推荐策略产品经理必知必会②:三大常见的召回策略
常见的召回策略有以下三种:

一、规则召回
最常用的召回策略,解释性最强。
优点:策略逻辑清晰明了,业务意义明确,可解释性极强
缺点:个性化弱,千人一面,易引起马太效应,头部曝光越来越多。
适用场景:最开始搭建推荐系统时
标签召回
使用方式:最早应用于音乐与电影网站,同时对内容和用户打标,计算两者的标签重合度。
核心问题:如何构建科学全面的标签体系、如何为用户和内容打标,主流打标方式仍为人工打标。
高质量分召回&类目召回
使用方式:电商推荐和内容推荐场景,适合用于新人冷启动。
举例:电商领域通过历史销量、好评率、收藏数等综合评估物料的质量分;内容通过浏览量、互动数来综合评估。
注:为质量因子配备超参数,超参数决定该部分在整个公式的重要度,为人工设定,参数为模型训练得到。
质量因子归一化:Min-Max归一化公式进行,对于电商不同类目需要分类目进行归一化,防止极大差异影响。
热销召回
使用方式:召回近期热门的物料,适合用于新用户召回策略,“热门”由业务进行自行定义,需要设计统计周期(长、中、短)为x、y、z。
高点击率召回
使用方式:召回“CTR预估模型”这一核心指标
复购召回
使用方式:生鲜电商领域经常使用
实现方式:基于用户维度统一其购买的商品,使用Min-Max归一化方式,在综合电商领域一般,大宗商品会让用户印象差
二、协同过滤
推荐系统最经典的算法,包括基于物料(Item-CF,1998)的算法和基于用户(User-CF,1992)的算法,即“协同 过滤”,利用群体数据去寻找规律,测定物料间、用户间的相似性,排除相似度低的物料与用户,后再进行排序。
核心问题:如何计算物料与物料之间、用户与用户之间的相似度
优点:算法逻辑较简单,容易实现,同时又有不错的效果,具备一定的个性化
缺点:与规则召回缺点方向一致,冷启动问题明显,存在一定的马太效应,头部热门问题容易与其他商品产生关联
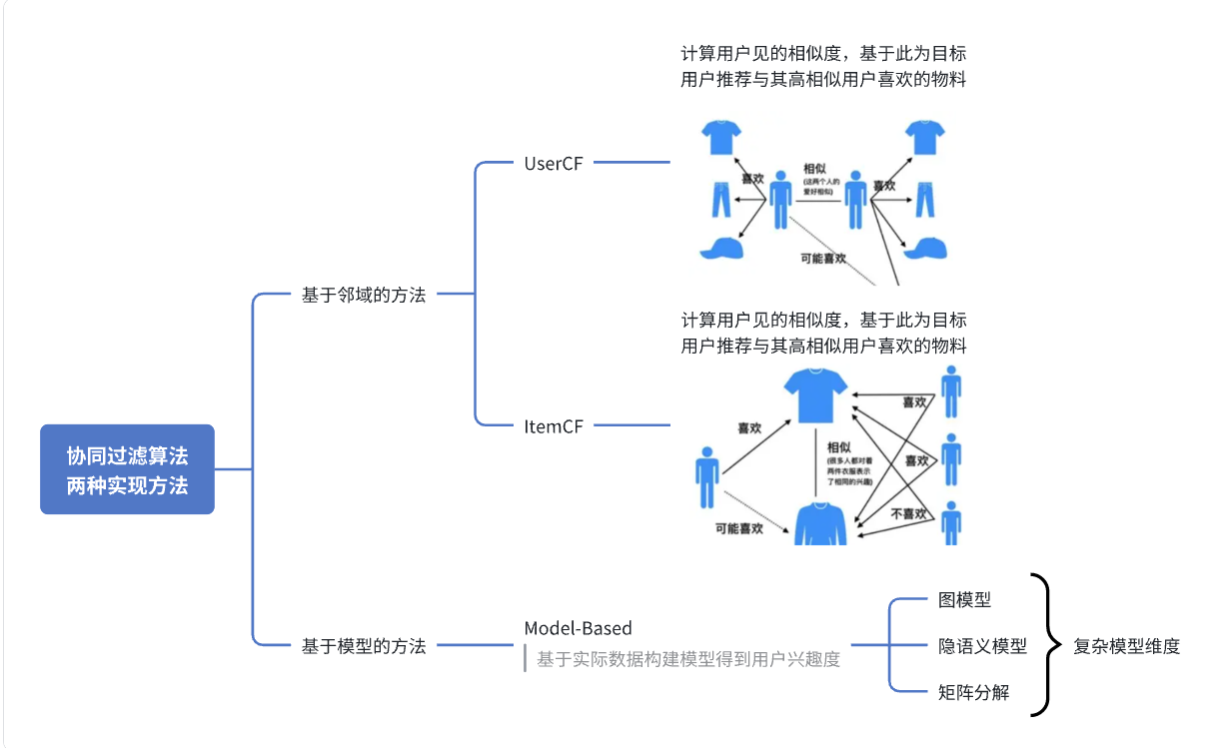
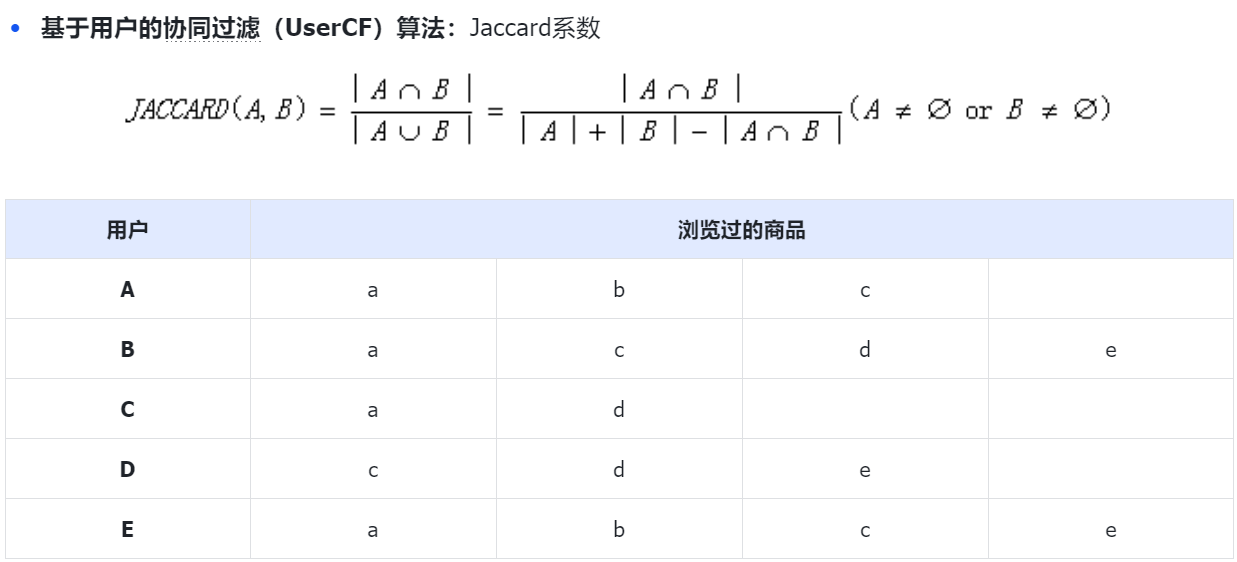
1.挖掘与目标用户相似的用户集合,取相似度排在前几位的用户作为候选集。
Jaccard系数:Wab = 0.4; Wac = 0.25; Wad = 0.2; Wae = 0.75,B、E最高
2.挖掘该集合中受欢迎的物料,从中为目标用户推荐他没有接触过的物料。
B、E浏览的商品中,A为浏览过d、e,估算其兴趣度

P(A,d) = 0.4*1 0.75*0 = 0.4;P(A,e) = 0.4*1 0.75*1=1.15,故而A对e商品的兴趣度高选择e商品为用户推荐
基于物料的协同过滤(Item算法):目前在各大互联网公司应用十分广泛,用余弦相似度计算。
举例如下,6个用户和5个商品。
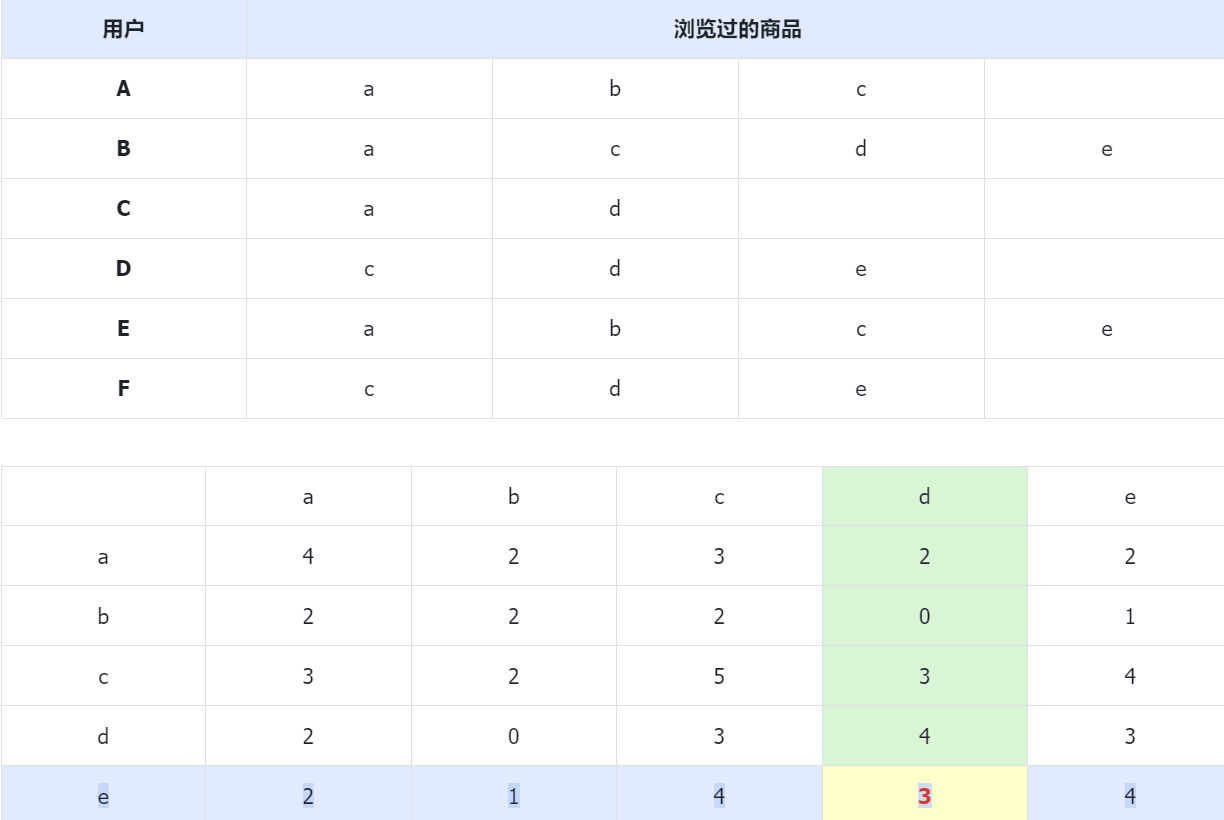
计算商品间的相似度:余弦定理计算商品间的相似度

基于目标用户历史浏览行为和商品间的相似度,为其推荐感兴趣且未浏览过的商品
本文只有5个商品,目标A浏览过a、b、c。没有浏览过d、e,所以预估P(A,d)、P(A,e)。
P(A,d) = 0.5*1 0*1 0.67*1=1.17
P(A,e) = 0.5*1 0.35*1 0.89*1=1.74
所以优先为用户A推荐商品e。
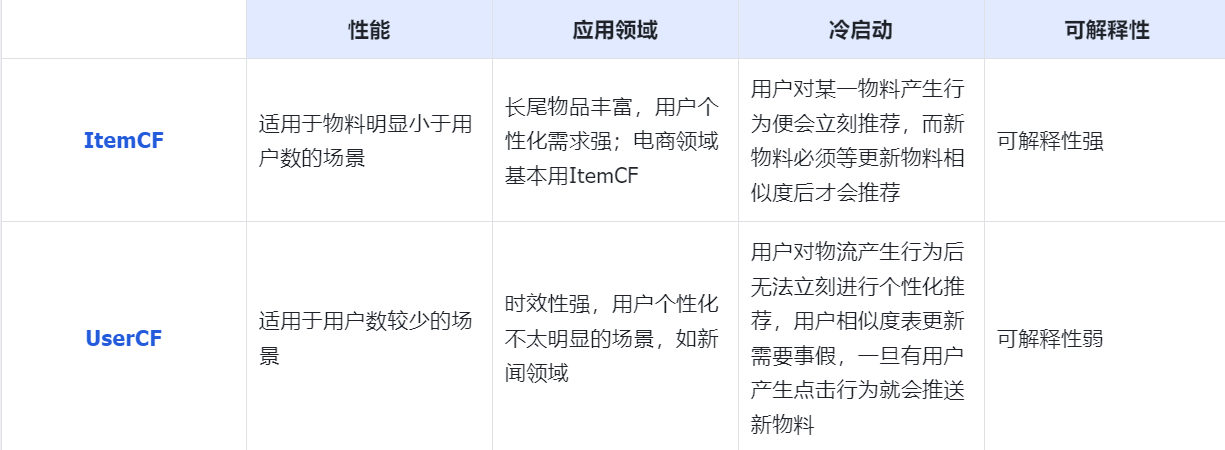
UserCF算法与ItemCF算法的异同点 总结
基于图模型的方法(graph-based model)
主要分为两大步:
1)将数据表格转化为二分图
2)基于两个顶点的路径数、路径长度及经过的节点出度判断相关性。
例:“A——a——B——c”,路径长度为3,A到c只有一条路径,而A到e有两条,A与e关联性强于A与c。
A到e的两条路径哪个相关性更强,比较出度(该顶点对外连接了几个其他的顶点),出度越大,相关性越弱。
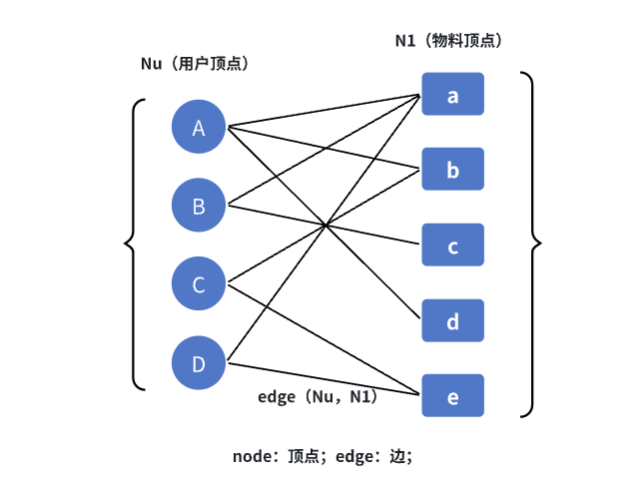
三、基于向量的召回
1. 隐语义模型
最经典的应用就是隐语义模型,或者称为隐向量模型。
在现实中,用户与物料间的矩阵是非常稀疏的,很难进行预估,而隐语义模型的思想是挖掘用户和物料间的特征属性,将用户和物料归到相同的特征维度,一般为四象限维度,然后再进行比较。
核心:将一个共现矩阵(用户和物料的交互矩阵)分解成两个小矩阵(用户矩阵和物料矩阵),两个矩阵在相同的向量维度上。
矩阵的常见分解方法有三种:
方法一:特征值分解
只能作用于NxN矩阵,大多数用户x物料矩阵并非方矩阵,不具有适用性。
方法二:奇异值分解
适用于所有MxN矩阵,但是对于矩阵的稠密度要求高,应用时必须把缺失值用近似值、平均值补全,计算复杂、资源要求高。
方法三:梯度下降法
Funk SVD,又称LFM,将预测值与实际评分值比较,损失函数为均方差,利用梯度下降进行迭代,直到模型收敛。
隐语义模型优缺点:
优点:
1)泛化能力强。一定程度上缓解矩阵稀疏问题
2)计算复杂度低。计算复杂度为(m n)*k,而协同矩阵为m*m或者n*n
3)更好的灵活性和扩展性。可以与其他特征组合或拼接,也可以和深度学习神经网路哦结合
缺点:
仅考虑用户和物料各自的特征,不方便加入用户、物料、上下文特征以及其他一些交互特征,模型本身具有一定局限性。
2. 双塔模型
来源:源自DSSM模型(deep structured semantic model),最初为了解决NLP中语音相似度问题。
应用方式:利用深度神经网络将文本表示为低纬度向量,将检索词、文档分别嵌入两个向量他,计算两个向量间的余弦相似度,后归一化可以得到其相关性。
例:DSSM模型在训练时,正样本为该检索词下曾被点击过的文档集合D ,负样本为用户未点击过的文档集合。最终得到检索词和文档的语义向量维度(128维),然后计算两个向量间的余弦相似度,最后通过SoftMax函数进行归一化,得到检索词和每一个文档的相关性。
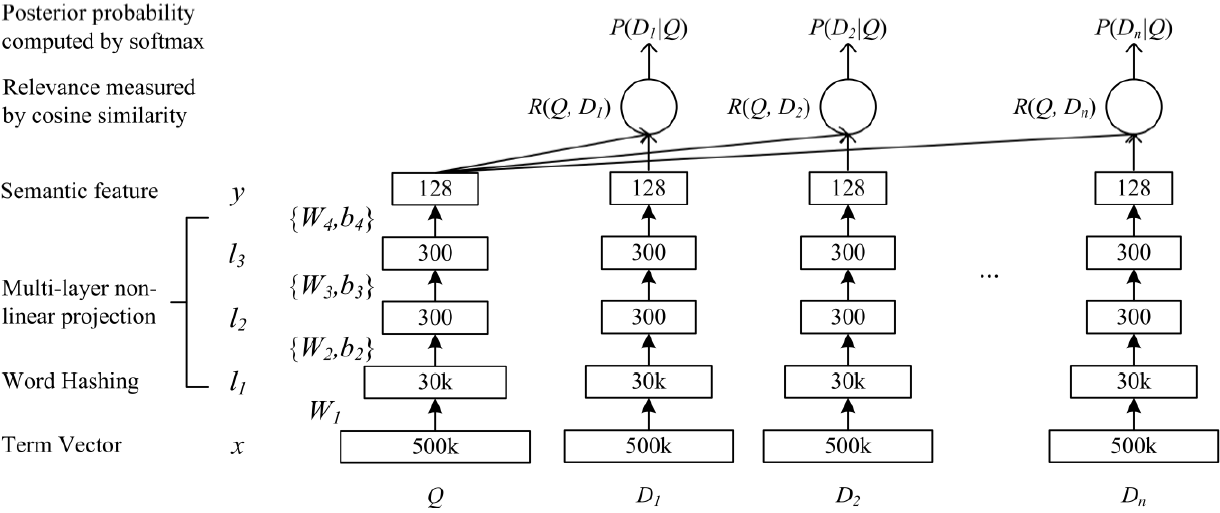
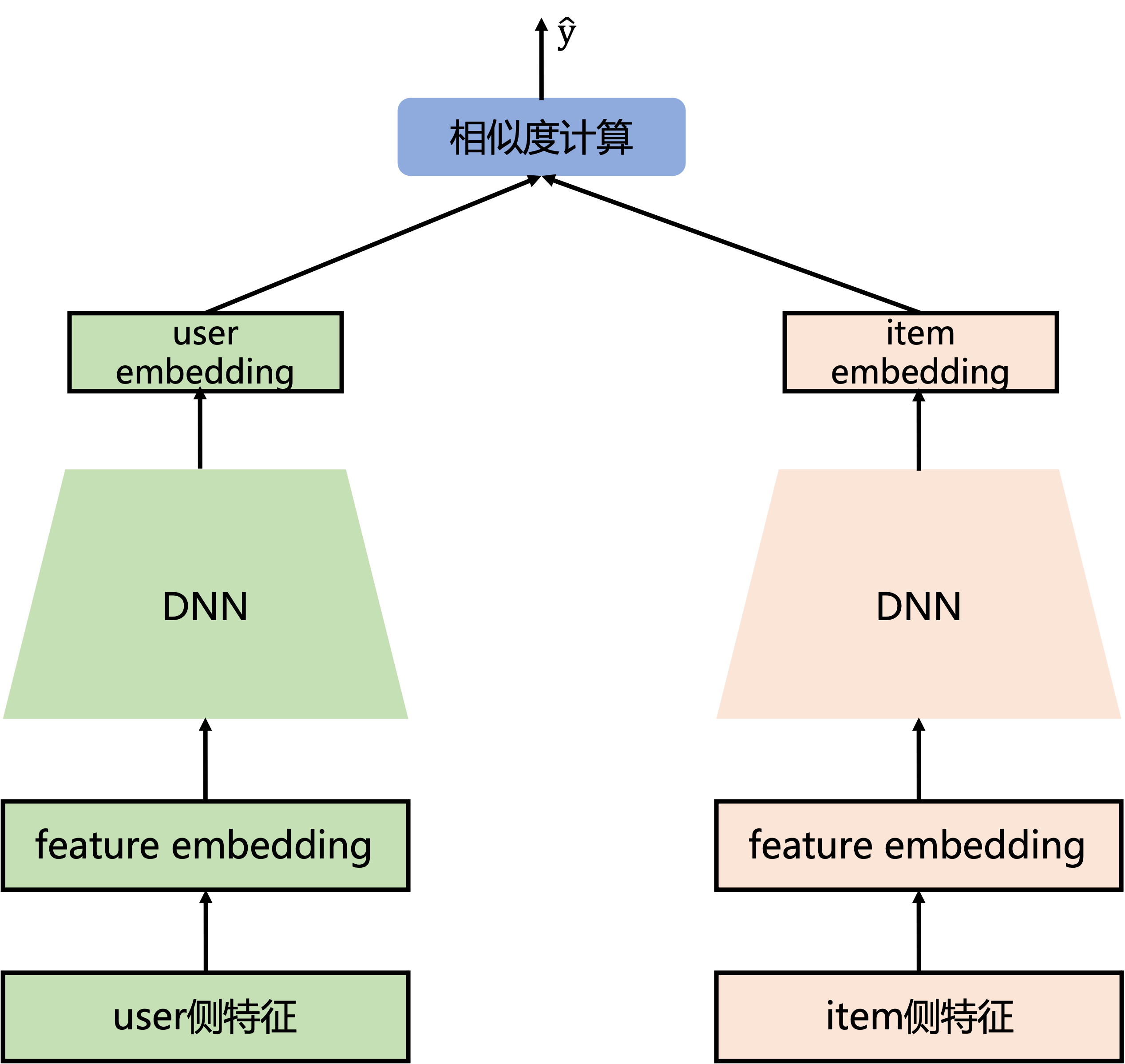
双塔模型为一种模型思想,而非一种具体的模型。主要分为输入层、表示层、匹配层三层。
- 输出层:用户与物料各自独立的特征,没有交叉特征,进行各自特征编码和拼接。
- 表示层:DNN训练后得到收敛变量,用户、物料的输出特征维度必须相同。
- 匹配层:计算用户向量与物料向量的相似度,主要用余弦相似度计算。cos越大越相似。
双塔模型在实际应用中主要作为召回模型来使用,召回模型的核心要素就是正负样本的选择。正样本为用户曾经点击过的物料,而负样本的筛选很有艺术性,如果如同精排模型使用线上曝光但未点击的物料作为负样本,会导致样本选择偏差(SSB,sample selection bias)。因为精排模型与召回模型的候选集是不同的。
负样本的选择方式有很多,常规方式便是从整体物料库中随机抽取,选择更多物料让模型学习。
双塔模型的实际应用网上可以查询些哦!流程:提前备好数据库,用户访问读取,更新用户库,检索兴趣推荐。
优点:
双塔模型能对用户塔和物料塔进行解耦,离线训练好数据再进行线上部署,线上读取、计算速度很快,解决了推荐系统的工程性能问题,相比其他模型推荐的整体效果更好。
缺点:
与隐语义模型相同,没有用到用户和物料的交叉特征。
四、召回策略的效果评估
线上效果评估:简单直接的AB Test小实验。先通过离线评估确定新的召回策略,再进行线上AB Test小流量试验。
离线效果评估:主要评估单个召回分支返回的物料和实际线上曝光与点击物料之间的重合度,越高召回效果越好。
各路召回的贡献度归因:每一路召回产生的实际线上效果不一样,基础条件之一是点击曝光埋点里有针对不同召回分支的埋点标识。主要有三种方式:物料归因计算相同贡献;归一化分数统一量纲归因于召回分支分数最高的一路;权重归因,对各支路权重进行分数汇总,再按权重归因。
召回模块为整个推荐系统的基础,策略产品经理只有明白每一种召回策略的底层逻辑才能深度参与到召回策略的设计中,为不同用户、不同场景定制召回策略。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
