【万字长文】虚拟人漫谈|技术篇
了解虚拟人赛道产品相关信息请看我的前两篇文章:《虚拟人漫谈|开拓:产品篇(上)格局与环境》、《虚拟人漫谈|开拓:产品篇(下)产品与商业》。
01 虚拟人,新科技下的创世神话
想象一下,你是一个创世神,担负着创世的KPI,你要做点什么?
我想,你大概应该先构思好主角,再扔给主角一个世界。
主角首先是一个拥有大脑躯干四肢,眼睛鼻子嘴的生物,姑且把这种生物叫做“人”。
但仅仅这样还不够,每个人的身上还要加一点点灵魂,有的多一点风趣幽默,有的多一点审慎优雅,各有不同,才会丰富多彩。
最后,再给他们一个世界,赋予天空和大地,赋予植被和海洋,再来点可爱的小动物……这个创世任务的MVP,就差不多算完成了。
在人类的幼年时期,各个文明流域都相对独立地出现了创世神话,上古中国有盘古开天辟地,女娲抟土造人;《圣经》中有上帝七天创世,并在第六天创造了亚当夏娃的故事……一直以来,人类都对自己的起源充满了好奇与想象,创世神话,是人类对自身起源浪漫探索的开始。
这种对自身充满探索和向往的欲望一直固化在我们的集体潜意识里,而在科技日渐发达的今天,我们正逐渐尝试用科技来拟合一个“人”的诞生过程,这就是“虚拟人”的概念。

“虚拟人”并不是一个常规意义的有血有肉的人,而是一个综合了多类技术而形成的,生活在数字世界中的“人”。虚拟人概念的催生,也正是得益于近些年来CG技术、人工智能技术等的不断发展。虚拟人是一个技术的综合体,是人类用科技拟合自身的浪漫探索与想象。
02 虚拟人是什么
虚拟人是什么呢?人类理解一个事物的时候往往喜欢首先探究它的概念。对于虚拟人这个概念,很多机构试图给出它的定义,或者是分类,比如有的认为可以分成“虚拟人”、“数字人”、“数字虚拟人”,有的认为可以分为“meta hunman”和“AI being”等等。
我本人没有那么权威,但也想给虚拟人下一个定义,这个定义是什么呢?那就是:当我提起“虚拟人”这个概念的时候,你的脑海里浮现出了什么?Bingo,那就是虚拟人!
其实,虚拟人本质上是对人的一种模拟,对“人”这个概念的解构,能帮助我们更好地认识虚拟人。如何赋予虚拟人更有价值的生命,也许就要先从对“人”的探索开始。接下来,我们就从一个“人”本身来出发,看看人由哪几个关键的部分组成。搞清楚了这个之后,针对每一个部分,再来聊一聊,虚拟人是如何通过多种多样的技术来拟合人类的。
03 「身体+灵魂」+「世界+人设」
何为人?针对这个问题,我先抛出一个我认知里的公式:
人=「身体+灵魂」+「世界+人设」
身体和灵魂,灵与肉,这是组成生命的唯二两个部分,我想这个结论应该是大多数人都能认可的。我这里说的身体可以译为body,主要是指我们自身上“有形”的那一部分,包括我们的躯干、四肢、手脚,以及看的见的表情动作等;相对的,灵魂可以译为soul,这里主要是指我们身上那些“无形”的部分,例如我们的感知、意识、知识、感情等。
有了身体与灵魂,我们可以说已经得到了一个“人”了,但仅仅这样还是不够的。马克思说过,“人是一切社会关系的总和”。一个人的社会属性很重要,对于虚拟人来说也是如此。
对于虚拟人的社会属性,我也把它简单概括为两个方面:世界和人设。世界代表外部环境,虚拟人也需要一个生活的空间,一个舞台,这是外界给TA的;人设代表内部环境,虚拟人也需要有社会属性,需要合适的外貌、技能、性格……这是TA回馈给外界的。
那么,以上这四个元素是如何作用的,从技术的角度又是如何实现的,且听我细细道来。
1. 身体
从唯物的角度来看,身体是人必不可少的组成部分。这里,我把身体这个元素进一步拆成两个要素,分别是:静态+动态。
1)静态
指人的外观,对于真人而言,外观有高矮胖瘦、肤色、男女等区别,而对于虚拟人而言,还增加了“画风”这一维度,虚拟人的外观可以包括二次元、3D、超写实,甚至赛博朋克等,目前,虚拟人的外形主要靠美术设计师和3D建模师共同实现。
2)动态
指人的动作,一般来说,人的动态分为三个主要部分:
- 躯体动作
- 面部表情
- 口型动作
这一点对于真人和虚拟人都是比较类似的(虚拟人暂时不涉及动耳朵、动头皮这种高级艺能)。虚拟人的动态主要依靠驱动技术来实现,目前驱动技术主要有真人驱动和AI驱动两种流派。
2. 灵魂
就像电影《心灵奇旅》里演的那样,灵魂也是一个人的重要组成部分。对于虚拟人来说,灵魂主要是通过AI技术来打造的。这里,我把灵魂也分成了几个要素:
1)感知
感知是人最生物性的层面,主要是和我们的五感有关,具体来说就是看、听、说三个部分,分别由眼睛、耳朵、嘴来负责,结合到AI能力,就是CV、ASR、TTS。
2)认知
认知是在感知的基础上进一步形成的思考能力,这里我把认知能力进一步分成两个方面,分别是理性的认知能力和感性的认知能力,其中,理性的认知还可进一步分为知识储备、理解、决策三个层级的能力,对应于AI中的KG、NLP、ML;感性的认知主要指的是利用AI构建的情感识别功能。
3)创造
就像我们小学的时候会先学习汉字,学习造句,再学习写作文一样,创造是更高一级的智力活动,只有在进行过大量的学习之后,才能进行有效的创造,人如此,虚拟人亦如此,虚拟人的创造主要依赖于生成类的AI算法来进行输出。
3. 世界
对于一个人,我们要给他一个世界,一个舞台,这个人才算有了一个全面展示自己的空间,虚拟人亦如此,这个世界就是虚拟人生活的空间。关于世界,这里我也(强行)分成两个要素:
1)渲染
渲染就是让这个虚拟的“人”呈现在我们面前,渲染技术分为离线渲染、实时渲染等,渲染技术的选型会直接影响虚拟人的呈现效果,你看到的是4k还是1080p与它有直接关系,渲染技术很大程度上决定了虚拟人演出的舞台效果。
2)终端
虚拟人没有物质性的实体,目前阶段我们必须借助终端才能看到它,现在可以承载虚拟人终端的设备数量越来越多,移动端、IoT、VRAR等都有大量的空间。在未来,虚拟人技术也有可能真正和实体机器人进行结合,变身成真正几乎“以假乱真”的智能体。
4. 人设
我们总说明星有人设,其实每个人都有人设。人生在世,谁又能时时刻刻保持自己永远都是一个耿直的real boy/real girl呢?我们在面对家人、朋友、同事时,甚至会换上不同的人设。对于虚拟人而言,这也是一样的,而且由于虚拟人现在还比较「笨」,不能像真实的小精灵鬼们一样多种人设无缝切换,因此,对于每一个虚拟人而言,打造一个专有场景的专有人设至关重要。
人设就是面向社会和公众在特定场景下所表现出来的品牌、IP等,一个好的人设,不仅仅需要合适的外形风格、肢体动作,也需要合适的知识储备、谈吐风格、甚至创作风格。人设不是一个技术类的概念,它更偏向于产品和运营方面。
运营好一个IP类虚拟人,和经纪公司运营一个明星的道理是一样的,甚至有更大的难度,而拥有好的人设IP运营sense的企业在虚拟人赛道甚至元宇宙时代里脱颖而出的概率也是极大的。
以上,就解释清楚了我自己对于虚拟人定义的逻辑框架:
人=「身体+灵魂」+「世界+人设」
其逻辑脑图如下图所示
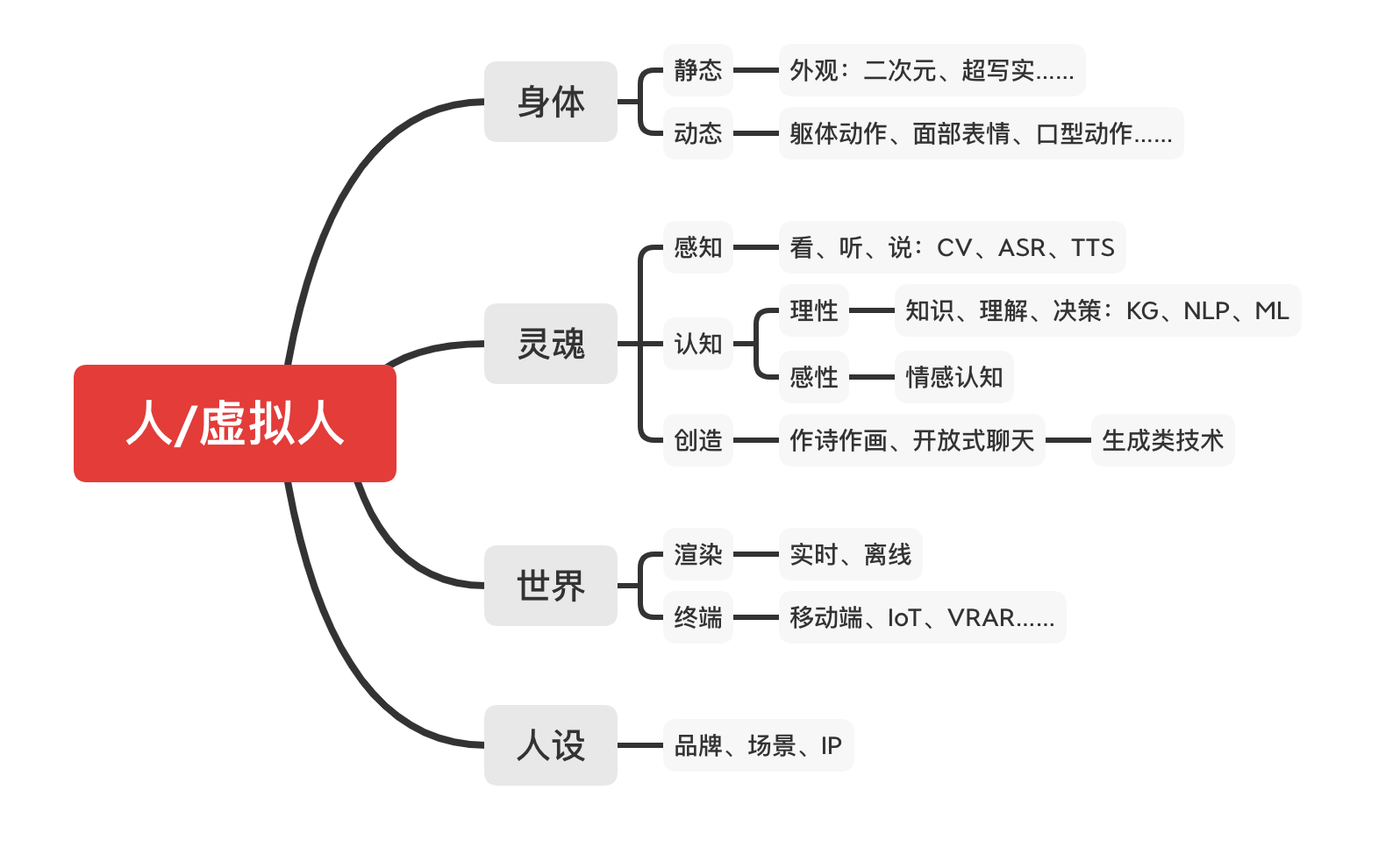
接下来,我将依照这个逻辑分别简单展开陈述一下相关的技术向内容。
04 身体
「身体」又被我进一步分成了两个要素:静态与动态。静态就是我们的外壳,包括头、躯干、四肢等,动态就是身体的动作,面部的表情,说话时的嘴形等。
对于一个真实的人来说,这一切都是来的自然而美妙,我们的身体由母亲孕育而来,体内有无数的神经细胞控制着每一块肌肉的运动,身体和灵魂是一个有机的整体。但对于虚拟人而言,这一切就没那么自然了,全要倚赖人类的设计。其中,静态外形的诞生主要依赖于各种建模技术;动态的产生则要依赖各类驱动技术。
对于虚拟人而言,想让静态和动态联动起来,二者之间必须的一个桥梁就是绑定,通过对身体各个骨点的绑定,来达到控制各个身体部分动起来的目的,如下图所示:

1. 静态
静态外形的诞生主要依赖于各种建模技术,目前的建模方式主要有以下几种:
- 3D软件建模
- 仪器采集建模
- 自动化建模
建模方式一:3D软件建模
指通过3D建模软件来人工塑造出3D的模型,该方式人工制作周期较长,但效果可控,是目前应用最广泛的建模手段。
常用的3D建模软件有很多,主要有以下几类:
- 传统3D建模:3Dmax、Maya、blender等
- 雕刻软件:zbrush、blender等
- 程序化建模:houdini等
其中,传统3D软件主要负责制作低模,雕刻软件可以辅助制作高模,限于篇幅原因,这里不做过多展开,总之,低模的特点是面数少,视觉效果一般,但所占计算资源少,运行速度快;高模则正好相反,面数多,视觉效果好,但占用资源多,容易卡顿。
下面这块砖头很好的解释了高模和低模的区别(雕刻软件的「雕刻」二字含义就是精细的雕出坑坑洼洼的细节,使其看上去更真实)。

现代建模流程中一般会使用“烘培”的方法,简单来说就是底层结构是低模,但是在低模的面上贴上高模的贴图,类似于「披着羊皮的狼」,达到一种看上去视觉效果很好,运行速度又快的效果。
手工建模有多种工作流程,主要的可以分成传统模式、次世代模式两种:
- 传统模式:大概流程是先作低模,然后直接手工画贴图,结构上的材质等信息全靠人手作画,这种方式只能做出比较卡通的模型,做不出特别精致的效果。
- 次世代模式:大概流程是先做低模,然后用zbrush等软件做雕刻使其变成高模,然后再把各个面的贴图拆分,再烘焙回去,这样一来,模型结构是低模的,上面的贴图是逼真的高模渲染出来的,因此看上去既真实,又不卡内存,次世代模式可以做出非常精致的模型。
3D建模技术涉及到计算机图形学、3D美术等多方面技术,限于篇幅和水平原因,这里叙述的比较浅显,日后如果有更多研究我会再进行更细致的补充。
开个小差:很多小伙伴应该都听说过美术生会经常画人体素描,还会因此产生一些羞羞的联想,但其实我作为一个超业余美术爱好者,深知人体真的是很难画的,其难点主要有三:
- 人体真的很不规则,可以设想,你能见到的大部分物体都是比较规则的,想想你身边的床、柜子、桌椅板凳……出于工业设计与制造的方便,大多我们用到的物品都是由立方体、圆柱体等基本图形以及其组合而演变来的,而人体却是复杂的骨骼外面包裹了复杂的肌肉,既不是全方的也不是全圆的,哪怕是一条简单的胳膊也包含了微弱的高低起伏,因此是非常难以概括的。
- 人的动态非常丰富,一个人的肢体活动是非常多变的,而多变的肢体活动带来的是肌肉的拉伸、挤压和复杂的透视,因此,想做出非常自然的虚拟人姿态难度是很大的,需要对各个肌肉及其联动的数据权重进行大量的微调,是需要非常丰富的建模及绑定经验的。
- 人对人的敏感程度非常高,这就好比画一棵树,只要我画了一堆树叶上去,你可以完全不在乎树叶画的是不是和窗外那棵一模一样,只要能看出来是树,就可以了;对于人就不是这样了,世界上有这么多人,却很难找到两个长得一模一样的人,人对于人脸的敏感程度非常高,稍微不像就能看的明显,因此对于一些高保真的明星偶像的建模,也需要强大的美术功底才能支撑。
建模方式二:仪器采集建模
相比于手工建模,仪器采集建模是通过仪器扫描的方式来进行建模。该方式成本较高,目前一般用于影视特效制作等领域居多。仪器采集建模技术分为静态扫描建模和动态光场重建:
- 静态扫描模型技术是目前的主流,可具体细分为结构光扫描重建与相机阵列扫描重建等。
- 动态光场重建技术是目前重点发展的方向,不仅可以重建人物的几何模型,还可一次性获取动态的人物模型数据,并高品质重现不同视角下观看人体的光影效果,具有高视觉保真度。
许多关于虚拟人的行研报告里都有关于以上两种技术的详细介绍,例如国海证券的《数字虚拟人——科技人文的交点,赋能产业的起点》中,「图表:主要建模技术概况」就概括的很好,有兴趣的读者可以找来看看。
建模方式三:自动化建模
自动化建模主要包含以下一些方式:
- 图像采集建模:通过采集照片来还原人脸 3D 结构
- AI建模:利用AI算法直接生成人脸、身体等的建模方式
自动化建模技术目前还不算特别成熟,建模结果到直接商用还有一段距离,不过,该类技术会大大降低建模的人力成本和时间成本。目前已经出现了一些支持虚拟人创建的工具化平台,如英伟达的 Omniverse Avatar、Epic Unreal的 MetaHuman Creator 等。尤其是2022年6月最新发布的Unreal的MetaHuman Creator ,其效果令人惊艳。
这些平台的建模精度虽不足以建立超高质量的模型,但能够大幅降低虚拟人建模的成本,让普通人也能快速拥有属于自己的虚拟形象。随着技术的发展,自动化建模的效果还会变得越来越好。在未来,这种方式有可能直接实现虚拟人生产流程的自动化,和元宇宙入口、虚拟分身、千人千面等概念联系起来,拥有巨大的想象力。
2. 绑定
绑定技术是动态与静态联动的桥梁,简单来说就是给做好的虚拟小人在关键位置打上点,方便后续通过驱动关键点来驱动小人做出各种表情与姿态。关键点的位置遍布全身,例如躯干上,手肘、手腕、膝盖、脚踝等关节就是关键点;面部的眼皮、嘴角、眉头等关键位置也要打上关键点,让虚拟小人“眉飞色舞”。
笔者自己曾学过简单的Maya骨骼绑定,简单来说,躯体部分的绑定的流程如下:
- 创建骨骼(就是做个火柴人出来)
- IK等方式添加骨骼的联动(例如脚踝抬起时膝盖也会自然弯曲)
- 为骨骼蒙皮(就是把虚拟人的「血肉」和「骨骼」的关键点一一对应起来)
- 调整权重(让虚拟人在运动时肌肉的形变更加自然)
面部的绑定流程和躯体整体而言差不多,只是面部需要人做很多表情,做表情的时候诸如眼皮、嘴形、眉头、苹果肌等都会进行联动,因此面部绑定所需要的关键点更多更复杂。
随着技术的发展,工业流程的演进,绑定技术也在向着更便捷、更高效、更智能、边际成本更低的方向发展,关于这一点可以参看的国海证券《数字虚拟人——科技人文的交点,赋能产业的起点》中的「图表:绑定环节的技术革新」。
3. 动态
完成以上两步之后,我们就可以通过驱动的方式让虚拟人动起来。整体而言,虚拟人可以分为交互型、非交互型两种。
非交互型主要通过设置预制动作来让人物动起来,类似于动画片的原理,不能实现实时互动。
交互型虚拟人是我们的重点。交互型虚拟人需要靠驱动技术来驱动动作、表情、嘴形,这样,虚拟人才能做到根据外界刺激进行反馈的效果。交互型数字人的驱动可以分为传统驱动方法和智能驱动方法。
1)传统驱动方法
可以分成光学动作捕捉、惯性动作捕捉、Track 设备+IK 算法的动作捕捉等方法,现阶段,光学式和惯性式动作捕捉占据主导地位。传统驱动方法一般需要”真人+动捕设备”来进行驱动,这个后台的真人又称为“中之人”
2)智能驱动方法
智能驱动是指通过AI技术,例如CV、ASR、TTS等来对虚拟人进行驱动,该方式造价成本低,可以无限拓展,在未来有很大的想象空间。不过现阶段AI技术有限,一般需要结合合适的场景,通过较多垂直领域的训练才能达到商业可用的效果。
关于这一部分,我同样参考了国海证券《数字虚拟人——科技人文的交点,赋能产业的起点》中的「图表:主要捕捉技术特性对比」和「图表:主要驱动技术概况」。我觉得这份材料的很多总结简洁到位,是一份非常不错的参考材料。
05 灵魂
其实用“灵魂”这个词只是为了表达“身体与灵魂”这一概念的方便,其实我更想表达的是类似于“头脑、意识”这样的一个抽象的概念,与身体的“物质性”相对应,它属于人的“非物质”那一部分,我姑且把它称为“灵魂”。关于「灵魂」我想分为3个层面来介绍,分别是感知、认知和创造。虚拟人的「灵魂」主要需要依赖各种AI技术来进行赋能。
1. 感知
感知是人最生物性的层面,主要是和我们的五感有关,具体来说就是看、听、说三个部分;目前,直接的知觉、嗅觉等技术还不成熟,也许未来的脑机接口、体感设备等技术会在这些方面有所突破。
虚拟人的感知技术主要依赖于人工智能,在感知层面,人工智能技术当下整体而言是成熟的,不成熟的部分短时间内也难有重大突破,因此一般需要结合具体场景,通过合理的产品设计和精细化运营等方式来达到可用的程度。
看:计算机视觉CV
计算机视觉技术可以帮助虚拟人“看”到物体,并作出一定程度的简单分析。计算机视觉技术主要依靠深度学习中的CNN网络,一般的技术应用均为CNN的变种。CV技术主要有以下几类应用。
1)分类
给定一张输入图像,图像分类任务旨在判断该图像所属类别,例如,检测出一张照片中的主角是猫还是狗等,常用的分类网络包括AlexNet、VGG-16/VGG-19、ResNet等
2)检测
在图像分类的基础上,给出图像中的目标包围盒,常用的目标检测算法包括:
- 基于候选区域的目标检测算法,如R-CNN、Fast R-CNN、Faster R-CNN等
- 基于直接回归的目标检测算法:如YOLO、SSD等
3)分割
可以进一步分为语义分割、实例分割,均可理解为更加精细的检测任务,常用算法包括Mask R-CNN等。
下图非常形象地表示出了CV的几种关键任务,分别是:
- 分类
- 检测
- 语义分割
- 实例分割
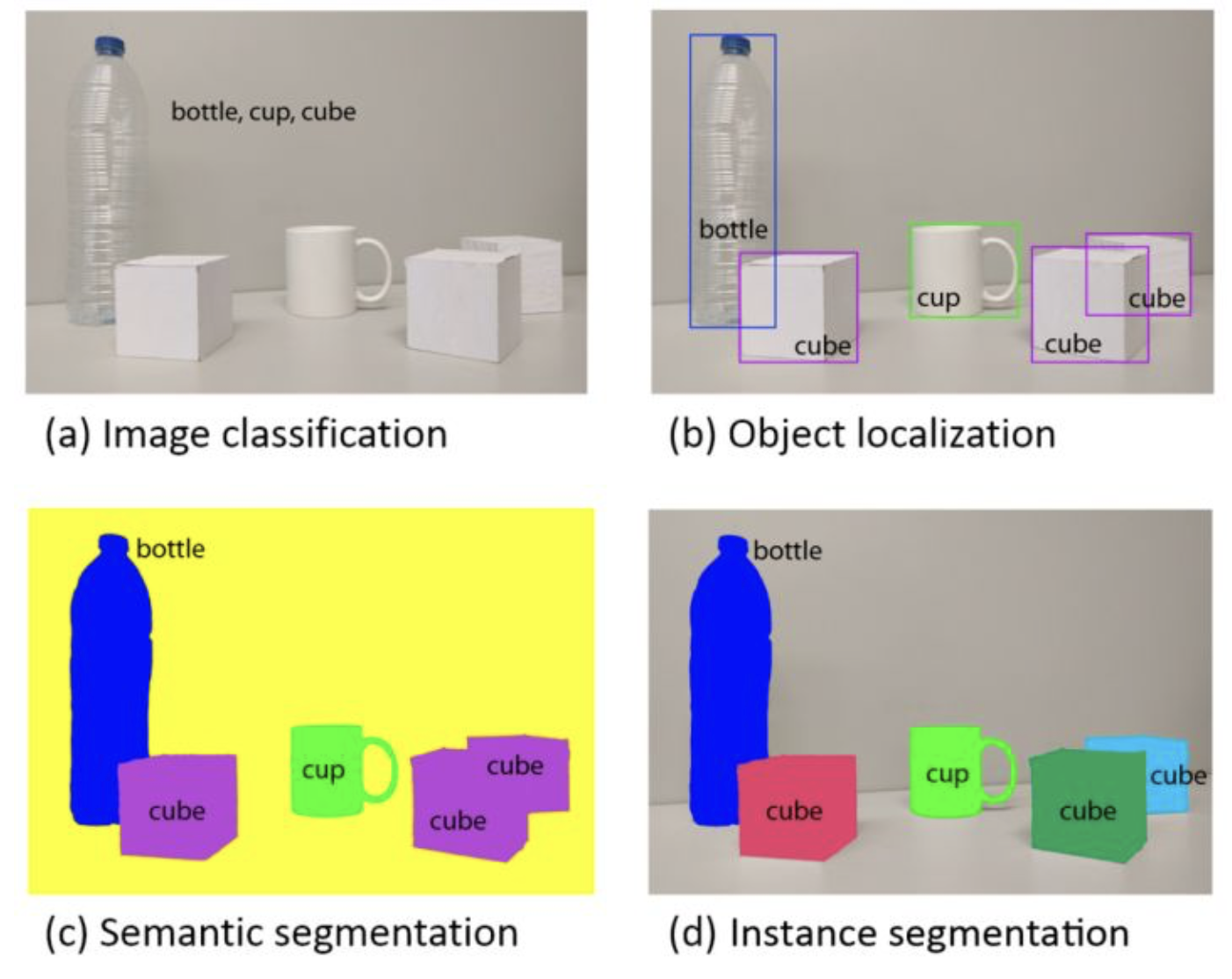
CV类技术有非常广泛的应用,例如人脸识别、姿态识别、障碍物识别等,这些具体的应用技术均可以和虚拟人赛道进一步结合来满足虚拟人的不同应用场景。
听:语音识别ASR
将听到的声音转化成语言的技术,主要分为声音接收和声音识别两个部分。
声音接受部分主要依赖于硬件、环境及声源,一般来说,较高级的声音接收设备、噪音较小的环境,发音标准且音量适中的声源均会提升声音接收的质量。
声音识别部分主要依赖于机器学习及其中的深度学习等AI技术,主要可分为传统方法和端到端方法:
- 传统方法:需要先提取声音信息特征,例如MFCC、LPCC等,这里主要涉及信号处理相关知识;提取特征后再采用HMM、语言模型等综合得出识别结果。
- 端到端方式:主要依托于深度学习技术,由于语音本身是具有时序性的(倒放的语音很难听懂),因此语音识别主要依托以RNN为基础的时序类深度学习模型,例如其衍生出的LSTM、GRU等,来完成语音到文字的转化工作。
说:语音合成TTS
把文字转化成语音播放出来的技术就是TTS技术,能形成自然、流畅、动听的声音是TTS技术所追求的目标。
从技术的角度来看,TTS系统主要分为前端系统和后端系统:
前端系统负责对文字进行分析,并形成一份“发音指南”,里面包括每个字的读音音素、连读、重音、停顿、多音字读法等,这份“发音指南”就像一个发音“说明书”,会传给后端。
后端系统按照前端生成的“发音说明书”,负责把声音合成出来,目前主流的后端合成技术有两大类,分别是“拼接法”和“参数法”。
- 拼接法:先通过真人录制声音,再根据“说明书”把需要的声音片段拼合起来,这种方法优点是声音本身自然动听,缺点是人力成本高,且流畅度容易出现问题。
- 参数法:用声音信号的参数,如基频、频谱等来表示声音,将“声音说明书”中每一个音素的“参数”找出来,合成对应的声音;参数法的优点是成本低,缺点是机械感比较明显,不够自然,不过该方法会随着技术发展效果越来越好,应用范围也会越来越广;目前比较主流的参数法一般是使用端到端的方法,例如Tacotron2、WaveNet等。
2. 认知
认知是在感知的基础上进一步形成的思考能力,这里我把认知能力进一步分成两个方面,分别是理性的认知能力和感性的情感识别能力。
理性认知能力
1)知识:知识图谱KG
知识主要依赖于知识图谱技术。知识图谱是给知识形成的一个以三元组
实体<—>关系<—>实体
为核心的逻辑图,例如以中国城市为主题的逻辑图,就是下列形态:
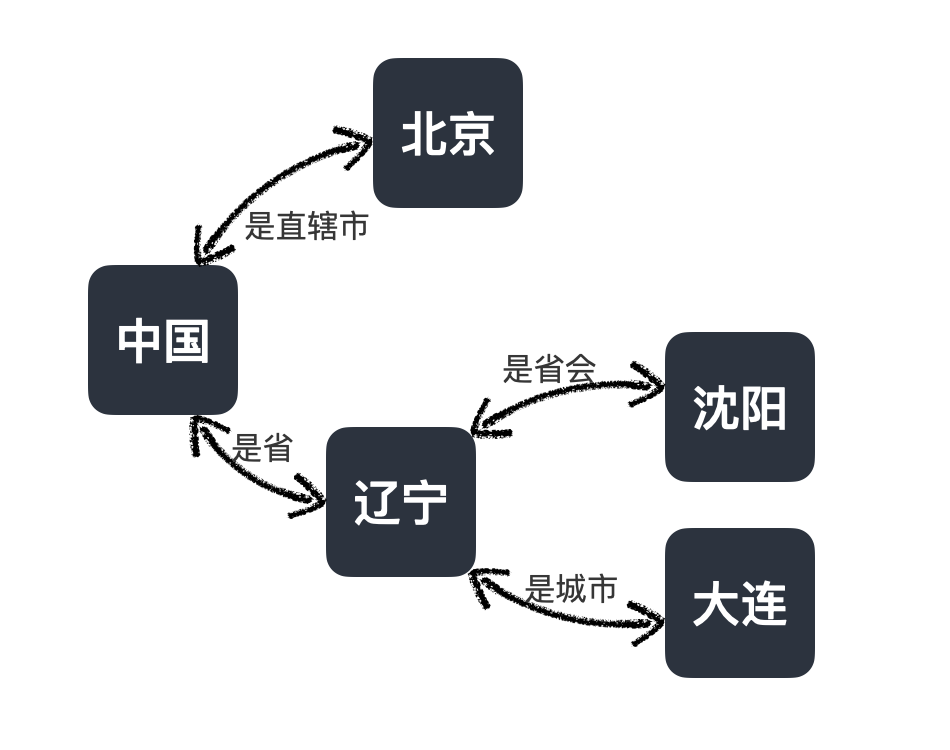
其中,“中国”、“北京”、“辽宁”、“沈阳”等都是实体,“是直辖市”、“是省”、“是省会”等就是关系。
知识图谱可以在任意知识领域运用,例如金融业有银行理财知识图谱、保险知识图谱等;农业领域有动植物知识图谱、农作物知识图谱等;一个好的知识图谱就是一个逻辑清晰的知识宝库。
知识图谱可以以图数据库、三元组数据库等形式进行存储。如果把知识图谱“喂”给一个虚拟人,该虚拟人就有了这个方面的丰富知识。例如,银行业务导引虚拟人就需要非常丰富的银行业务知识,文旅导游虚拟人就需要对导游相关知识非常了解……
知识图谱能快速赋予虚拟人以某一方面的专业知识,堪比《西游记》中的孙悟空吃掉一本书立刻就能掌握书中内容了。知识图谱的完善对于虚拟人的应用意义非凡,而知识图谱本身技术难度不大,其完善主要的门槛在于对于垂直细分行业的深度理解。
2)理解:NLP
通过感知,虚拟人可以获得外界的信息。通过CV「看到」的信息,通过ASR「听到」的信息,都可以转化成语言文字的形态。但仅有感知还是不够的,虚拟人不仅要能获取信息,还需要理解这些信息所代表的真正意图,明白感知到的信息的含义,才能做出下一步的动作。
NLP技术的全称是自然语言处理技术,重点就是理解语义信息,主要包括词法分析、句法分析、语义分析、情感分析等几个部分。通过NLP技术,可以做以下事情:
- 对一句话进行分词(主要针对中文等语言,英文就不用了)
- 分析出每个词的词性,判断是名词还是动词,是形容词还是副词等
- 分析出句子的语法结构,例如主谓宾等
- 分析出各个部分的施事受事关系,例如“我打你”,“我”是施事,“你”是受事
- 通过语气词、“喜欢”、“讨厌”等关键词分析出句子的情感倾向
通过以上种种环节,虚拟人便可以通过NLP技术来理解感知到的信息的含义,识别出信息的意图,便于后续做出进一步的反馈等交互动作。
3)决策:数据智能ML
决策能力是人的一项重要素质,对于虚拟人来说,也可以通过AI的方式提升决策能力,而这一能力的提升主要依赖的就是各种数据智能模型。
简单来说,数据智能就是通过搜集某一问题的大量历史数据,再通过机器学习的某个算法拟合出该问题的函数模型,并依据函数模型对未来做出预测与决策。例如,可以通过某一产品的历史销量分析出该产品未来的销量走势;可以根据球队的历史胜负情况来预测未来某一场球赛的结果等,宛如那年夏天的章鱼保罗。
常用的可以用于决策建模的机器学习算法非常多,从有无标签可以分为有监督、无监督、半监督;从任务类型可以分为分类、回归、聚类、时序预测等。经典的机器学习算法很多,例如决策树、支持向量机、XGBoost等等,篇幅原因不做具体展开,感兴趣的读者可以看一看周志华老师的西瓜书。
对于数据智能任务而言,模型其实并不难,现阶段真正难的是是否有足够多的有价值的数据。互联网、金融等企业相对而言有效数据的收集意识较强,但很多传统企业,收集数据的意识还较弱,目前也正在数字化转型当中。随着数字化转型的进程,虚拟人也会有越来越多的应用。
情感识别能力
人不仅需要理性,也需要感性。亲情、友情、爱情,人与人之间的交往往往是感性大于理性的。对于虚拟人而言,除了理性方面的知识、理解、决策等能力,对于情感的把握也是应该具备的品质。能够进行情感识别、情感反馈的虚拟人,在目前还是蓝海的陪伴型虚拟人赛道有着巨大的用户价值和商业价值。
情感识别是一项综合的能力,例如,通过CV技术,虚拟人可以分辨人的表情是开心还是难过;通过ASR技术,虚拟人可以通过声纹来分析说话人的说话语气是高兴还是压抑,甚至是愤怒;通过NLP技术,虚拟人可以分析说话人说话的内容中,是否含有强烈的表达态度的语气词,例如“喜欢/不喜欢”、“垃圾”、“太赞了”……
心理学家罗伯特·普拉切克提出了情绪轮,内含8种基本情绪,可以作为情绪识别标签设计的依据。
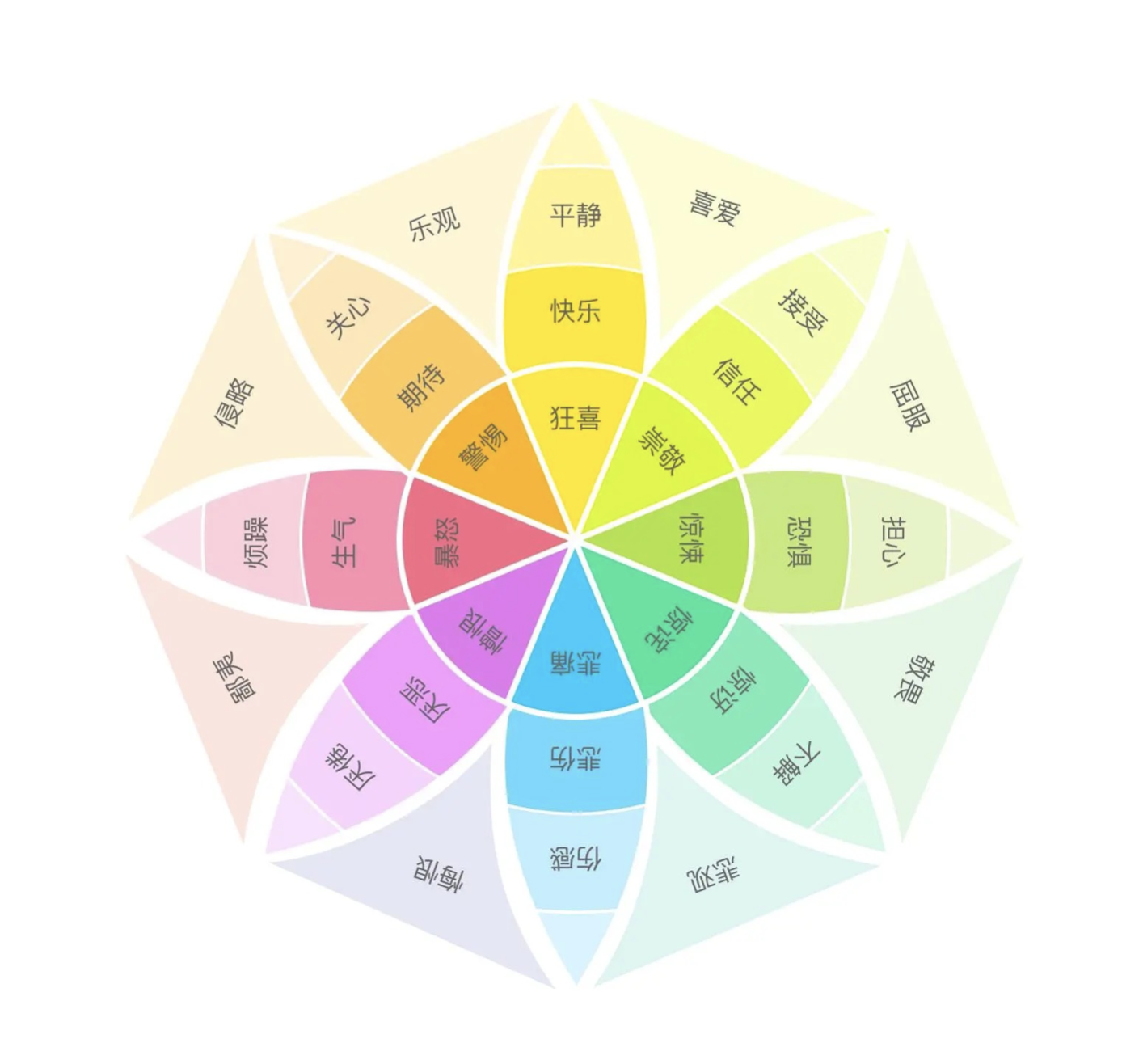
情感识别的能力目前已经在舆情控制、课堂教学等领域得到了一定的应用,但整体而言现阶段还不够成熟,还有巨大的探索空间。
3. 创造
就像我们小学的时候会先学习汉字,学习造句,再学习写作文一样,创造是更高一级的智力活动。只有在进行过大量的学习之后,才能进行有效的创造,人如此,虚拟人亦如此。
目前,“创造”主要是用在虚拟人的创作领域,例如AI作画、作诗、写新闻稿、开放式聊天等等,主要依赖的是以GAN为基础的生成式模型。
整体而言,创造类技术目前成熟度不高,仅在一些规范性比较强的领域如新闻稿等有一些成功案例,更多的应用还集中在概念展示阶段,距离真正大规模商用,还有一段距离。距离产生美,这也给虚拟人未来的潜力提供了巨大的想象空间。
06 世界与人设
之所以分成「身体+灵魂」、「世界+人设」,是因为前两个代表个体,后两个代表外界。而在后两个元素中,「世界」是外面给我们的,是由外而内的,人设是我们给外面的,是由内而外的,美妙吗?非常美妙。
1. 世界
世界,就是虚拟人生活的周围环境。在有了一个虚拟人之后,我们还需要给它一个载体,一个舞台,让虚拟人走到台前来发挥它的价值。构建虚拟人世界的技术,我想谈两个点,分别是渲染和终端。
1)渲染
渲染,就是把做好的模型呈现在屏幕上的过程,或者说需要通过数学计算的方式,把做好的模型变成计算机屏幕上一个个像素点的显示RGB值,来完成实际显示的过程。渲染主要涉及到的技术是计算机图形学,这一过程需要大量的关于顶点位置、颜色、光照等的计算,也会消耗大量的计算资源。
渲染主要可以分为离线渲染和实时渲染,其中,离线渲染主要用在电影、广告等可以提前做好无需交互的场景里,允许花费较长时间,因此效果很好,但成本也很高;实时渲染主要用在游戏、直播等需要实时互动的场景里,对时间比较敏感,因此效果略弱于离线渲染。
Unity和Unreal以往都是用来制作游戏的游戏引擎,二者都是实时渲染的利器。虽说比不上离线渲染的效果,但二者的制作水平也在不断升级,目前新出的Unreal5,其能够达到的渲染效果已经非常优质,实时渲染的效果正在一步步向离线渲染逼近。

(注:本图来自国海证券《数字虚拟人——科技人文的交点,赋能产业的起点》)
另外,近些年来发展的PBR技术对于虚拟人的发展也至关重要。PBR 是基于真实物理世界的成像规律模拟的一类渲染技术的集合,它使得渲染效果突破了塑料感。该项技术使虚拟数字人皮肤纹理变得真实,进而有助于突破恐怖谷效应。常见的几款 3D 引擎,如 UE4,Unity 3D 5等,均有了各自的 PBR 实现。
实时渲染技术的发展可以让虚拟人在交互的环境下提升用户体验,对于VR、AR等赛道的普及与发展有极大的助力。
2)终端
当前,虚拟人没有实体,是需要依托屏幕来显示的,因此虚拟人需要生活在终端里,虚拟人如果有实体,那就不叫虚拟人,叫机器人了。其实,现在已经有材料等领域的科学家在研究非常类似于人表皮组织的材料,以期待能做出几乎以假乱真的“人形机器人”,该项技术近期也取得了一定的突破性成果。2022年6月,日本东京大学宣布,世界上首次成功开发出人工培养的“活”皮肤覆盖的手指型机器人。但该类技术距离真正成熟还有很遥远的距离,而且也面临着社会伦理等方面的巨大挑战。
总的来说,最近一段时间,虚拟人还是要深度依赖电子终端的。随着科技的发展,虚拟人能够活跃的终端种类也越来越丰富,我简单总结了一些我能想到的各类终端,分类并不严谨,只是一个大致的罗列:
- 常规终端:手机端、PC端、电视大屏端
- IoT:智能家居、智能座舱等终端
- 产业终端:银行导览、商场导购等
- 新终端:VR、AR、裸眼3D全息等
2. 人设
最后,再来聊一聊人设。
和上面的内容相比,人设是一个非技术的概念,按说不应该放在「技术篇」来讲。但是它偏巧又很重要。我们每个人都有一个最本真的“我”和一个社会的“我”,我们面对不同的人会带上不同的面具,这一点对于虚拟人来说是一样的。在技术整体水平基本无法拉开差距的时候,对于一个虚拟人产品而言,更重要的就是是否有一个好的人设。
不同场景、不同设定的虚拟人,其人设是完全不同的,这给产品、运营、技术都带来了很大的挑战。
好的虚拟人一定是一个好产品。一个好的产品,有三个要素是必不可少的,分别是敲门砖,护城河,生命线。敲门砖决定门槛,护城河决定优势,生命线决定盈利。对于虚拟人而言,这三个概念可以这样理解:
1)敲门砖
敲门砖就是好的人设。虚拟人对于人设的塑造非常重要,如果是一个虚拟偶像,那就需要好的IP、靓丽的外形、活泼的肢体语言,甚至是唱跳、创作等能力;而如果是一个银行的虚拟员工,TA就应该像万千打工人一样,简约、专业,可靠……总之,是否有一个和场景搭配的外形设计,是否有足够切合的性格设计,是否能够依托于一个IP或者品牌,都对虚拟人的后续运营工作至关重要。
2)护城河
优秀的人设,要结合扎实的产品设计和优质的技术实现才有可能达到。不同的人设,其产品的细节设计也是不同的:一个“小女孩”的人设说话一般是俏皮的,一个职员的人设说话一般是专业亲切的,这对于产品话术的设计提出了考验。
从身体外形的角度,虚拟人可以分为二次元、类人、超写实、未来科幻等不同风格;从人格灵魂上来讲,一个银行引导型虚拟人需要具备丰富的金融行业知识、一个虚拟偶像需要具备唱歌跳舞,甚至是歌曲创作等能力;一个陪伴老人的虚拟人,可能需要丰富的医疗、保健方面知识和对情感的感知与回馈……
人设的打造既要满足产品的需求,又要兼顾到技术的边界……可以说,一个成功的虚拟人IP的打造,是非常不易的。
3)生命线
对于任何一个偶像类的强人设型虚拟人,其二创能力非常重要,二创能力可以让用户自发参与其中,形成优质的生态圈,同时也对后续的商业化变现有巨大增益;好的二创离不开运营的引导支持,这对于虚拟人来说也至关重要,可以说,二创能力就是虚拟人产品的生命线,决定了虚拟人产品是石沉大海还是强势出圈,是否能可持续发展。
关于人设,很多人认为虚拟人的一个优势就是不会翻车,毕竟近期劣迹艺人太多,很多公司都因为劣迹艺人受到了影响,虚拟人似乎是一个零差评零绯闻的不错选项。但是其实,对于虚拟人来说,运营翻车的例子也比比皆是,这也对虚拟人的运营人员提出了巨大考验。
07 趋势&边界
虚拟人赛道是一个技术的综合体,任何一项技术的不完善、不成熟,都制约着虚拟人的“类人”程度。总的来说,虚拟人有三条技术路径:
- 纯人工
- 人工+AI
- 纯AI
纯人工的方式成本过高,纯AI的方式技术暂不支持,目前基本采用的是人工+AI的方式,但随着科技的进步,这一流程中的AI部分占比会越来越多,虚拟人整体的制作流程也会成本更低、时间更短。
对于虚拟人赛道的发展,我们当下要做的事情是:
- 明确技术边界,并知道不同环节不同技术下的效果、成本和收益
- 找到合适的场景,通过场景本身的制约、细分领域的打磨来完成应用
- 积极拥抱技术创新
边界代表当下,趋势代表未来,我在这里想浅盘一下主要的技术,并对未来进行一些分析。
1. 边界与当下
1)传统方法仍有局限
建模(maya、3Dmax等)、驱动(中之人动捕)、渲染(Unity、Unreal等)方面,已有的非AI类的工具、技术均已较为成熟,但依旧存在着一些问题,例如成本较高、制作周期长、实时渲染效果有限且对设备要求高、过于依赖中之人等。
AI等智能化、自动化等技术的发展正在改变以上领域的流程,未来随着智能化和自动化的发展,建模、驱动、渲染等工作会朝着成本更低、时间更短、门槛更低、效果更好的方向发展。成本的下探至关重要,成本及门槛下探到一定程度,虚拟人的应用场景才会由B端过渡到C端。
2)AI能力有待提高
AI能够赋予虚拟人以大脑,AI技术水平的发展直接决定了这个虚拟人是否“弱智”。目前,AI能力的成熟度尚不平均,感知类技术如CV、ASR、TTS等技术已经能够做到较好的水平,一些AI公司如科大讯飞等也均有相关能力的提供,成熟度较高;而认知能力需要深度的业务知识加成和大量的训练数据支撑;情感类能力、创作类技能目前尚不成熟,距离大规模商业落地还有一段距离,目前需要依赖精细化的产品设计和运营。
3)其他需要关注的点
我们需要关注的点不仅仅是AI、CG等高度相关的技术,对于周边的技术例如基础设施建设、VRAR技术、芯片及算力、边缘计算能力等的发展,也需要高度重视;同时,偏产品和运营维度来说,对于IP设计、人物设计、二创运营等能力,也需要引起足够重视。
2. 趋势与未来
未来虚拟人相关技术的发展将会有几个大的趋势:
- 视觉效果更加美观、流畅、炫酷,这依赖于计算机图形学、硬件计算能力、显示设备、建模及渲染工具等的发展。
- AI等智能化技术发展,赋予虚拟人越来越聪明、人性化的大脑,越来越能够像一个真实的人一样和人类交流,去体察、决策、陪伴。其中,AI要向两个方向重点发展,一是具体行业的know-how积累,二是情感型陪伴能力的提升。
- 工作流朝智能化、自动化方向发展,流程缩短、成本降低,若能端到端的生成可用的虚拟人,将为虚拟人的低门槛大批量制作提供可能。
- 随着VR、AR、IoT等赛道的发展,虚拟人可以活跃在越来越多的终端上,随之带来的就是更多的应用场景和能力挑战。
- 当成本与门槛足够低时,就有了人均一个甚至人均多个虚拟人的可能。在元宇宙中,虚拟人可以作为NPC、也可以做真人的第二分身,之后无论是结合千人千面、还是结合NFT等概念,都有了无限的想象空间。
- 未来有可能出现真正的类人机器人形态的人工智能体,届时虚拟人将不仅能够生活在屏幕中,还会有一个实实在在的躯体,但就像克隆技术一样,这样的技术虽然能够代表AI、材料、医疗等诸多学科的科技前沿,但是否符合伦理道德,是否能够商用,将是一个大大的问号。
在网上,看到了百度李士岩的一段话,很有趣。他认为:数字人是基于计算机平台的交互载体,将呈现段落式发展。
当下所处的平面计算时代,主要以服务型与表演型数字人应用为主,下一个阶段是更大的时代,暂时定义为空间计算时代。空间计算时代计算平台呈现的信息不再是平面的,而是实时三维的,届时核心用户的行为大概会有社交、获取商品、信息消费、获得服务四类,那么能够提供个性化交互、能提供情绪价值和内容价值的虚拟分身是必选项,能够提供人文情感关怀、又能保证效率的服务型数字人则是另一种应用形态。在未来的空间计算时代,一定会产生比现在平面计算时代更大的市场。
08 结语
一不小心就废话了很多内容,其实之所以想写这个主题,原因就是我对虚拟人这个赛道很感兴趣。而之所以对虚拟人赛道感兴趣,主要是以下几个原因:
一是从专业的角度来讲,我过去一直是工作在AI赛道的,人工智能的本质是对智能体的模拟,虚拟人技术是对人工智能技术的综合应用,也是人工智能体的初级阶段,这让我对TA产生了极大的好奇,很想一探窥之;
二是出于个人的一点私心,本人虽是理科生,但对人文科学与艺术领域一直非常感兴趣;虚拟人赛道和许多科技类赛道不同,更像是科技与人文的交点,在科技发展的同时也充斥了关于艺术、文化、伦理等的讨论,让我心向往之;
三是一点无厘头的想象,我从小就是一个幻想能力极强的小孩,被二次元深深吸引,我小的时候很喜欢看《数码宝贝》这类动画片,倒是挺希望有一天能和这些电视里的英雄说说话的。就当下而言,试问如果熊大熊二喜羊羊能开口说话,和孩子来一番互动教学,是不是也美滋滋的?
出于以上一些原因,我尽个人的绵薄之力对虚拟人进行了一个调研,并且想把调研的内容进行梳理,希望能给读者带来一点点收获。
对于虚拟人这个赛道,我自己也是一个初学者,目前尚不是行业内的工作者,以上内容及观点主要是通过自学以及基于网络材料的调研形成的。水平非常非常有限,很希望各位业内人士能够指出我的错误和不足,我都会悉心听取。
十分感谢大家。
参考材料:
- 国海证券《数字虚拟人——科技人文的交点,赋能产业的起点》
- 头豹研究院《2022年中国虚拟人产业发展白皮书》
- 天风证券《虚拟数字人:元宇宙的主角破圈而来》
- 华丽智库《全球时尚虚拟人物研究报告》
- 中银证券《虚拟人行业深度研究》
- 中国传媒大学《中国虚拟数字人 影响力指数报告》2021年度
- 艾媒咨询的《2022年中国虚拟人行业发展研究报告》
- 头豹研究院《2022年AI驱动虚拟人行业概览》
- 量子位《虚拟数字人 深度产业报告》
- 安信证券《元宇宙之中国优势:虚拟数字人,分发与流通环节的新战场 》
- 安信证券《虚拟数字人的长短期展望:IP 与赋能》
- 达摩院《阿里小蜜数字人互动决策的探索与落地》
PS:部分资料源自网络,目的是为了更好的说明所讲的问题,如有侵权可以联系我进行删除,不胜感激。
本文作者 @进击的唐猜 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
