当2027年人类数据被用尽,那大模型未来怎么办?
为什么会产生这个问题呢?是因为最近我看见了一篇论文,说人工智能研究和预测组织 Epoch 在其发表的一篇论文里预测,人类世界的高质量的文本数据会在 2023-2027 年之间消耗殆尽。
而我们也知道,大模型的参数从十亿、百亿再到千亿,最近华为又推出了万亿参数的大模型,大模型的参数大幅增加,相应的,用来训练大模型的数据量,也需要以指数级暴增。据网络公开的数据,以 OpenAI 为例,从 GPT-1 到 GPT-3,其训练数据集就从 4.5GB 指数级增长到了 570GB,以此内推,那GPT-5、GPT-6需要的训练数据更是天文数字了!
所以在未来,高质量数据的稀缺性会导致包括Open AI在内大模型公司的数据采集成本水涨船高,许多公司面临着数据获取困境,而根据Scaling law定律,大模型的性能提升,一定离不开数据量的提升,那大模型未来应该怎么办?
01.大模型、Scaling Law与数据
在讨论数据殆尽的解决方案之前,我们先来看看大模型、Scaling Law、数据三者之间的关系。
我们都知道Scaling law是大模型的摩尔定律,中文翻译为:规模法则,简单介绍就是:随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高,并且为了获得最佳性能,所有三个因素必须同时放大,当不受其他两个因素的制约时,模型性能与每个单独的因素都有幂律关系。
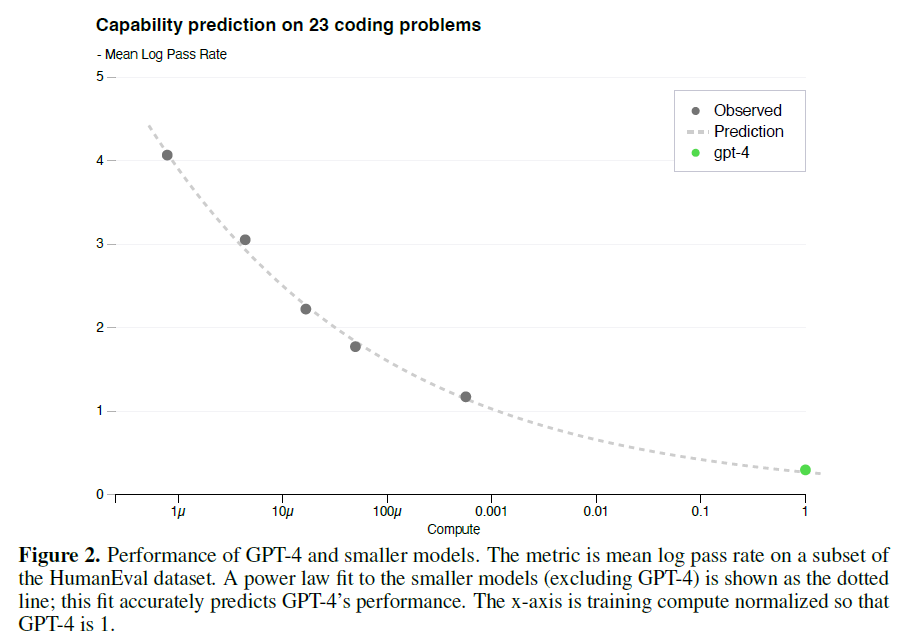
不管有多少人质疑Scaling law,但至少到今天为止,这个定律还在发挥着重要的作用,可以说大模型的性能能有今天这样的表现,离不开Scaling law。
而Scaling law中支撑大模型性能的重要一环就是数据!
a16z 创始人 Marc Andreessen 认为,二十几年来互联网积累的海量数据,是这一次新的 AI 浪潮兴起的重要原因,因为前者为后者提供了可用来训练的数据。

所以当人工智能研究和预测组织 Epoch 在其发表的论文里预测,人类世界的高质量的文本数据会在 2023-2027 年之间消耗殆尽时,我们会产生恐慌,因为一旦数据耗尽,新的大模型会面临严重的更新问题,而大模型的性能和对世界的理解提升不了,那更不要提AGI何时到来了。
尽管研究团队也承认,分析方法存在严重的局限,模型的不准确性很高,但是很难否认,AI 消耗数据集的速度是恐怖的,所以我们提出了一个问题:
当2027年人类数据被用尽,那大模型未来怎么办?
如果数据就是决定文本大模型未来能力天花板的最关键的因素,而未来我们可能面临数据短缺问题,那么目前来看将来只有两条路可走:
02.提高大模型对数据的学习效率
我们在生活中有个处理短缺问题的通用性原则,那就是开源节流,这个办法同样适用于大模型训练数据缺少的场景。
提高大模型对数据的学习效率就是我们节流的手段,简单来讲就是当我们的只能喂给大模型一定量的数据的时候,同时我们又希望大模型的性能能有所提升,那只能寄希望于模型能够从同样的数据中学到更多的知识,以此增强它的预测或分析能力,这不仅能显著提高模型的性能,还能有效降低对庞大数据集的依赖,这是一条看起来很理想的发展路线。
不过提高大模型的数据学习效率极富挑战性,当前,在不增加数据量的情况下提升模型效果的研究进展有限,但有数条可行的道路和理论基础值得探索。
首先,模型的架构优化是一个关键的研究方向。通过设计更为高效的网络结构,我们可以使模型更好地捕捉数据中的特征和规律。
其次,模型的训练策略也是提升学习效率的一个重要思路。之前,深度学习技术中的迁移学习(Transfer Learning)和少样本学习(Few-shot Learning)技术,被广泛用于在有限数据下提升模型的泛化能力,那么未来能否有新的类似策略提出?
第三,优化模型的数据处理能力,实现对数据的“深度挖掘”,也是提升学习效率的有效途径。比如数据增强技术能通过对原始数据进行智能化的变换和扩充,使模型在训练过程中接触到更多“虚拟”的样本,进而学到更多的知识。
如果能实现数据的高效学习,那么此时Scaling law就不是唯一的指导原则了,不过目前学术界和产业界没有很好的解决方案,所以我目前看这条路走起来估计不会很顺畅。
03.利用大模型来生产合成数据
利用数据来训练大模型,然后让大模型再产生数据,人工审核后成为高质量的数据,最后喂给大模型进行训练,好家伙,闭环了!
合成数据(Synthetic Data)是指通过数学模型、算法或随机过程生成的数据,这些数据在某些方面与真实数据相似,但并不是从真实环境中直接采集的。合成数据通常用于数据预处理、模型训练、数据集增强等场景。
它的优势在于:
- 可控性:合成数据可以根据需求进行定制,例如调整数据规模、数据分布、样本数量等,使得数据更符合特定任务的要求。
- 安全性:在某些敏感领域,如医疗、金融等,直接使用真实数据可能会涉及到隐私和安全问题。而合成数据可以避免这些问题,同时也能达到类似的效果。
- 成本低:合成数据不需要花费大量时间和资源进行采集和数据标注,因此成本相对较低。
所以目前利用大模型来生产合成数据是解决数据短缺的主要探索方向,而且可行性较高。比如包括Llama3,它也在训练数据集里加入了合成数据。还有包括Open AI的还没发布的 Sora 模型,它的生成其实也是一个合成的思路。
不过我们也需要明白一点:合成数据的生成虽然为解决数据稀缺提供了一种有效的思路,但在实际应用中仍然面临许多挑战。举个例子,与生成对人而言真实的数据相比,生成对AI模型而言真实的数据要难得多。假设你想把一个人的音频片段“添加”到一个汽车/道路噪音的音频片段中,使得音频听起来像是在嘈杂的汽车里说话。你有1000小时的语音训练数据,却只有1小时的汽车噪音。如果反复使用相同的1小时汽车噪音,尽管听这段音频的人可能无法分辨出重复的噪音,但算法可能会“过拟合”这1小时的汽车噪音。这意味着算法在处理新的音频片段时,可能无法很好地泛化到不同的汽车噪音环境中。对于一些复杂场景(如恶劣天气、长尾物体等),虚拟数据与真实数据的分布可能存在显著差异,导致虚拟数据在真实场景中的效果有限。
一个比较成功的例子是DALLE 3和Sora的做法,因为你要训练多模态模型,DALLE 3得有文本对应的图片,Sora得有文本对应的视频,必须得是成对数据。所以Open AI的工程师把已经存在的、人工标好的“文本-图片”或“文本-视频”数据对里的文本部分用AI模型扩写,改得更详细、更丰富一些,然后再用扩写后的“文本-图片”/“文本-视频”合成数据去训练模型。所以它们用的合成数据其实不是靠机器完全自由生成的,而是在已有人工数据的基础上进行了进一步的改造,所以这算是一种“半合成数据”的做法。
我们不靠人工想要完全利用机器实现“全合成数据”,不受限制地生成所需的训练数据,这点就相当困难了。因为人产生的数据其实是有主题和自然风格的分布的,机器还难以做到自由生成并完全符合人类数据的分布,不过要想让Scaling Law继续发挥作用,实现最终的AGI,那么“全合成数据”肯定是未来的方向。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
