更好的输入,才能更好地思考
今天看到一句很牛的话,放在题目上蛮好。
首先,我觉得思考是第一生产力,维持着工作势能和带来活力。因为一方面,机械化工作本身就会让大脑、肢体感受厌倦和乏力,你会觉得没意义,后面转化成一种疲于应付。
另外一方面,你会陷入某种内耗里面,会常问自己N个为什么?给我任务的人是不是傻x,为啥子这么做等等诸如此类吧。
所以,在这环节阶段必不可少。
01
今年来,或者说从GPT的迅猛凸起,我们就一直与AI平行或结合。从场景及目前的市场变化看,2024年标志着AI搜索技术的突破年,它不仅颠覆了传统搜索模式,更以前所未有的速度和智能化水平,为用户带来革命性的搜索体验。
那么AI搜索为何能获得巨大增速,这个新时代到底是靠什么最前沿的技术来实现的呢?
说到这,搬出我们的搜索工具来给我划出结构和大纲。并用一个直白通俗易懂的例子来给我们说明下。
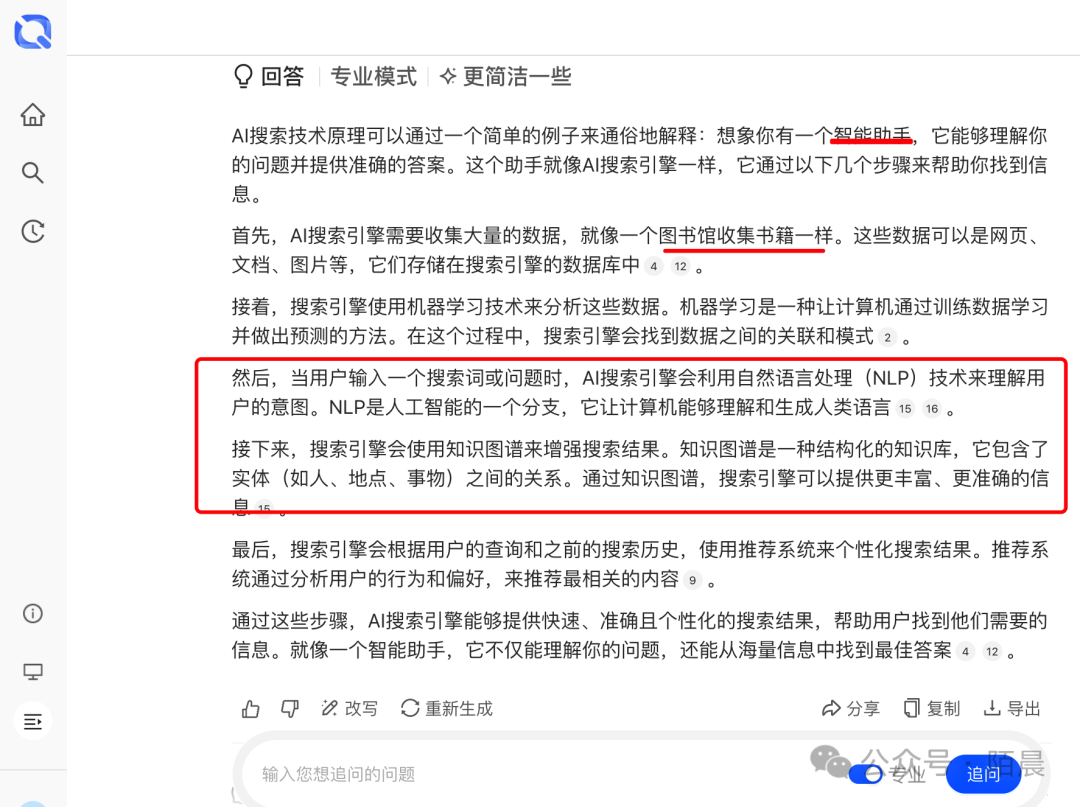
让我用一个简单的例子来通俗地解释AI搜索的技术原理:
想象你有一个智能助手,它能够理解你的问题并提供准确的答案。这个助手就像AI搜索引擎一样,它通过以下几个步骤来帮助你找到信息。
首先,AI搜索引擎需要收集大量的数据,就像一个图书馆收集书籍一样。这些数据可以是网页、文档、图片等,它们存储在搜索引擎的数据库中412。
接着,搜索引擎使用机器学习技术来分析这些数据。机器学习是一种让计算机通过训练数据学习并做出预测的方法。在这个过程中,搜索引擎会找到数据之间的关联和模式2。
然后,当用户输入一个搜索词或问题时,AI搜索引擎会利用自然语言处理(NLP)技术来理解用户的意图。NLP是人工智能的一个分支,它让计算机能够理解和生成人类语言1516。
接下来,搜索引擎会使用知识图谱来增强搜索结果。知识图谱是一种结构化的知识库,它包含了实体(如人、地点、事物)之间的关系。通过知识图谱,搜索引擎可以提供更丰富、更准确的信息15。
最后,搜索引擎会根据用户的查询和之前的搜索历史,使用推荐系统来个性化搜索结果。推荐系统通过分析用户的行为和偏好,来推荐最相关的内容9。
通过这些步骤,AI搜索引擎能够提供快速、准确且个性化的搜索结果,帮助用户找到他们需要的信息。就像一个智能助手,它不仅能理解你的问题,还能从海量信息中找到最佳答案412。
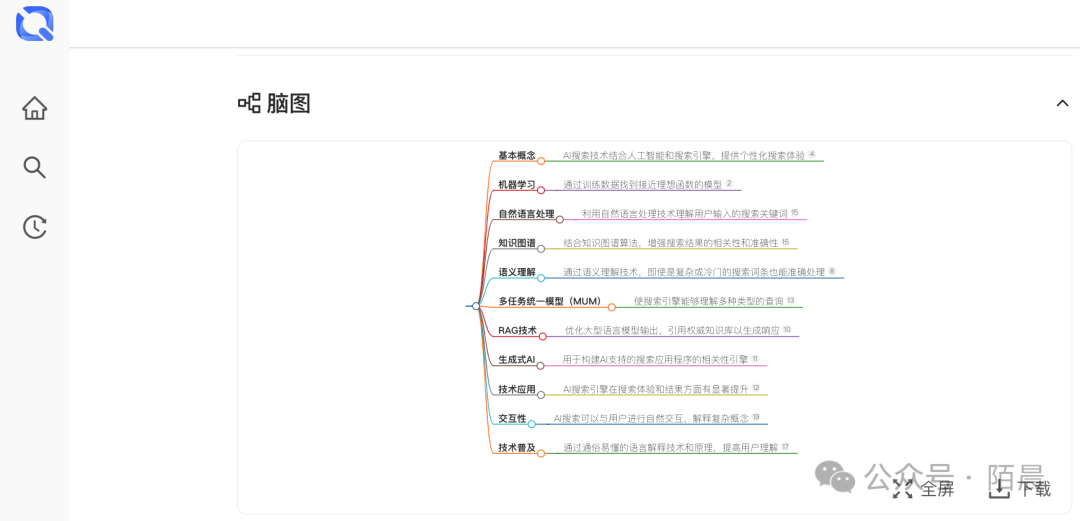
AI搜索技术是一种利用人工智能方法来增强信息检索的技术。它的历史可以追溯到20世纪50年代,最初用于解决逻辑和数学问题,如象棋游戏。
这些早期的AI系统,如IBM的Deep Blue,通过搜索算法评估可能的棋局走法,并选择最佳策略。Deep Blue在1997年击败国际象棋世界冠军加里·卡斯帕罗夫,这标志着搜索技术在解决复杂问题上的巨大潜力。
02
在AI中,搜索技术主要用于两大类问题:优化问题、决策问题、解决问题
大语言模型尽管在应用领域取得了显著的成果,但是在具体应用中仍具有很大的局限性:
1.在处理知识密集型任务中可能会产生”幻觉”,比如:
- 输入冲突幻觉 (用户想要a但返回b,输入晚餐返回午餐)
- 上下文冲突幻觉 (回答全文没出现某事物,总结的时候却出现)
- 与事实相矛盾的幻觉 (对某个事物下定义不正确:比如熊猫属于猫科动物)
2.处理训练数据中没有的知识 无法回答或者乱下定义
3.处理时效性问题 无法回答或回答不对
为了克服这些问题,检索增强生成(Retrieval Augmented Generation,RAG) 通过计算语义相似性 从外部知识库检索相关文档片段,从而增强LLMs的能力。通过引用外部知识,RAG有效的减少生成事实错误内容的问题。
最初RAG的诞生 与Transformer架构的兴起同步,主要是通过预训练模型(Pre-Training Models,PTM)的方式,通过额外的知识增强语言模型。最初为了优化预训练技术。随着ChatGPT的出现,LLMs展示了强大的上下文学习能力,标志着RAG研究的一个转折点,在推断阶段(提问回答),RAG研究转向为LLMs提供更好的信息来应对更复杂和知识密集的任务。从而推动RAG快速发展,随着研究的深入,RAG增强不再仅限于推断阶段,开始更多地融入LLM的微调技术。
03
RAG的含义随着技术的发展而扩展。在大型语言模型时代,RAG的具体定义是指模型在回答问题或生成文本时,首先从大量文档语料库中检索相关信息。然后,利用这些检索到的信息生成响应或文本,从而提高预测的质量。RAG方法允许开发人员不必为每个特定任务重新训练整个大型模型。相反,他们可以附加一个知识库,为模型提供额外的信息输入,并提高其响应的准确性。RAG方法特别适用于知识密集型任务。综上所述,RAG系统由两个关键阶段组成:
1、利用编码模型检索基于问题的相关文档,如BM25、DPR、Col- BERT和类似方法[Robertson等人,2009,Karpukhin等人,2020,Khattab和Zaharia, 2020]。
2.、生成阶段:使用检索到的上下文作为条件,系统生成文本。
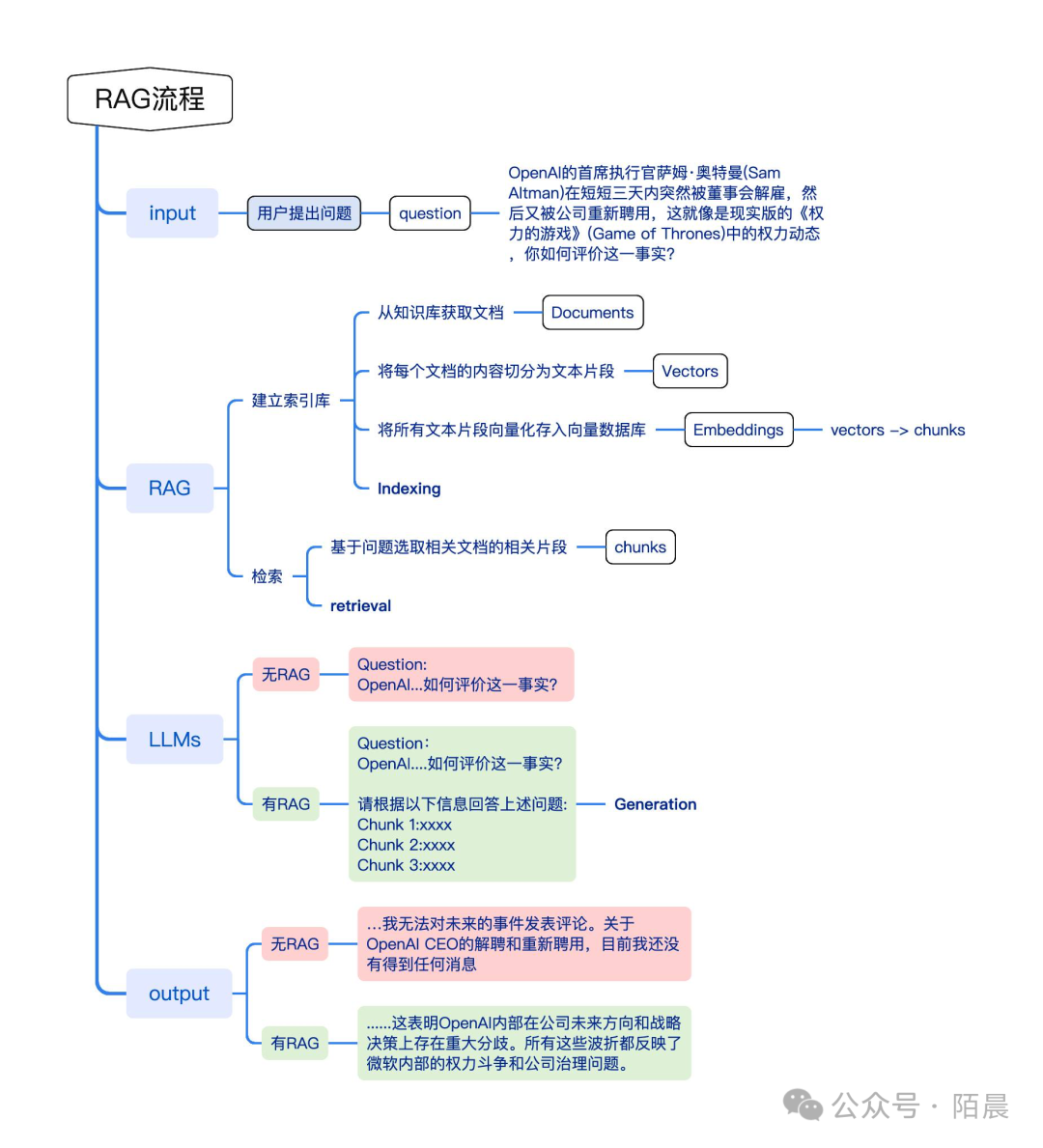
上图是应用于问答的RAG流程的代表性实例。它主要包括3个步骤。
- 索引 Indexing。文档被分成几块,编码成向量,并存储在向量数据库中。
- 检索 Retrieval。根据语义相似度检索与问题最相关的Top k块。
- 生成 Generation。将原始问题和检索到的块一起输入LLM以生成最终答案。
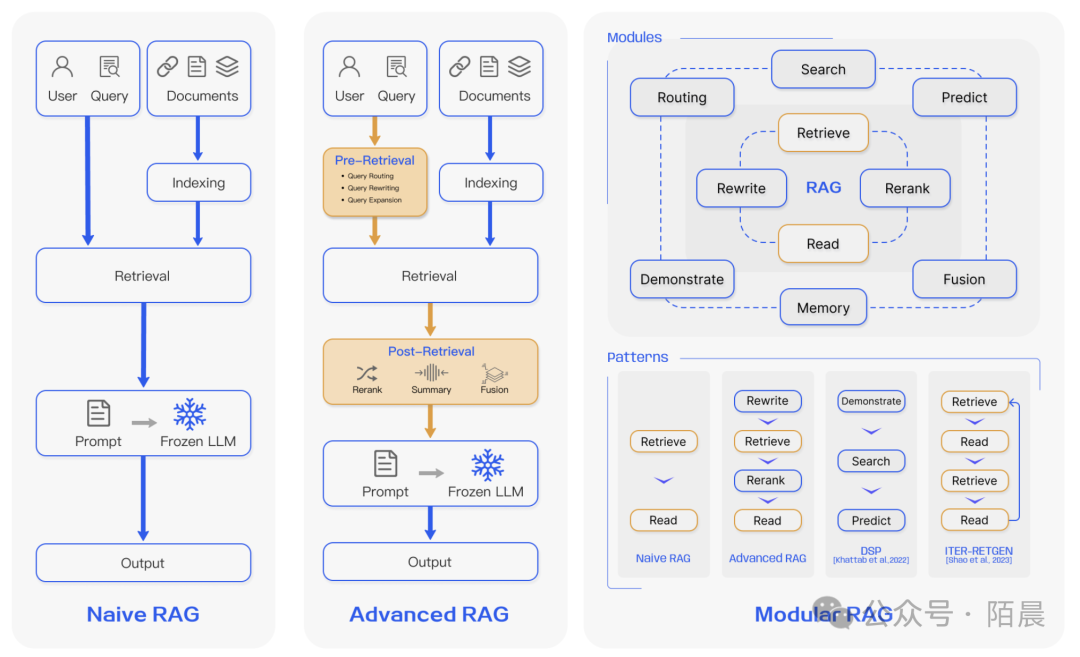
1、Naive RAG – 朴素RAG范式
它在ChatGPT广泛应用后迅速崭露头角。Naive RAG遵循传统的流程,包括索引、检索和生成,也被称为“检索-阅读”框架。
2、Advanced RAG – 高级RAG范式
高级RAG旨在解决朴素RAG的局限性,特别关注提高检索质量。它采用预检索和后检索策略,通过滑动窗口方法、细粒度分割和元数据的整合来改进索引技术,同时引入多种优化方法以提升检索效率。
3、Modular RAG – 模块化RAG范式
模块化RAG架构超越了前两种RAG范式,提供了更高的适应性和灵活性。它包括多种策略来改进其组件,如添加搜索模块进行相似性搜索,以及通过微调来优化检索器。
Retrieval-Augmented Generation(RAG)作为机器学习和自然语言处理领域的一大创新,不仅代表了技术的进步,更在实际应用中展示了其惊人的潜力。

04
引擎的本质:“搜索引擎的核心是用户体验。互联网虽然是免费的,用户使用搜索引擎不付出金钱,但也是有代价的,那就是时间成本。因此,让用户在最短的时间内获得最想要的东西就是最具性价比的服务
一款优秀的AI搜索引擎,应该能对用户的搜索意图有足够的推理能力,能快速索引相关优质的信息源,并且以适当的格式做内容呈现。是索引库、检索算法、工程能力、产品设计的综合比拼。
作者:陌晨 公众号:陌晨
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
