AI PM视角:对话机器人的算法是如何开发的?
编辑导语:对话机器人在我们的日常生活中已经十分常见,那么,你了解对话机器人中的具体算法开发过程吗?对话机器人所使用的算法可分为哪些类别?本篇文章里,作者就对话机器人的算法开发流程进行了整体总结,不妨来看一下。
AI对话机器人目前应用已经很广泛了。智能客服、语音助手、外呼机器人……等等,在日常生活中你可能已经碰到了很多的对话机器人。那对话机器人中,算法开发过程是怎么样的呢?今天笔者从一个AI产品经理的视角,做一个简单的介绍和阐述。
如果你问一个AI算法工程师,如何将算法模型搭建至满足业务需求,上线、给用户使用,算法工程师可能会跟你说一堆的AI技术细节。包括如何选型、算法模型间的技术差异点,等等。往往让非算法技术人员听得云里雾里,觉得很高大上但不明就里。
本文我们不讲AI技术细节,我们从AI PM的视角,来阐述对话机器人的开发过程中,算法扮演了什么角色,承担了什么任务,以及如何影响最终的产出结果的。
对话机器人当中使用的算法,可大致分为:意图识别、实体识别、相似度计算3大类。主要应用于机器人对于客户应答的识别能力。在产品开发过程中,算法的开发流程大致如下:
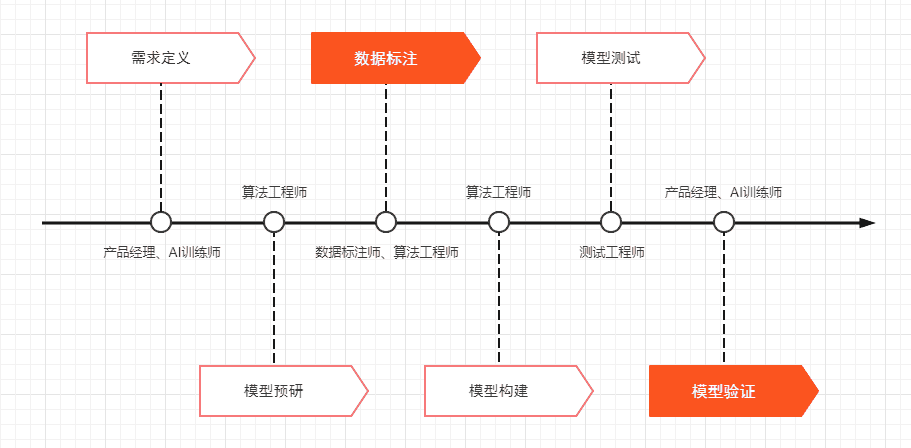
下面我们详细描述每个环节的开发过程与内容。
一、需求定义
主要角色:产品经理、AI训练师
在做算法的开发之前,需要走做产品需求定义。对话机器人中,使用到算法的地方,主要在于语义识别的部分。主要包括:意图识别、实体识别、相似度计算,等等。这里以意图识别为例,做相应的介绍与阐述。
在应用于业务场景的对话机器人当中,通常需要基于该场景,做多个意图的识别。通常来说,意图的数量少则几个,多则几十个不等。而具体需要做多少意图的识别,以及每个意图的定义是什么,意图与意图之间的边界是什么,需要做开发前的需求定义。
一般需求定义是由产品经理或AI训练师来做的。意图是根据业务场景进行切分的,而产品经理作为对话机器人的设计者,本身应对业务场景有深刻的了解。同时,不同于传统的互联网产品经理多是对于产品功能的设计,在对话机器人的【对话】层面的设计,更是体现AI产品经理价值与思路的方面。
所以产品经理需要基于业务,做每个意图的定义,需做到明确、清晰、可验证。这对后续的算法开发至关重要,是开发的方向、验收的标准、产品的价值体现。
除了产品经理,也可由AI训练师做算法需求定义。一般而言,AI训练师的职责是基于客户的对话场景,做对话流程设计、对话知识构建与优化的,AI训练师应是业务场景专家,所以需要做算法需求的定义。
AI训练师与产品经理的区别在于,对话机器人的功能层面是有产品经理负责,而AI训练师主要着重于基于对话场景的对话设计。产品经理也需对AI训练师的工作内容熟悉,以相应地设计可构造优秀对话设计的产品功能。是对话机器人的整体owner。
二、模型预研
主要角色:算法工程师
明确了产品需求,在产品经理/AI训练师做完算法需求的宣讲之后,算法工程师就要根据需求,进行算法模型的预研。具体来说,就是要判断目前积累的数据和沉淀的算法,是否可以达到业务的需求。
预研的目的主要有2点:
算法是目前业内较为优秀的;
算法是可贴合业务需求的。
算法工程师通常会在前期做技术相关的调研,了解目前业内主流算法,包括已被验证的较为优秀的模型,以保证在技术层面至少在业内是持平和领先的。
同时,不同业务要求的算法能力不同。算法工程师需要根据业务特性,选型相应的模型,多备几套方案,以供模型训练时使用。
模型预研的结果,通常需要做一个小型的汇报。目的是同步模型预期选型,让产品经理、AI训练师了解不同的算法模型的优劣势,以及后优化维护的不同特点。同时也收集各方的意见,做最终的模型选择。
模型预研的目的主要是降低风险,即降低模型选错的风险。因为模型是一个从搭建开始,通过数据不断地训练优化的过程。如果模型选型错误,有可能出现后续不管数据如何训练,都无法解决业务问题的情况。所以模型预研对于后续的模型训练,有着重要的意义。
三、数据准备与标注
主要角色:数据标注师、算法工程师
当算法需求确定后,就需要根据定义的需求,进行数据标注。这里通常指的是有监督学习的算法数据标注。数据标注的过程主要包括:数据准备、数据清洗、标注规范制定、试标数据、标注答疑、正式标注。
1)数据准备
在算法团队中,有专门的数据分析员,做相应的对话数据抽取。抽取的数据是数据标注的来源。数据抽取需要根据以下原则:
抽取的数据需包含在行业中具有代表性的数据;如行业标杆客户等。
抽取的数据需尽可能覆盖行业中多样的数据;让数据分布更加均匀,提供覆盖面广的数据分布。
2)数据清洗
抽取了数据之后,数据的结构、质量不一,需要进行数据清洗。通常会筛除吊无效的、质量不佳的数据。数据清洗可能运用的技术手段有:关键词、实体识别、无监督学习等等。目的是可清洗出质量较好的数据以供标注。
3)标注规范制定
在需求定义时,通常会给每个意图做定义,定义会明确意图A是指什么,意图B时指什么。哪些情况属于意图A,哪些情况属于意图B。标注团队首先需要明确每个意图的定义,作为标注的指南。
产品经理/AI训练师会给出一份数据标注的规范。这份规范需要标注团队leader与他们做深入的沟通与理解,以求理解透彻需求,并可实际落地至标注工作中,确保需求落地不偏差。
4)试标数据
制定了标注规范,同时拿到了已清洗的抽取数据后,就进入了试标数据环节。为什么不直接正式标注呢?因为通常标注都是大批量的,若出现标注规范理解不到位,或者标注规范本身指定得有问题,那返工将是很大的人力物力损失。
为了降低这样的风险,通常会在前期先拿一小部分数据进行试标。试标的量根据情况而定,通常控制在1-2天时间内,并需收集标注反馈,注明问题与疑惑。
试标结束后,需要召集标注同学、产品经理、AI训练师、算法工程师,召开问题同步讨论会。会议的目的是确定试标的问题的解决方案,各方达成共识。方可进入下一步骤。
5)正式标注
按照确定的且达成共识的标注规范,标注团队就进入了正式标注阶段。通常标注的数量较多,需要在标注团队中分配任务。
标注完成后,需要有标注审核员进行审核。通常为抽样审核。若不通过需打回重标。
标注结束后,须由标注团队Leader汇总标注结果,提交给算法工程师。
四、模型构建
主要角色:算法工程师
在接收到标注团队的标注数据后,算法工程师就需要拿这些数据,让模型运转起来。模型构建包括3个环节:模型设计、特征工程、模型训练。
1)模型设计
算法工程师会根据业务的需要,以及算法积累,进行模型设计。在这个环节中,产品经理应与算法工程师确定,在当前业务下,这个模型该不该做,我们有没有能力做这个模型。在这个阶段中,最重要的是定义模型目标变量。不同的目标变量,决定了这个模型应用的场景,以及能达到的业务预期。
2)特征工程
选型之后,算法工程师会进行特征工程的工作。整个模型构建可以理解为:从样本数据中提取可以很好描述数据的特征,再利用它们建立出对未知数据有优先预测能力的模型。
所以在模型构建中,特征工程师非常重要的部分。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
而现有的技术能力,如神经网络等算法能力,可通过模型的自主提取特征能力,而取代人工提取特征的过程。方式的不同,在效果上也可能比算法工程师人工提取特征,可能有提高。需具体业务情况具体看。
3)模型训练
算法工程师会根据数据在不同模型的训练结果,做调参工作,以确保模型最终的效果是可满足业务的要求,并可持续优化的。
算法工程师在训练模型时使用的数据为【训练集】,该数据集合需不能与最后模型测试使用的【测试集】重合/有交集,以确保后续测试是客观、不失真的。
五、模型测试
主要角色:测试工程师
模型构建完成后,就需要算法测试工程师介入测试模型的效果。对于算法的测试,衡量的基础指标主要是:P值(精准率)、R值(召回率)和F1值,分别衡量模型预测的准确性、覆盖面和二者的综合能力。
当然,还可以根据业务的不同,有其他的测试验收指标,这边不赘述。
测试的过程,一般会使用脚本自动化测试,以覆盖数据量庞大的测试内容,保证最短时间内测可能多的内容。
测试完成后,测试工程师需出具测试报告。报告的接收方为:算法工程师、产品经理、AI训练师。需确认报告内容。同时,产品经理/AI训练师需评估,模型的效果是否符合预期。若否,则需算法模型重新训练调优,直至达到上线标准为止。
六、模型验证
主要角色:产品经理、AI训练师
模型验证指的是模型上线后的数据观察,以验证模型效果,通常由产品经理/AI训练师,做上线后的跟踪与观察。在上线之后,一般会做算法相关的数据统计,每天实时监测数据的情况。
若有数据异常或不符合预期,通常需要做以下处理。
1)告知算法团队,做数据反馈收集与模型优化
算法的优化过程是较为缓慢的,涉及的流程包括数据重新标注、模型重新训练、重新测试/调优等等。通常周期以“周”为单位。
2)通过规则矫正
业务的问题总是需要及时地处理与反馈的,所以需要一些辅助措施,来响应响应的需求。一旦发现算法模型效果不佳,需要产品经理/AI训练师通过规则矫正的方式,优先做处理。当后续算法优化更新之后,再做原有规则的恢复。
七、结语
对话机器人算法的开发过程,是一个闭环的过程。通过数据的训练、测试、调优,达成相应的业务目标。随着数据的不断反馈,算法模型的效果则会越来越符合业务的需求,是一个循序渐进的过程。本篇文章大致介绍了算法开发的整个流程与脉络,希望可以帮到你。
作者:咖喱鱼丸,5年PM经验,2年AI PM经验
作者 @咖喱鱼蛋egg
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
