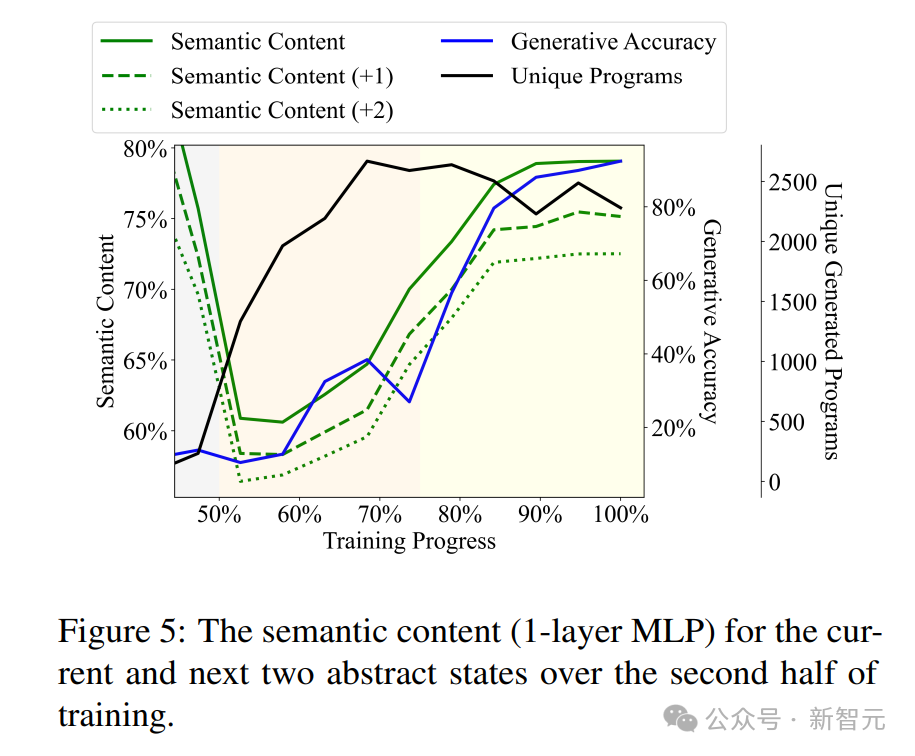
训练后半段当前和接下来两个抽象状态的语义内容(1层MLP)
然而,其中一个重要的问题在于,必须将probe和模型实际的思考过程或生成的指令进行分离。
虽然探针的唯一目的,只是「进入LLM的大脑」,但如果它也为模型做了一些思考,该怎么办呢?
研究者需要确保的是,LLM能够独立于探针理解指令,而不是由探针根据LLM对语法的掌握来推断机器人的动作。
想象一下,有一堆编码LLM思维过程的数据,其中probe的角色就像一名取证分析师。
我们把这堆数据交给了分析师,告诉ta:「这是机器人的动作,试着在这堆数据中,找出机器人是怎么动的。」分析师表示,自己知道这堆数据中的机器人是怎么回事。
但是,假如这堆数据只是对原始指令进行了编码,而分析人员已经想出了一些巧妙的方法来提取指令,并按照指令进行相应的操作呢?
在这种情况下,LLM就根本没有真正了解到这些指令的含义。
为此,研究者特意做了一个巧妙的设计:它们为模型打造了一个「奇异世界」。
在这个世界中,probe的指令含义被反转了,比如「向上」其实意味着「向下」。
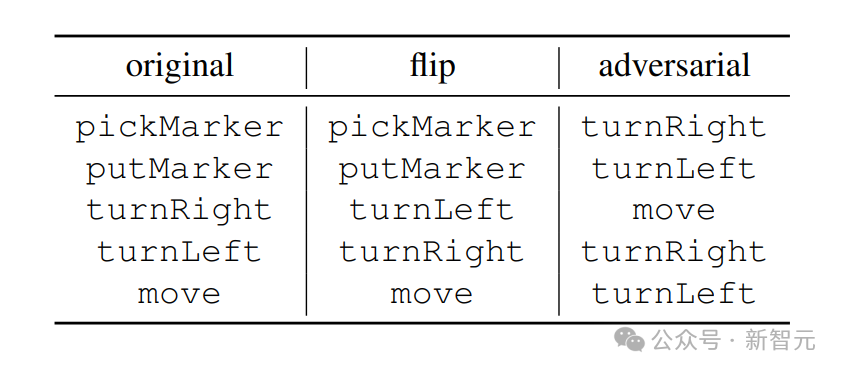
例如,原始语义中的exec(turnRight,·)是将使机器人顺时针旋转90度,而exec adversarial(turnRight,·)是将机器人推进一个空间
这就保证了,probe并不是在「投机取巧」,直接学习理解LLM对指令的编码方式。
一作Jin这样介绍道——
如果探针是将指令翻译成机器人的位置,那么它应该同样能够根据离奇的含义翻译指令。
但如果探头实际上是在语言模型的思维过程中,寻找原始机器人动作的编码,那么它应该很难从原始思维过程中提取出怪诞的机器人动作。
结果发现,探针出现了翻译错误,无法解释具有不同指令含义的语言模型。
这就意味着,原始语义被嵌入了语言模型中,表明LLM能够独立于原始探测分类器,理解所需的指令。
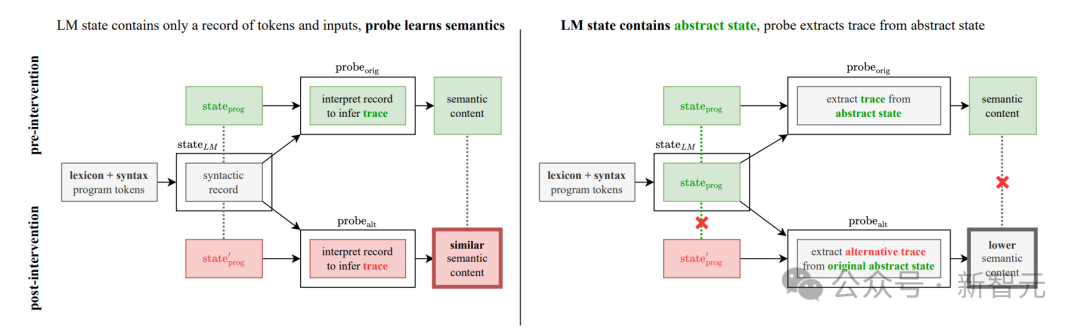
上半部分描述了在干预前,两种情况如何导致测量的高语义内容。下半部分显示了为什么将两个假设分开: 如果LM表示仅包含语法(左下),那么应该可以训练探针alt来学习根据替代状态prog(粗体红色结果)解释记录;然而,如果LM表示编码原始抽象状态(右下),则探测alt需要从原始状态prog中提取替代状态’prog,从而产生较低的语义内容(粗体灰色结果)
2. LLM理解语言,就像孩童一样
有趣的是,Jin发现,LLM对语言的理解是分阶段发展的,就像孩子学习语言时分多个步骤一样。
开始,它会像婴儿一样牙牙学语,说出的话是重复的,而且大多数都难以理解。
然后,LLM会开始获取语法或语言规则,这样,它就能够生成看起来像是真正解决方案的指令了,但此时它们仍然不起作用。
不过,LLM的指令会逐渐进步。
一旦模型获得了意义,它就会像孩子造句一样,开始产生正确执行所要求规范的指令。
结果如图2所示,可以看出LLM对语言的理解大致分为3个阶段,就如同孩童学习语言一样。
- 牙牙学语(babbling,灰色部分):占据整个训练过程约50%,生成高度重复的程序,准确率稳定在10%左右
- 语法习得(syntax acquisition,橙色部分):训练过程的50%~75%,生成结果的多样性急剧增加,句法属性发生显著变化,模型开始对程序的token进行建模,但生成的准确率的提升并不明显
- 语义习得(semantics acquisition,黄色部分):训练过程的75%到结束,多样性几乎不变,但生成准确率大幅增长,表明出现了语义理解
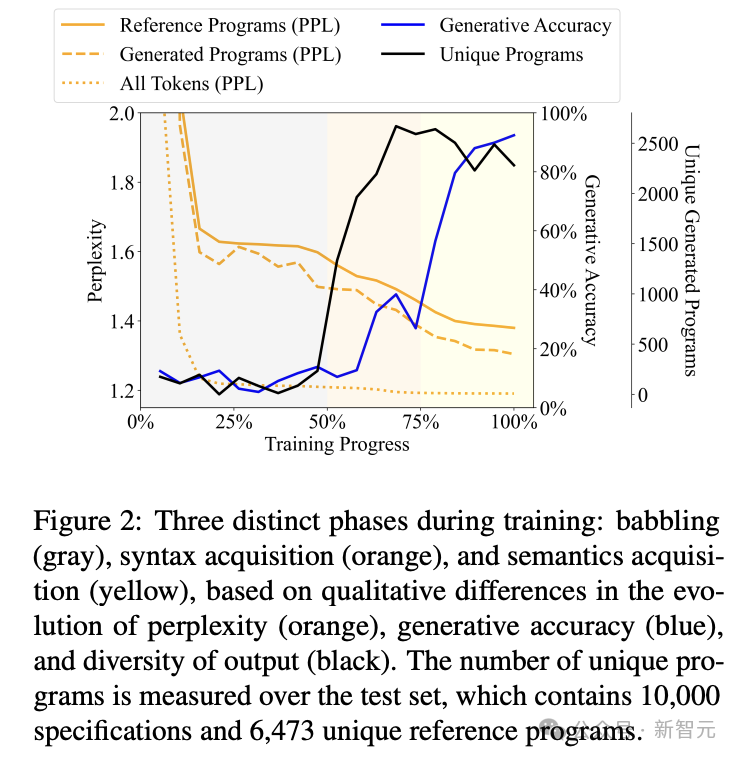
实验使用了三种不同的probe架构作为对比,分别是线性分类器、单层MLP和2层MLP。
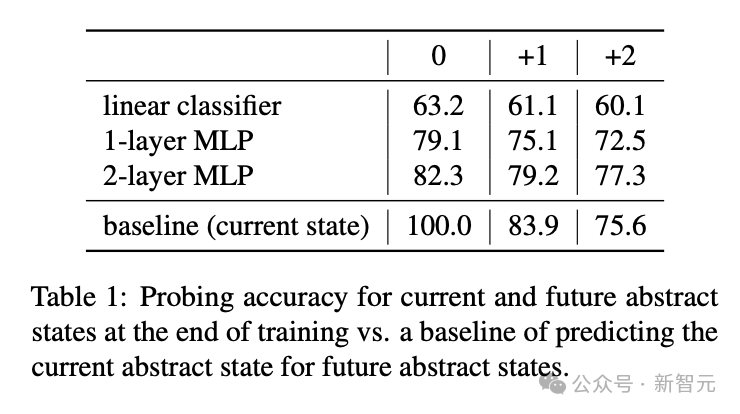
提前2步预测时,2层MLP预测准确率的绝对值高于用当前状态预测的基线模型。或许可以得出这样一种推测:LLM在生成指令前,其思维过程,以及生成指令的「意图」已经存储在模型内部了。
04 LLM = 世界模型?
这项研究解释了LLM如何思考训练数据中每条指令的含义,如何在内部状态中模拟机器人对指令的响应。
这些都直指当前AI研究的一个核心问题——LLM令人惊讶的能力,仅仅是由于大规模的统计相关性,还是对它们现实产生了有意义的理解?
研究表明,LLM开发了一个模拟现实的内部模型,尽管它从未接受过开发该模型的训练。
而且,语言模型还可以进一步加深对语言的理解。
然而,仅靠一篇论文显然不能完全回答这个问题。
作者Jin也承认,这项研究存在一些局限性:他们仅使用了非常简单的编程语言Karel,以及非常简单的probe模型架构。
未来的工作将关注更通用的实验设置,也会充分利用对于LLM「思维过程」的见解来改进训练方式。
本文另一位作者Rinard表示,「一个有趣的悬而未决的问题是,在解决机器人导航问题时,LLM是在用内部现实模型来推理现实吗?」
虽然论文展现的结果可以支持这一结论,但实验并不是为回答这个问题而设计的。
布朗大学计算机科学和语言学系助理教授Ellie Pavlick高度赞扬了这项研究。
她表示,对LLM工作原理的理解,可以让我们对这项技术的内在可能性和局限性有更合理的期望。这项研究正是在受控环境中探索这个问题。
计算机代码像自然语言一样,既有语法又有语义;但与自然语言不同的是,代码的语义更直观,并可以根据实验需要直接控制。
「实验设计很优雅,他们的发现也很乐观,这表明也许LLM可以更深入地了解语言的『含义』。」
05 作者介绍
本文一作Charles Jin是MIT EECS系和CSAIL实验室的在读博士,导师Martin Rinard是本文的另一位作者,他的研究主要关注稳健的机器学习和程序合成。

Jin本科和硕士毕业于耶鲁大学,获得了计算机科学和数学双学位,曾经在Weiss资产管理公司担任分析师,博士期间曾在Google Brain担任研究实习生。
参考资料:
https://the-decoder.com/training-language-models-on-synthetic-programs-hints-at-emergent-world-understanding/
https://news.mit.edu/2024/llms-develop-own-understanding-of-reality-as-language-abilities-improve-0814
作者:新智元"智能+"中国主平台,致力于推动中国从"互联网+"迈向"智能+"
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
