为什么说AI现在还不行!
AI最近有点被妖魔化了,很像一个老虎在还没有橘猫大的时候,就已经被天天当成虎力大仙来讨论。
这种普遍的高预期其实是有害的,尤其是当事情本身还需要耐心细致深耕且长跑的时候。资本、品牌可以匹配高预期所对应的增长倍数,业务则不行,业务先天挤出一切泡沫。也正因此最近写了几篇文章都在提应该以一种更加理性的态度来看待AI的进展,甚至设想了一种测试智能程度的方式:图灵测试2.0。这篇文章则是对此前各文章的综合。
一、AIGC的GC(内容生成)是支点也是锁链
显然的AI是一种基础设施,它在重定义计算的内涵和方式。
如果和过去对比,那么过去的编程固化的是程序员的智能,程序员的智能通过程序在限定的边界内处理问题,所以泛IT的崛起伴随着程序员群体的崛起,不管是程序员的人数还是收入。AI则在很大程度上折叠这个中间环节,对话即计算,同时让这种计算变的更加泛化和无边界。从这个角度看,AI的崛起注定伴随着程序员群体的衰落(首先是人数上,但不是说这行当就没了)。
基础设施的最终成败好坏一定在于外部,而不在于它自己的特征比如是否优秀、大模型到底多大等。在过去微内核操作系统一度众望所归,但其实不管Linux还是Windows都不是微内核,纯粹的微内核系统比如Minix却只是教具。
作为基础设施的AI也一样,要想成功那就必须走出单纯内容生成工具的范畴,变成一种通用计算平台,为各种场合提供新计算方式。
过去不管Windows还是Linux都提供了这种通用性,从取款机到机场的大屏,再到家里的机顶盒,甚至有点智能的闹钟都是他们在提供基础的计算能力。(有时候这些系统会崩溃,让人惊讶的是不是崩溃而是看到好多系统其实是XP的)。
AI打破内容生成工具的界限后,就会变成这个新的计算底座(通用人工智能的通用对应的就是这个情境)。也只有成为这种通用的计算底座后,AI才真正迎来自己的星辰大海。
在现在的内容生成式AI和这种通用计算底座之间现在横亘着一道无形的基因锁链一样的界限。
这个基因锁链就是内容生成工具的边界。
AIGC的GC(内容生成)是支点也是锁链。
在工具范畴里,这次AI其实已经做的足够好,就是池子太小,如果就做这个会憋死所有人。
注1:真对大模型下新计算模式的技术性感兴趣可以扫文末二维码瞄瞄,这个课程是我一哥们连同知乎做的,比较正经不扯淡的课程。卓然早年做三角兽的时候我们就颇多来往,我们还一起在GPT2的时候就跟过这个模型,水平我还是有谱的,但课程感觉还是有点难,也收费,自己酌情。
注2:关于AI的计算模式参见《开源大模型LLaMA 2会扮演类似Android的角色么?》
二、GC工具池子太小做的人太多,会憋死所有人
我们拿个具体例子来看下为什么说这个池子太小。
起点中文网上有个网文作家笔名叫做我吃西红柿,这个1987年的同学本来是苏州大学数学专业的一名大学生,按正常轨迹毕业后大概率不能继续做数学相关的工作,那时候就业很可能会做程序员等相关方向。但他没走寻常路,在大学期间开始了网文创作,取得了很好的成绩,2012年11月以2100万的版税收入高居“中国网络作家富豪榜”第2位。
假设他一年写一部小说3百万字,放大点算1000万token。现在这部分自己不写了,都用AI。随便选个国内某大模型的报价做参照,按1500元/5000万token,那这部分给人工智能公司可以创造的收入是300块,在2100万收入里面占十万分之一多一点。再放大下,如果有10000个我吃西红柿,那AIGC在网文行业一共可以赚300万。这还不够一个团队一年的工资,特别高端人才的情况,这甚至不够一个人的。
如果大模型只做内容生成,创造的价值和行业现有价值大致就是这么个比例。
而已经很多人冲进来了,这就很像做一个很小的池子里养了一堆鲨鱼,饿极了就只能拼命内卷互相残杀,然后大概率是都死掉了,一条不剩。
如果AI不能在GC之上再进一步,就必然是这个结局:带着快乐期望的高度内卷。
这种内卷对AI整体来讲是彻底的负反馈和死路一条
每个人期望的都是新式通用计算平台和应用,实际上却只是内容生成工具,创造一点点新价值。长时间怎么可能不负反馈呢!
那AI怎么才能走出来呢?答案是需要通过图灵测试2.0。
注3:关于AI的商业模式的汇总参见《AI能赚到钱了么?》
三、图灵测试2.0
原始的图灵测试这样:
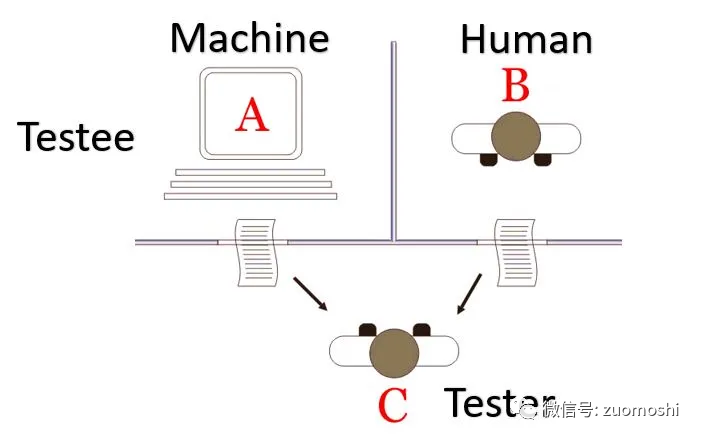
这是一个纯粹的智能测试,本质是追求在封闭系统里面的逻辑自洽性。
现在我们把Agent类似的概念加入这个测试:
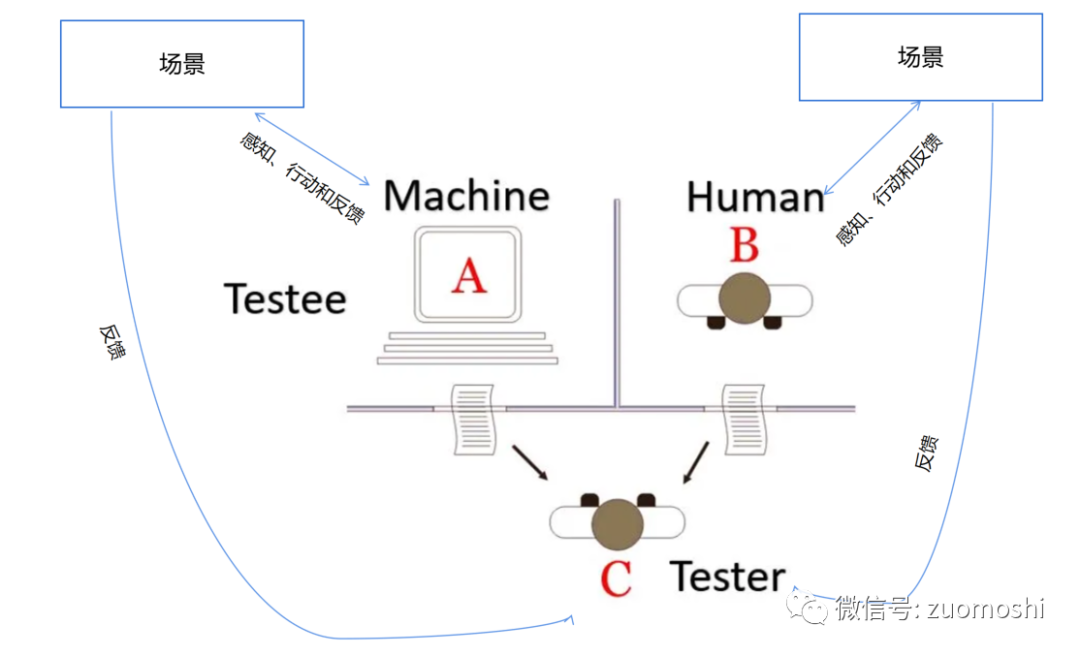
这就是图灵测试2.0。和1.0相比核心差异是什么呢?
去幻觉,有边界。
1.0是一个凌空的系统,具有合理性的幻觉其实有助于通过测试,但2.0不行,测试者同时从真实场景和被测试者接受反馈;其次就是测试边界的限定要求更高的智能深度。这很像赵括学兵法能说的天花乱坠,但不一定能打仗;会打仗不一定兵法上什么都懂,但水站、陆战、马站好歹得会一个。
能否打破内容生成的边界变成各种场合都用的新式通用计算平台,关键取决于智能是否能跟上。而智能是否能跟上取决于是否在一个个场景下能通过图灵测试2.0。
Linux和Windows等输出智能的方式虽然老土,并且但他们提供了足够的确定性,他们加上程序员达成了过去所谓的软件吞噬世界。这是一种Good Enough的计算模式,但现在的AI还不是。
现在大模型等确实提供了更好的计算形式,但关键是它的不智能(过不了图灵测试2.0)导致不能替换过去系统加程序员的组合。智能的边界限制了应用的边界。
注4:图灵测试2.0的展开参见《AI的进展不是太快,而是太慢》
四、通过图灵测试2.0后会怎么样呢?
那时候不单客服、外呼会基于AI进行构建,每个现有应用(Office等已经开始、游戏大概率会爆真正的多维叙事高度随机,主打智能的新式游戏)、广告屏、智能音箱、电视甚至手机都会重整。因为基本计算范式变了,它的交互载体必然发生变化,这个变化的幅度可能大于PC互联网到移动互联网的更迭幅度。从这个角度可以进机器人一定是下个通用计算平台型产品。
极端讲除了极其机械的那类产品比如霓虹灯,计算器,别的都会变。
这种视角可以描述成为场景的智能密度,显然的拧螺丝的智能密度度低于算数学题。
智能密度越高的场景其计算方式和对应的产品越会发生变化,因为价值更大。然后再匹配上从数字到物理的视角,有无幻觉的视角。以图灵测试2.0为根基,加上这三个视角共同构成也约束了未来智能应用的发展路线。
这种路线的实现方式的具体体现就是我们经常说的Agent。
如果我们把智能的密度(原点是0),物理的程度(原点是0,代表纯粹数字应用),幻觉有害度(原点是0,代表幻觉无害)画一个坐标系,并把这个图放在正中心位置排列,那在下面这个示意图里面,最头部的是什么呢?
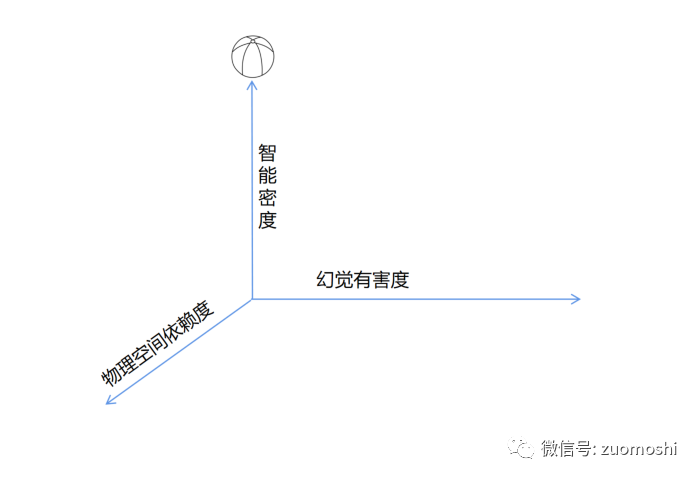
答案很可能是:游戏,多维叙事类的游戏。
注5:大模型的落地应用的形式参见《AI Agent:大模型与场景间的价值之桥,但不适合当纯技术看》
五、Agent不是大模型的延伸而是新物种
通过图灵测试2.0才能有真的agent。但需要注意的是agent不是大模型的延伸,而是一种新物种。做汽车发动机和做汽车怎么都不是一回事,虽然汽车没发动机根本跑不了。
只有Agent才能启动AI的浪潮,而能启动AI浪潮的Agent还不是别的简单融合AI特征的应用,而是智能原生型Agent。这种情况下,Agent不单是输送智能到具体场景的管道。
智能原生应用的构图:
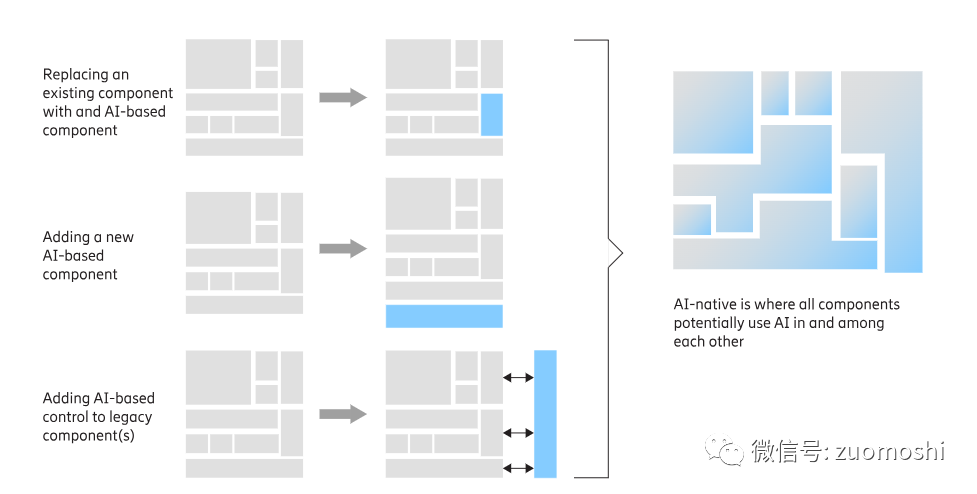
在这种思维模式,AI原生注定会被放到一个结构的中心位置:
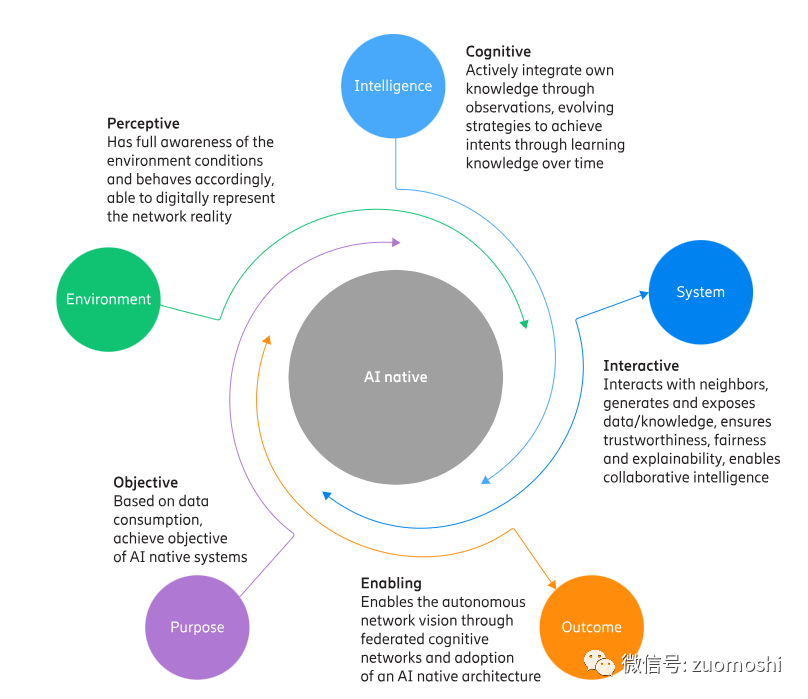
https://www.ericsson.com/en/reports-and-papers/white-papers/ai-native
在这里大模型等扮演的是引擎的模式,通过不了图灵测试2.0,那么智能原生应用会很像用骡子拉的汽车。
通过了这个测试,再补上上面提到的感知、目标、反馈、使能环节,Agent才能真正成为新式通用计算的实现载体。只有通过这种测试才能一步步的把引擎换成蒸汽机、内燃机、涡轮增压等。Agent范围的扩大注定也就是智能一步步提高的过程。
注6:智能原生相关展开参见《从手机App到AI原生应用》
六、现在能不能过图灵测试2.0呢?
答案是过不了。所以才说现在的AI还不行。
我们可以调低标准,让标准更垂直,只要范围收缩的足够窄,那所有测试都能过,但那没意义。我们看下前面这个具体例子,就能理解上面整个逻辑链条:过不了图灵测试2.0,成为不了智能原生应用的基座,只是憋在了AIGC这样一个小池子里,所以现在的AI还不行。
假如你想开播了,但又不想自己上,而是希望做一个自己的数字代理或者说分身,那这个数字代理人真想取得效果都要搞定什么呢?(取得效果是指有人愿意看,有粉丝等)
首先是最基础的产研部分:先打造自己的外壳,也就是形象要像那么回事,然后给它匹配上看、听、说、想的能力(计算机的输入输出、存储和CPU…)。这里面看、听、说基本上是用过去十年反复打磨的技术,比如图像识别、语言识别、语音合成等,想的部分则要基于大模型了,它负责综合各种输入产生自己的输出。当程序员把这些都连接起来,基本上就有了一个数字分身,它能基于观众的各种输入做点反馈。
但产品做到这里基本上完成了手眼的部分,脑的部分属于有了,但还不好使。这时候即使导入了最好的大模型,它也还是一个很傻的Bot,别说取得效果,基本上就没人会看完任何一个直播段落。这时候在单纯的单点技术上使劲内卷是没前途的(包括大模型),那样搞不定粉丝也搞不定留存,回报大致为0。
改善起来第一步肯定是希望能加入人格特征,让它的性格特征和你更像,比如是不是对人友善、表达是不是犀利,也要社会一点:会说话能联络感情等。
这时候要尽可能记住过去和某个人说过什么。这部分不纯粹是技术,但技术相关性还是很高,通常需要找找过去干过的老司机,纯粹的干prompt估计搞不定(注1说的那课其实就是这个价值)。
这步是个槛,搞定了算通过图灵测试1.0,别人分不出到底是不是你了,但现在其实没法彻底搞定这事,无边界闲聊还行,限定到人格特征上表现就没想的那么好。搞不定的情况下,会出现什么结果呢?会看着有点智能有点像你的一个人,在那里叨叨,但毫无特色和趣味性。能不能吸引到粉丝呢?这要看你到底播什么了。我估计播动物世界没准行,娱乐估计够呛。这是下面的话题,关键因素进一步从技术向产品偏移。
通过图灵测试1.0的智能产品已经有用了,在这之前是纯粹工具,在这之后就有点Agent的意思,但价值还没想的那么大。
通过图灵测试1.0这样的一个数字分身有什么用呢?
它优点是信息吞吐量大,不知疲惫,人模人样;坏处是智能还是不够,做不出很好的性格、才艺、出众的观点、有趣的随机应变等。那适合做什么事呢?它适合做内容本身有趣,主播是配角的事。
那些事是这类的呢?比如播动物世界、讲故事、播新闻,偶尔穿插点互动。这本质是一个更好用了的智能音箱。
这是在干什么呢?是在缩减场景对智能的需求。智能供给不足就只能降级。
那理想状况是什么样呢?
理想状况是这个数字分身还要能接入实时的热点,动态的生成要输出的内容,比如图片、视频,然后做主播。这种热点要匹配大家的关注点,要新颖,要匹配平台的规则,不单是正向的规则,还要把握好反向的尺度,否则会被抬走或者封杀。
这部分会衍生非常多的细节工作,比如那个主题是现在主推的,这得跟着平台走才行,否则你权重不好它不推你,也白搭。
对平台这是个智能对智能的过程,对受众这是个综合分析的过程,对创作这是个创意创新的过程。这事能干了,算是通过图灵测试2.0,一旦过了至少可以和人类二分天下。过不了,比如不管内容的时效或者不管平台热点的捕捉,就都还是干半截活!是智能供给不足。这部分如果成功,那基本上可以有粉丝了。到这里也才算是脑子长成,并且培养出了自己的风格。
假设这能做到了,就完了么?
也还没有。这些都搞完了,主要解决了硅基智能和硅基智能的关系,相当于能够比较匹配平台的规则和现实的热点。
郭德纲捧人的主要方法就是反复提这个人。你做主播如果有人拉扯显然效果会更好。那和谁合作,怎么合作还是需要人去做。把这个场景全覆盖了,才算真正的你的代理。
上面说的可以总结成一张和自动驾驶类比的图:
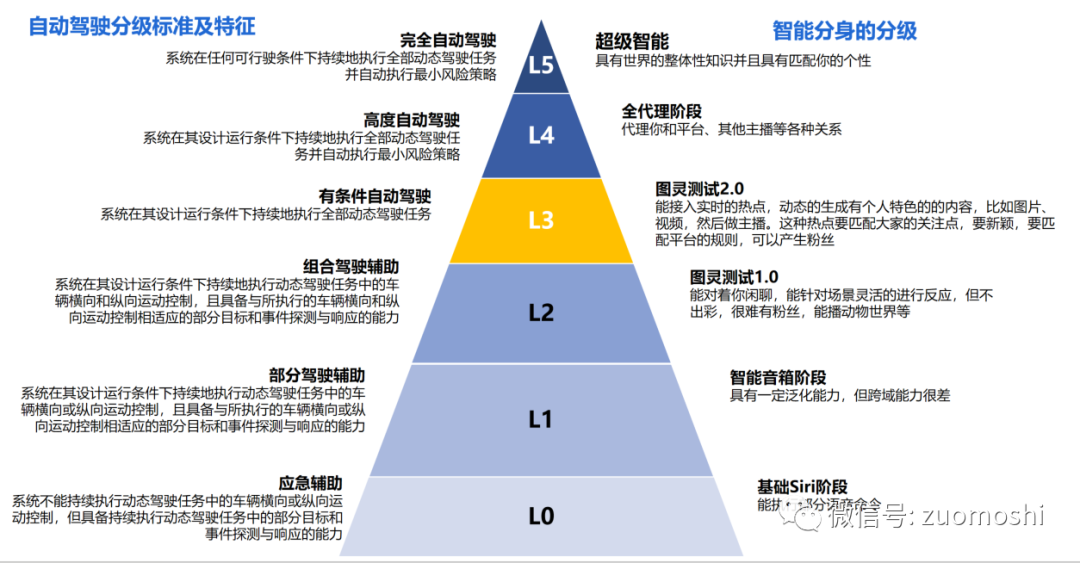
从这个视角看现在能完成的百分之十不到。更何况这只是一个相对简单的C端场景,B端场景比这个要复杂的多。
注7:这部分更详细的描述参见《举个例子:智能原生应用的脑、手、意》
小结
AI这行当一直是这么个状态,一旦有一点突破,大家就欢欣鼓舞,然后预期就上去了,马上能匹配这种预期的是什么呢?是资本和营销热度。所以很快就会变的满地都是以及看到非常多的高估值。
但业务和这种预期的匹配则要难的多,但这里才是行业的第一性。不同行业的这几者间的速度差是不一样的,互联网的匹配速度其实最快,AI的匹配速度很可能是更像传统软件,次于互联网,但快于消费产品。
作者
琢磨事,微信公众号:琢磨事。声智科技副总裁。著有《终极复制:人工智能将如何推动社会巨变》、《完美软件开发:方法与逻辑》、《互联网+时代的7个引爆点》等书。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
