RAG-大模型的知识库「外挂」|兼备成本与效益的行业解决方案
Hi,见字如面。
今天我们来聊一聊RAG-检索增强生成这项技术应用。
想象一下,如果大语言模型(LLM)能够接入一个实时更新的知识库,那它会给我们带来一个什么样的体验?
- 当它与医疗数据库结合时,LLM成为医生和护士的AI伙伴,可随时提供精准的诊断建议和患者的护理方案。
- 当它与市场数据结合时,LLM成为金融分析师的虚拟助理,辅助分析市场走势,并提出明智的投资策略。
- 当它与企业知识库结合时,LLM转变为企业的全方位AI助理,从自动化客户服务到员工培训,再到销售策略和市场洞察,助力企业实现智能化运营。
检索增强生成(RAG,Retrieval-Augmented Generation);
这项技术已经被视为大语言模型应用的核心技术之一,它有效地解决了大语言模型中误导性的输出问题、缺乏知识时效性的问题、以及特定领域专业知识不足的问题。
一、什么是RAG?
简单的说RAG就是给大语言模型外挂一个“实时可更新的知识库”,是一种使用外部数据来提高LLM的准确性和可靠性的技术。
要实现RAG的过程,一共可分为三步:
第一步:准备数据
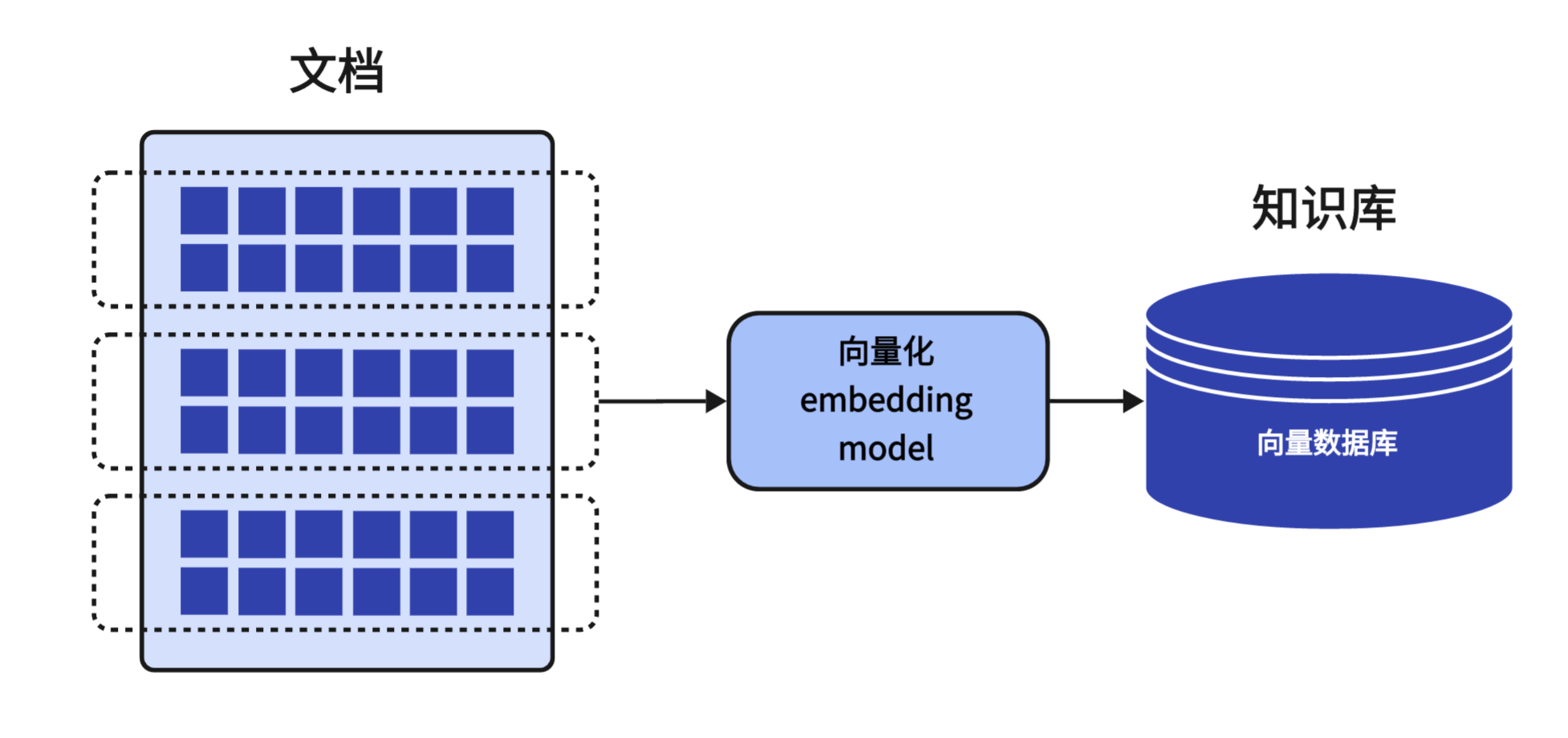
我们需要准备好知识库中所需要的文档数据,并且将这些数据上传至知识库中。
此时,上传的数据会由「嵌入模型-Embedding Model」进行向量化的处理,这个过程就是将文本内容转化为计算机理解的语言。
转换后,再存储在一个特定的数据库中,这个数据库通常被称之为「向量数据库-Vector Database」。
第二步:将用户输入的信息与知识库的文档进行匹配
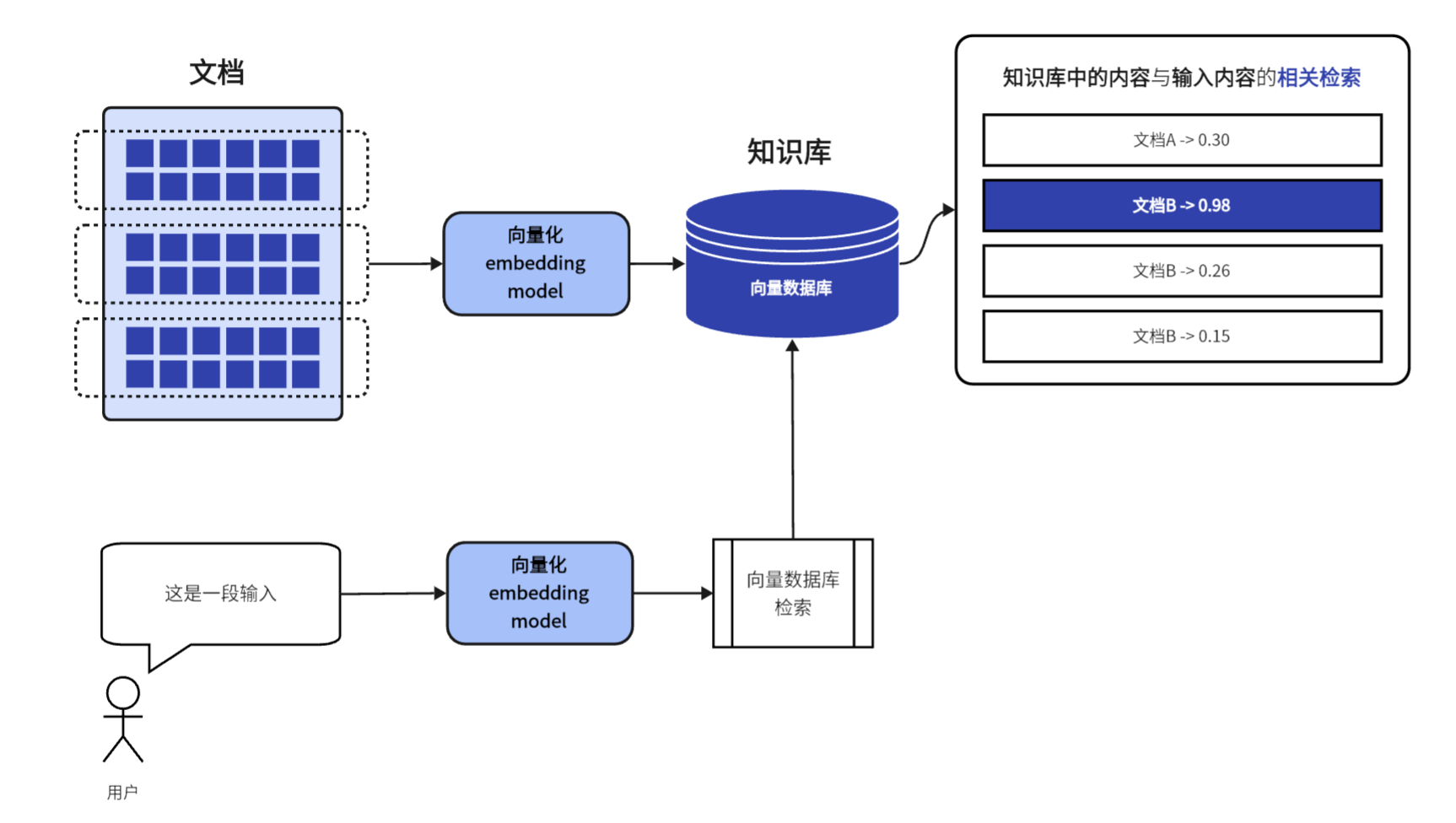
用户输入一段文本时,这段文本也会被「嵌入模型」进行向量化处理;
然后计算机将用户输入的内容与向量数据库中的内容进行【相似匹配】,从而找到数据库中最相关的文档内容。
在匹配的过程中有一些优化的技术方式,常见的就是ANN,近似最邻近搜索(Approximate Nearest Neighbor, ANN)。
第三步:汇总信息与生成内容
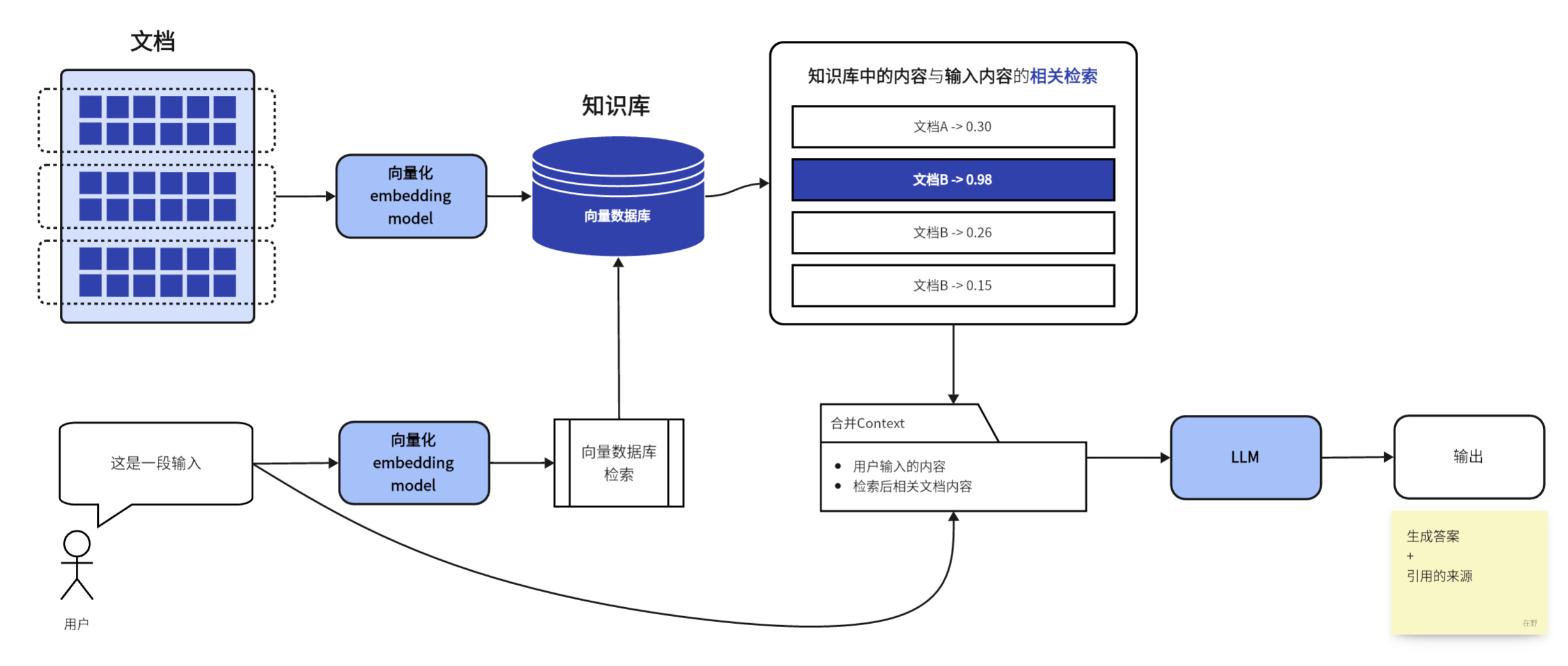
将匹配到的信息与用户输入的信息结合(这里涉及到一些预处理的过程,比如让模型能够区分哪些是用户输入的信息,哪些是检索到的知识);再将处理后的信息输入给模型生成一个综合回答。
输出的内容不仅包括文本,还附有相关的引用来源。
二、RAG的优势与局限
现在,你应该对RAG的核心工作原理有了清晰地理解;接下来,让我们进一步探讨RAG的优势与局限。
优势方面,可以总结为以下四大优势:
1. 成本低且效益高
由于RAG技术是通过检索现有的知识库来增强模型的回复质量,因此无需对模型(LLM)进行重新训练,就能够提升模型的输出质量。
2. 增强模型输出的可信度
RAG生成的回答可以附带对应的引用来源,用户可以轻松验证模型回答的准确性,从而增加对模型输出的信任。
3. 增强模型输出的准确性和专业性
通过检索知识库中的信息,可以有效减少模型作出错误判断的可能性,并利用特定的知识和提示(Prompt),可以满足不同行业或用户的定制需求。
4. 始终访问最新的数据
知识库可以实时更新,便于模型调用最新的信息和数据。这对于需要实时获取最新信息的领域尤为重要,如教育、医疗和金融领域。
5. 最后敲个黑板
RAG技术虽然有以上显著的优势,但它不是万能的,只是锦上添花的一种手段,因为它主要是优化了模型的输入过程,通过丰富输入信息的方式,来增强模型的输出质量。
但这项技术并不改变模型本身的推理能力,不会改变模型任何的参数。
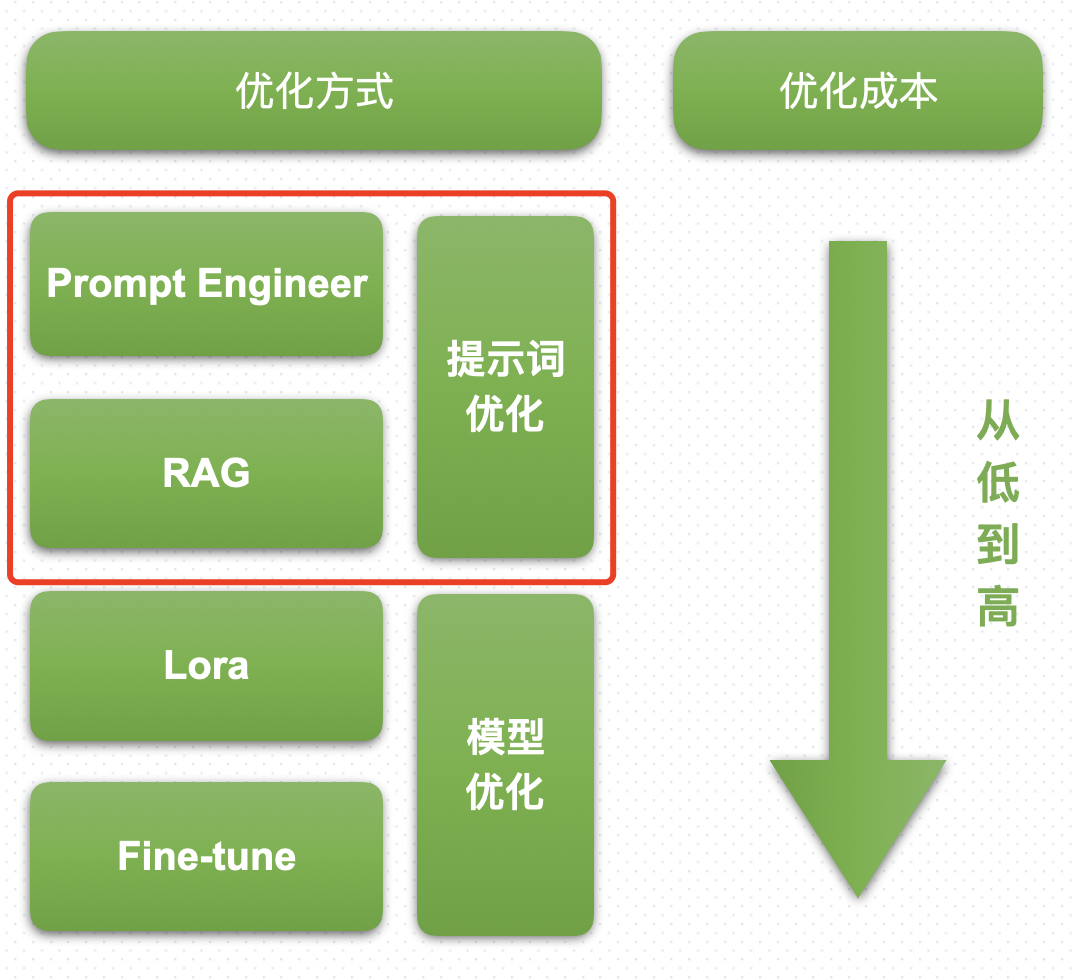
如果模型本身的参数不足、在理解和推理上存在固有缺陷,单纯用RAG技术也无法提高模型的输出能力。
三、最后的话
这篇文章我们探讨了RAG的技术原理、优势和其局限性,希望对你有所帮助和启发。如果你有任何想法、疑问或者想要分享的经验,请随时留言交流。
祝你在AI应用的探索之路上充满收获和进步。
我是在野,欢迎关注,咱们下篇再见🎉
参考资料
- 《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》
- 《什么是检索增强生成?》 from:NVIDIA-Blog
作者:在野在也,公众号:在野在也
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
