给产品经理讲技术|一步一步写爬虫之抓包

本文作者:果果 原文地址:戳这里
【相关推荐】
给产品经理讲技术|向前兼容、向后兼容
给产品经理讲技术|产品经理应该这样提需求之“状态机”
给产品经理讲技术|撩妹技术三部曲之“设计模式”
给产品经理讲技术丨没线,并不可怕?
给产品经理讲技术丨提需求的正确姿势是什么
上回讲到我们通过分析微信「历史消息」的网页结构,找到了藏有每篇历史文章的URL的标签,并且验证了这些URL就是我们文章的真实地址。但是还有个问题摆在我们面前,就是这个页面每次只显示10篇历史文章,只有用户滑动到底部的时候,才去拉取之后的10篇。
这对于人工操作来说并不是什么难事,你只需要不停的下滑网页就能看完所有文章。但对爬虫来说,如何让程序自动触发「加载后面10篇」呢?一个很直接的办法就是让程序模拟人的操作,不断的给网页发送「下滑」的命令,不是做不到,实际上用注入JavaScript代码的方法来实现这种需求是很常见的手段。但是我们并不打算这样做,因为太笨了。你可以想象一下你闭上眼睛操作手机是什么感觉,太多的不确定性,导致程序写起来难度大增。
另一个角度,既然这个网页在「下拉到最后」的时候会去「拉取后面10篇」,那我们只需要知道它是如何「拉取后面10篇」的,然后不断的伪造这个请求,是不是就可以拉取到所有文章了呢?这是个好思路,前提是你知道什么叫「抓包」。
我们知道,网络通信是一个一问一答的过程。你的浏览器、各种APP连接到服务器之后,会通过HTTP协议向服务器提出拉取数据的请求,之后服务器收到请求作出应答,把数据再吐回来。抓包就是在二者之间设一个检查站,所有经过的数据,都要把自己的来路、目的地和数据内容亮出来。
有很多软件专门做抓包的生意,比如大名鼎鼎的TCPdump、WireShark等等。但是对于在浏览器里的页面发生的数据通信,只需要打开Chrome的开发人员工具,切换到network选项卡就够了。
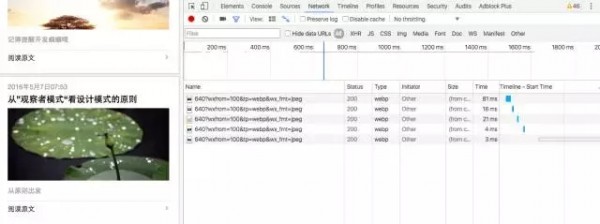
这个界面里,我们重点看Name下面的一列,显示的是这个网页发出的所有请求。你可以按F5刷新下整个页面,然后这一列会出现更多请求。
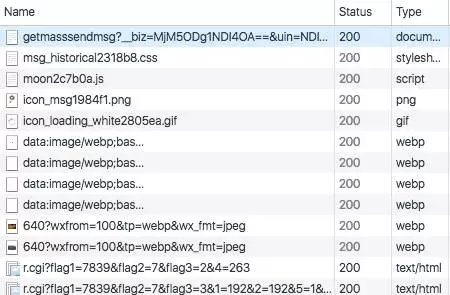
点开其中一个,右边变成了这个样子。
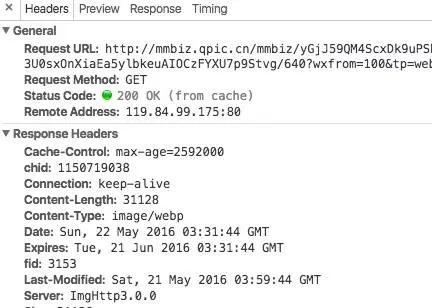
右边是这个请求的详细信息,一共有四个TAB,第一个是headers,就是我们之前讲过的HTTP请求头。第二个是preview,如果这个请求是拉取图片的话,你会在这里看到拉取到的图片。第三个response,是服务器返回的数据。第四个timing,方便程序员做一些性能优化的事情。
回到正题,先点击上面的图标清掉所有请求,然后在网页里下滑页面直到出现「加载更多」,我们发现右边的network里多出了几个请求,说明当页面滑到底部的时候,网页确实发出了请求,来拉取后面10篇文章。有一个getmessage开头的请求引起了我们的注意(废话,名字都起得这么明显了)。
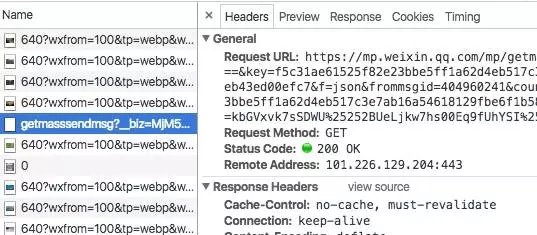
右边第一项就是这个请求的URL。再切换到response那里,看看服务器回了些什么东西。

熟悉吗?不认识没关系,这是JavaScript常用的一种数据格式叫JSON,它其实就是一些类似「姓名:小强,性别:男」之类的键值对,用大括号包起来。我们可以解析它,然后就会发现这就是后面10篇文章的标题、URL、头图地址、简介之类的信息,正是我们想要的!
至此我们的思路应该很清楚了。我们的爬虫在打开「历史消息」这个页面后,首先会爬到最近10篇文章URL,然后伪装成页面向服务器发起「加载更多」的请求,请求的URL就是上面的URL,这样服务器就会吐给我们一个JSON格式的响应,我们解析这个JSON,就能拿到后10篇文章的URL。这样重复几次,就能拿到所有文章的URL啦。
离我们的目标又近了一步,现在我们通过抓包分析,拿到了所有文章的URL,如何把他们下载下来并保存成PDF呢?下回再讲。
欢迎添加微信公众号:给产品经理讲技术

关键字:产品经理, 抓包, 爬虫, url
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
