Kimi Chat如何一步步破圈?带给AI的启示
Take Away:
1. Kimi爆火链路分析:非一日之功
2. 为什么是Kimi:(人才*长文本*用户用例)
3. 其他大模型怎么办:答案在vision和用户的结合
01 一步步还原Kimi爆火链路
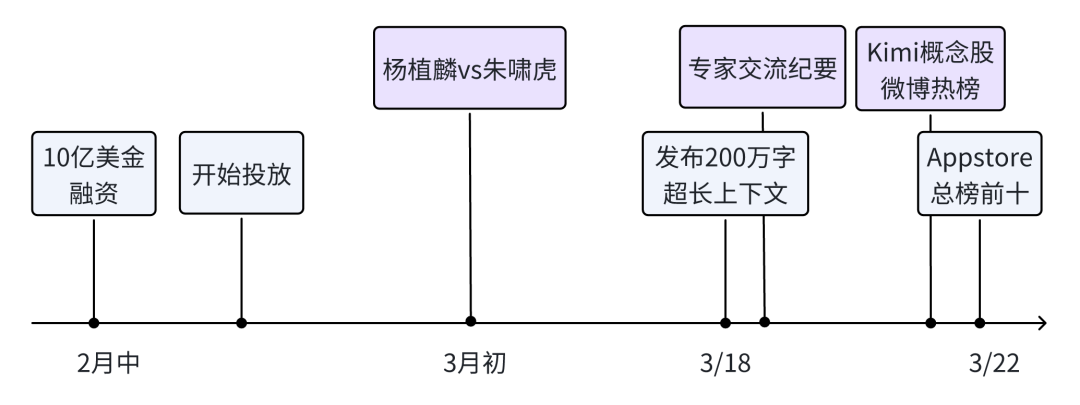
事情还是比较有规律的发酵,最早是2月份中,被爆完成了一笔8-10亿美金的融资,估值达到25亿美金。

在即刻上大家除了恭喜,还有很深的疑虑:为何稀释这么多股份?
有了弹药后,月之暗面开始发力,大力招聘投放类岗位:
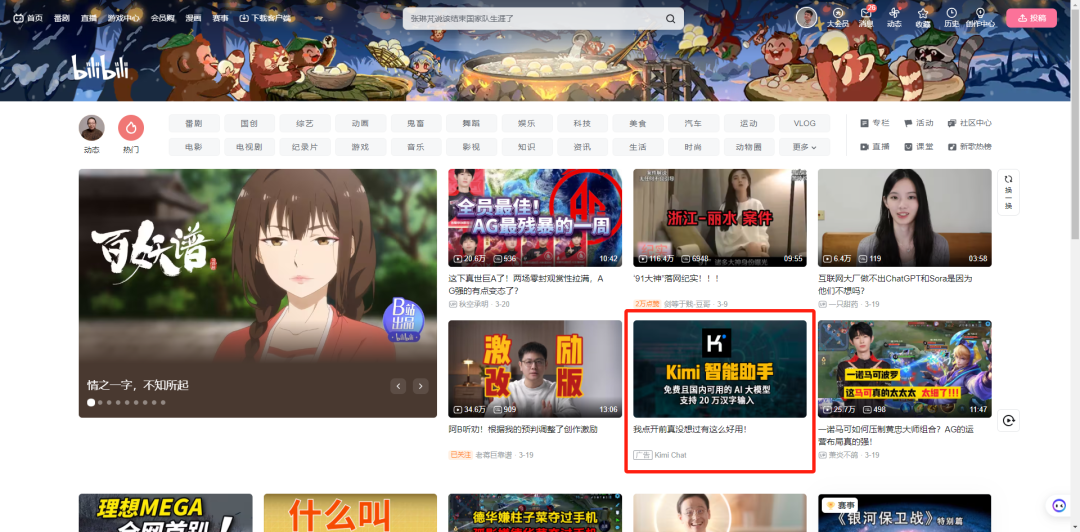
随后我们就看到了Kimi在B站的海量投放:
我们的疑惑继续:一款ToC产品,完全没有商业收入,就做海量投放,留存如何,是不是有价值?当然,对于跑马圈地很熟悉的国内玩家来说,这又是一个再熟悉不过的操作,结果是什么呢:
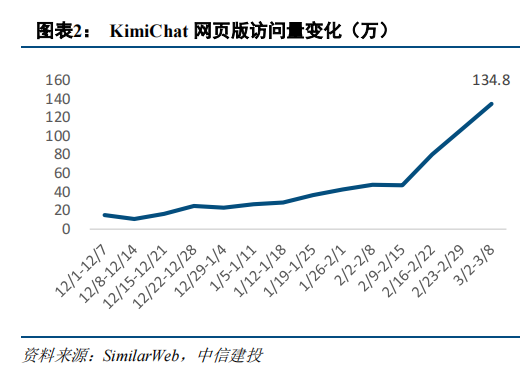
流量暴涨!
3月1日,腾讯科技发布了一篇浪漫的理想主义文章,把杨植麟和月之暗面给捧到了很高的位置:

后面又连续出了两篇,特别是朱啸虎和杨植麟两人对于现实和理想的碰撞,更是把热度拉满!
还没完,本周一,Kimi智能助手的公司Moonshot AI公众号发布了一篇文章:《Longer than long,Kimi 智能助手启动 200 万字无损上下文内测》,截止今天,阅读量是3.5万。

要知道,去年10月初,Kimi用支持20万字的超长窗口,就已经震惊了国内。要知道在当时,Kimi也算是全球支持最长的大模型:
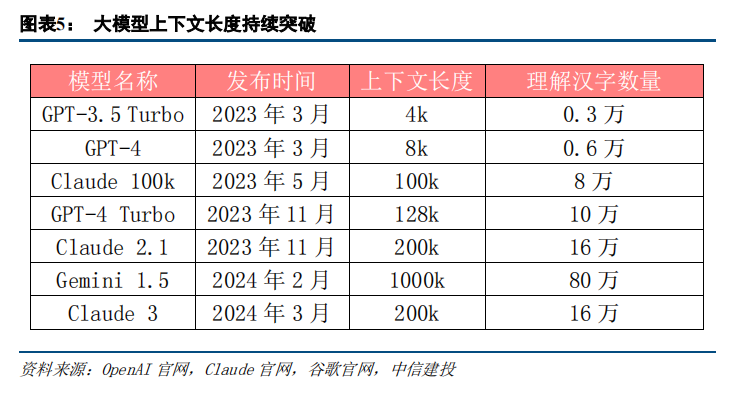
原本在今年2月份,Google的Gemini 1.5发布了支持1000k的上下文长度,已经足够让人震撼了,没想到Kimi继续用10x的增长来宣布自己的优势!
200万,相当于2000k以上的长度,目前是世界第一。
好巧不巧,一篇《Kimi专家交流纪要》在20日出炉,在各个圈子疯传,光公众号文章就有2万 的阅读量。
因流量突然剧增,3月21日,陆续有用户在社交平台上表示,月之暗面旗下大模型应用Kimi智能助手的APP和小程序均无法正常使用。截至记者发稿时,相关页面和功能已经恢复正常。
此前,月之暗面公司发布情况说明称:从2024年3月20日 9:30:00开始,观测到Kimi的系统流量持续异常增高,流量增加的趋势远超公司对资源的预期规划。


进一步的传播,原本就不理智的A股,引起了不理智的疯涨:

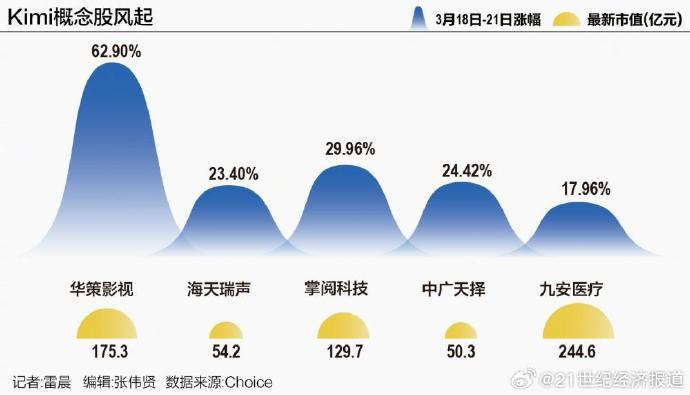
大量股民的讨论,上了微博热搜:
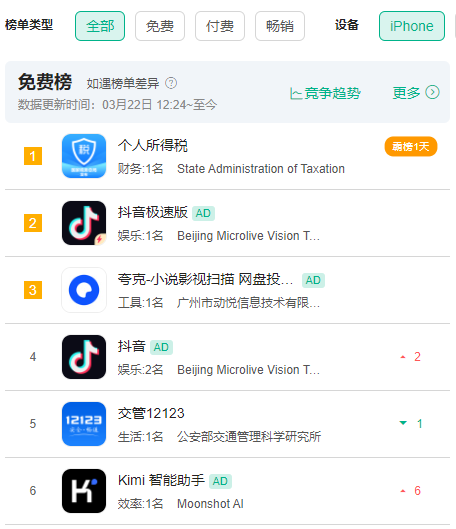
接着Appstore免费榜单冲进前十:
OK,所以这里面一环扣一环,产品逐步破圈,叠加上最近的技术更新爆点,被券商挖掘出来,引入到了大A股,亿万股民看着Kimi概念股,嗨了!全民共舞~
02 为什么是Kimi?
抛开阴谋论,Kimi走到今天,仔细思考,确实是有这么几个要素构成了产品层面的成功,最后获得了出圈的结果。
第一 超高密度的人才
腾讯新闻《潜望》:你似乎一直在思考组织,在团队构建上是怎么做的?
杨植麟:招人思路发生过一些变化。世界上 AGI 人才非常有限,有经验的人很少。我们最早期的画像是,专注找对口的 genius(天才)。这个证明非常成功。之前有对模型动手术的能力,有训练超大规模模型直接的经验,就可以很快做出来。包括 Kimi 发布,资本效率和组织效率其实很高。
腾讯新闻《潜望》:花了多少钱?
杨植麟:一个挺小的数,相比很多其他花费,是花小钱办大事。我们很长一段时间是 30-40 人的状态。现在 80 人。我们追求人才密度。
人才画像后来发生了变化。最早期招 genius,认为他的上限高,公司上限是由人的上限决定的。但后面我们补齐了更多维度的人——产品运营侧的人,leader 型的人,能把事情做到极致的人。现在是一个更完整、有韧性、能打仗的团队。
除了产品人才以外,月之暗面最核心的竞争优势,是技术领域极高的人才密度,「创始团队核心成员参与了 Google Gemini、Bard、盘古 NLP、悟道等多个大模型研发,多项核心技术被 Google PaLM、Meta LLaMa 和 Stable Diffusion 等主流模型采用。
纵览全球,AI确实是一个高智力密度的产业,三个臭皮匠的故事并不生效。
第二 对长文本的判断
去年10月份,在Founder Park的文章《融资超2亿美元,月之暗面发布超长文本模型产品,目标C端Super-App》中,就提出了杨植麟对长文本的思考:
纵观计算机发展的历史,内存拓展是必然趋势,杨植麟认为,上下文长度就是大模型的「内存」,它是决定大模型应用最关键的两个因素(参数量和上下文)之一。
3月初腾讯新闻的访谈里,又再次提到了长文本。
腾讯新闻《潜望》:为什么长文本是登月第一步?
杨植麟:它很本质。它是新的计算机内存。
可以看到,这确实是领先于市场的思考。
说回我自己的使用场景,过去我主要用Claude,因为免费、支持上传文档,100k,GPT太短了,完全不够用,到后面Kimi出来后,慢慢的就迁移过来了,同样继承了Claude的优点-,-还不用翻墙,你说呢。
长文本在早期的市场竞争中,确实是很关键的一步,彼时国内大多数还是32k长度(是吧?),这个时候上来一个200k的,简直不要太爽,再加上Kimi文本输出的质量还不错,就开始获得了更多用户的认可。
我们先来看看用户对于Kimi的使用反馈,在即刻,@junyu发了一个提问贴:
你们为啥用 Kimi 而不是别的类 ChatGPT 产品?
看了下答复,有几个点:
- 支持超长文
- 响应速度快
- 可以直接读链接
- 小程序访问方便
- 输出效果不错
第三 用户用例的反馈
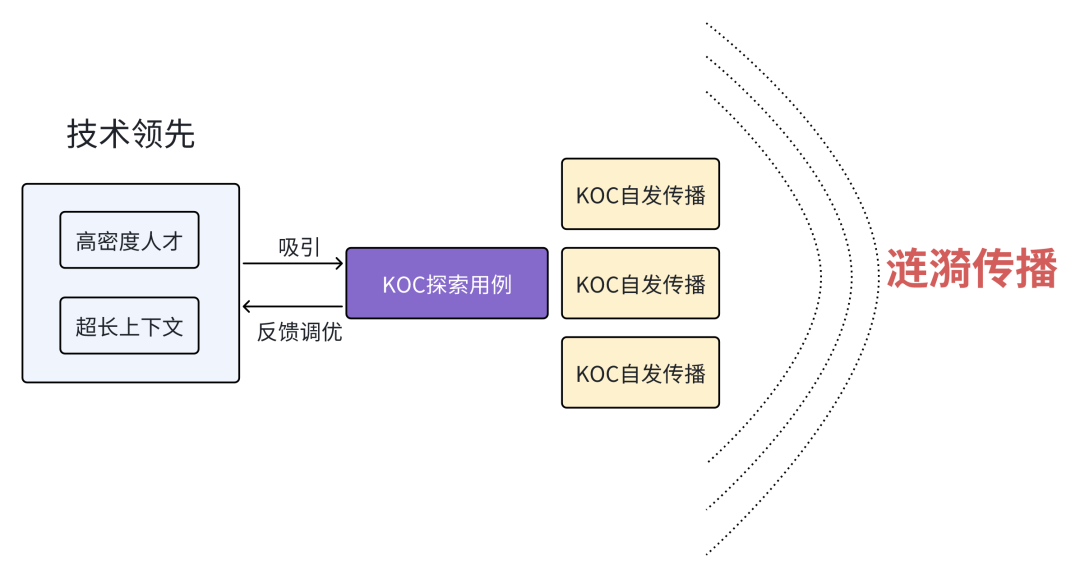
按照我的理解,Kimi是综合层面在用户使用上得到了整体的胜出,再加上有很强的记忆点:超长上下文,早期积累下来的口碑得到持续滚动,从而获得了更多用户基于长文本的探索:
各个KOC得到肯定鼓励后,愈发愿意传播,形成了涟漪效应:
今天用户帮我们发现了很多从没考虑过的场景。他拿这个筛选简历,这是我们设计产品时没想过的,但它天然work。用户的输入反过来让模型变得更好。Midjourney为什么效果好?它在用户端做了scaling——user scaling和model scaling需要同时做。反过来,你如果只关注应用,不关注模型能力迭代,不关注AGI,贡献也有限。
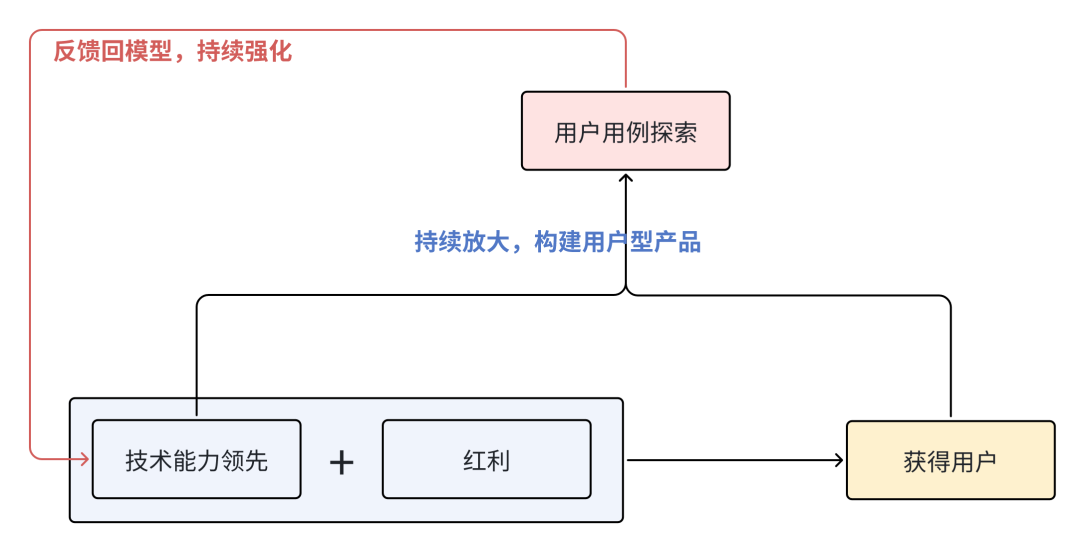
从这里,我们可以理解AI时代,基于单点能力突出,获得的红利,再返回来获得用户用例,继续去强化模型能力,重复这一过程的滚雪球价值:
03 其他大模型怎么办?
跟随策略肯定是很难有效的,我现在倒是更理解了杨植麟所说的Tech Vision:
腾讯新闻《潜望》:除了资本和人,你在 2023 年还做了哪些关键决策?
杨植麟:要做什么事。这是我们这类公司的优势——在最高层面的决策有技术 vision(愿景)。
上面说的技术能力领先,长文本是一个很显著的要素,除此之外,还会有别的么?肯定有的:
当然马拉松刚开始,接下来会有更多差异化,这需要你提前预判到底什么是「成立的非共识」。
Sora出来,跟进?长文本有了,我们也去冲?好像都不对。
目前看到的大额融资:月之暗面、MiniMax、智谱,都各有各的活法,对于后面的几家,就提出了很高的挑战了!
尽管我们之前详细研究过TPF:
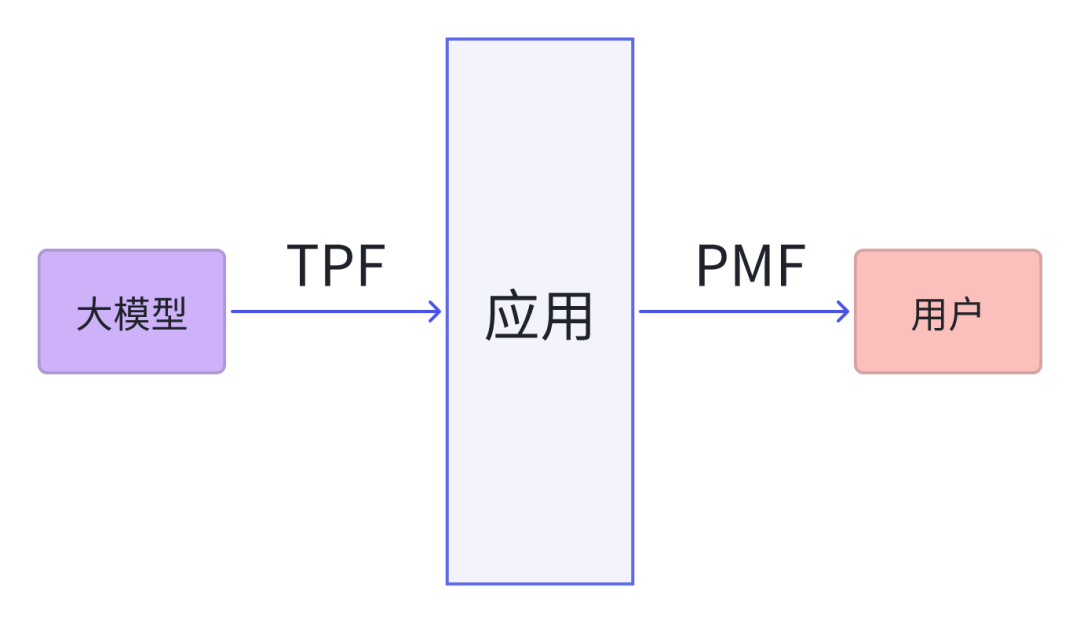
穿透下来,大模型打出什么差异化亮点,仍然需要深度的理解用户,从用户侧获得洞察,反过来对模型能力做针对性的提高:

把下面这条链路构建起来,仍然是产品经理的超级价值点!
大模型公司既要警惕陷入局部用户的无限调优中,又要放开思路深入用户,还蛮有意思的!
焦虑没有意义,专注找到自己的方向,更加靠近用户一些,绝望中寻找希望,才是其他大模型的出路。
总结
其实Kimi并不是无敌的,比如200k大海捞针经常丢失重要信息,幻觉依然很严重,用着用着也老会说无法联网了。
但它是更加toC的,我们看文心一言和智谱清言等,加入了各种智能体,为何仍然增长无力呢?这个答案的背后或许隐藏着SuperApp的可能性:)
周五了,大家周末愉快:)
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
