解密OneEntity体系
前几篇你跟草帽小子一起了解了阿里数据中台的建设计划,接下来我们一起来解密OneEntity体系。
一、数据孤岛
阿里巴巴作为一家包含多条业务线的公司,如电商、金融、广告、文化、教育、娱乐、设备和社交等领域,数据区域包含国内、国外;数据场景包含线上的人货场钱、线下的人货场钱位置等数据,以及物流、用餐、咨询、影视、出行、阅读、音乐和健康等相关数据。
仅是与人相关的数据就包含业务账号信息、PC cookie、无线IMEI与IDFA等设备标志、身份属性等。
而随着人们互联网行为的多样化,如果每天都有数千亿条实体数据产生,而这些数据都分属于不同业务单元,那么数据就很容易孤立。
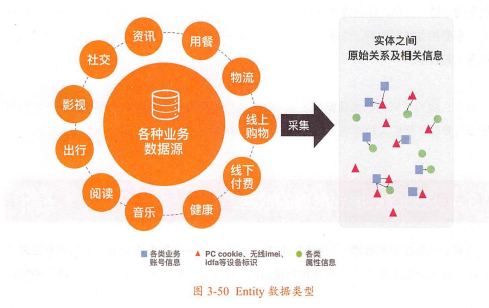
草帽小子思考:以前总是不理解数据孤岛这一部分,明明已经建立了onedata体系,做好了各业务线数据接入,ODS层数据全面接管,明明数据都汇总到了一块,为何还说数据孤岛呢?
直到真正开始做用户画像这一工作才发现,底层的指标体系往往是直接面向各个业务线内,缺乏一个业务线间的关联,这是由业务局限性导致的。比如说,你是淘宝的运营人员,那你会关注钉钉的指标体系是怎样的吗?
答案是显然不会。
那这样就产生了数据的断层,单是从底层的指标层,用户在钉钉的行为习惯,淘宝的人员是无法获知的。那如果我作为淘宝的人员,既想知道他在淘宝上购物行为,也想知道他在钉钉、支付宝、优酷等地方的行为习惯,又该从何得知呢?
二、数据只有融通才能真正产生价值
为打破数据孤岛,创造更大的数据价值,阿里设计了OneEntity来提供全域数据与服务。OneEntity体系主要包含统一实体、全域标签、全域关系、全域行为4大类。
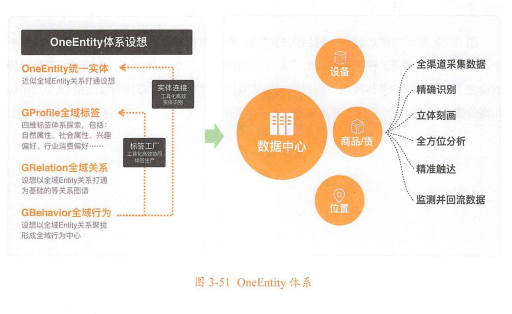
1. OneEntity统一实体
将若干个实体归拢到一起,并命名为OneEntity,可分为一般质量、高质量、高价值OneEntity。
2. GProfile全域标签
基于归拢后的数据对OneEntity进行贴标签的操作。在OneEntity体系中,如何为OneEntity贴上标签并找出高质量、高价值的OneEntity是最常见的问题。
这几离不开标签的萃取能力,那阿里是怎么萃取标签的呢?
(1)有效
一方面,主动去找人口学、社会学等学科的教授,学习与“人”相关的理论知识;
另一方面,调研了很多业界的标签分类体系,取长补短。
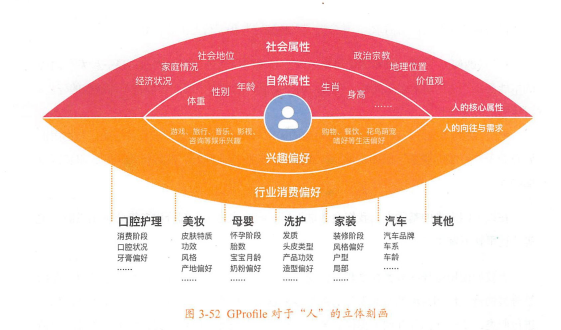
最终,将“人”的立体刻画划分为“人的核心属性”和“人的向往与需求”2大部分,具体包含4大类:
人的核心属性,可分为自然属性、社会属性。
- 自然属性:是指人的肉体存在及其特征,是人自出生后自然存在的,一般不会因人为因素发生较大的改变。例如“性别”“生肖”“年龄”“身高”“体重”等。
- 社会属性:指人在实践活动基础上产生的一切社会关系的总和。人一旦进入社会就会产生社会属性。例如经济状况、家庭状况、社会地位、政治宗教、地理位置、价值观等。
人的向往与需求,可分为兴趣偏好、行为消费偏好。
- 兴趣偏好:是人堆非物化对象的内在心理向往与外在行为表达,是一种法子内心的本能喜好,与物质无必然关系。例如渴望爱情、需要安全感、讨厌脏乱环境等。
- 行为消费偏好:是人对物化对象的需求与外在行为表达,涉及各行业,与物质世界存在千丝万缕的联系。例如母婴行业偏好、美妆行业偏好、洗护行业偏好、家装行业偏好等。
在以上四大类的基础上,我们又尝试根据不同的业务形态进一步细分二级、三级分类。
(2)高速
标签的萃取工作包含:数据采集;清洗,去噪声并统一;反复试用并确定最佳算法及模型;为模型选择计算因子并对模型中的每一个计算因子调配权重;产出标签质量评估报告以辅助验收。
我们随机抽查了若干个在用的标签,预估工作量和工作周期,一个有价值的标签的萃取,平均耗时2周。
慢的主要原因,一是由于萃取流程复杂,每个标签萃取都依赖底层的基础数据,而较少依赖上一层汇总的数据中间层数据;二是大量重复的人力,对应的标签萃取逻辑时可以复用的,包含算法的选择、模型训练和计算因子的加权等,但由于不同人来做,造成了很多重复工作。
标签萃取过程复杂,那有什么可以参考的流程呢?
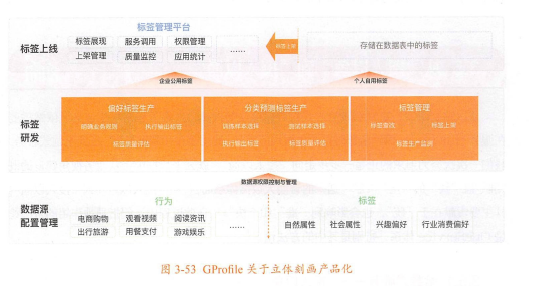
首先,数据源层面:建设一套完整的数据源,以OneEntity体系为核心,将OneEntity相关实体及其行为全部串联起来,与存量的标签一起作为数据源。
其次,标签计算层面:将标签萃取逻辑沉淀为2种,分别对应到偏好类标签和分类预测类标签的工具型产品的生产过程中,包含计算因子、权重等业务规则、数据样本选择、模型与算法选择等。
最后,标签监测层面:沉淀质量评估报告和生产监测、上线等管理流程。
当一整套工具型产品上线之后,批量生产十几个同类型标签只需要2天左右,这是因为在补足数据源、确定业务规则、选择数据样本、选择算法与模型的过程中,减少了大量的代码开发与模型训练的工作。
在这个过程中,参与的角色也发生了变化,从原本的以数据产品经理、数仓工程师、数据科学家为主导,转变为对业务更为熟悉的业务人员、数据分析师为主导。
3. GRelation全域关系
找到对象的关联关系,当OneEntity代表人时,就可以找出他的亲属、朋友、校友和同事等;当OneEntity代表商品时,就可以找出他的上下游商品/货等。
4. GBehavior全域行为
将与OneEntity相关的实习及行为关联起来,形成一套用户行为体系。如:
- 姓名、邮箱、地址等,这是现实世界中的唯一标志,就像OneEntity代表着你在大数据世界里的唯一标志。
- 籍贯、年龄、政治面貌、宗教信仰等,这是现实世界中的标签画像
- 父母、子女、夫妻等,天生或后天产生的一系列关系,代表着GRelation在大数据世界中的关系
- 何年何月读大学、何年何月第一次参加工作、何年何月获得某项奖励以及证明人是谁等
在大数据的世界里,将孤岛数据实现融通并加以萃取,可以围绕一个主题展开全面剖析。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
