给产品经理讲技术|断点续传的奥义
如果你和果果一样是个重度的Chrome用户,那么你一定有过这样的糟糕体验:在Chrome中下载一个文件,下载还未完成时(也许进度已经99%)突然告诉你下载失败了,然后点击重试,傻傻的Chrome竟然不支持断点续传,而是从头开始重新下载这个文件。
后来果果经过一番调查,发现其实Chrome是自带了断点续传掉功能的,只是默认是关闭的,在chrome://flags中有个选项,可以将其打开。再仔细想想,也是合理的,美帝的网速太快了,他们平时也用不着这功能,就默认关闭了。

不过果果作为天朝的无证程序员,觉得还是有必要给各位无证产品经理介绍一下断点续传的原理。
首先我们来看下HTTP Header中的两个特殊字段,一个在请求头中叫Range,表示本次请求要求服务器返回的数据范围,另一个在响应头中,是Content-Range,表示本次服务器返回的数据范围。
来看个栗子,我在下载一个文件,有2048B大小,当我收到1024B数据时,由于某种不可预知的原因中断了,这时我只想把剩下没下完的数据拉回来,那么我在请求头面会这样写Range: bytes=1024-,表示我要从1024B开始拉取后面的数据,究竟还剩下有多少数据我也不知道,所以有个“-”单独在那里。然后服务器在响应里面会这样写Content-Range:bytes 1024-/2048,这个表示返回了从1024B到文件结尾的全部数据,同时告诉了我这个文件总共2048B大小。
可以看出,请求头里写Range,可以指定请求某一个片段的数据,相应的响应包里面用Content-Range的表示返回数据片段在整个文件中的位置。
我们再脑洞大开一下,如果我把这个文件分成4个片段,然后再用4个线程来同时下载相应的片段。请求参数类似下图这样:
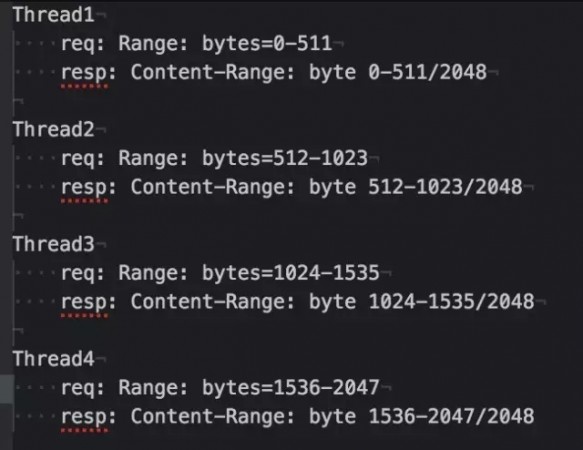
最后把它们拼在一起,那么我们的下载同样大小的文件,就只需要以前1/4的时间了。
其实这也就是多线程下载工具的基本原理,你懂了吗?
关键字:产品经理, 断点续传, 经理, chrome
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
