如何让 NPC 更像真人?
编辑导语:NPC是游戏中不可或缺的一部分,它为玩家打造了一个有生命力的虚拟世界。与玩家串联起了游戏世界。但传统的AI还存在着很多缺陷,以致于背上“智障”的骂名。如何能够制作出优秀的游戏AI(游戏NPC)⽆疑是游戏开发者苦苦探求的问题,作者对如何NPC更像真人作出了分析与总结。
游戏中的⾮玩家⻆⾊作为游戏的重要组成部分,对于游戏的可玩性的塑造有深远的影响。但是⻓久以来驱动这些⻆⾊的⼈⼯智能技术⼀直存在巨⼤的缺陷,⽽使得这些游戏中的⼈⼯智能饱受“⼈⼯智障”的骂名。这不仅极⼤地影响了游戏的体验,也制约了游戏开发者设计游戏的思路。
随着深度强化学习技术的发展,⾃动化地制作智能体成为了现实,但是这些智能体往往“勇猛”有余,“⼈性”不⾜。本⽂从⼈⼯智能技术研究与实践的⻆度探讨了如何能够制作出像人一样操作的游戏智能体。
一、为什么游戏需要AI?
⾃电⼦游戏诞⽣之始,为了能够为玩家打造⼀个有⽣命⼒的虚拟的世界,游戏中往往都会添加诸多的⾮玩家⻆⾊(Non-Player Character, NPC)。他们最早可以追溯到⻰与地下城的桌游(DungeonsDragons)[1],在这类桌游中通常需要⼀个游戏主持⼈来扮演⾮玩家的⻆⾊提供给玩家决策的选择和下⼀步的指引。
他起到了串联起玩家与游戏世界的作⽤,甚⾄可以说整个游戏的进⾏节奏都由他来掌控。

⽽到了电⼦游戏中,这种⾮玩家的⻆⾊的职责就更加丰富了。他们或许是任务的发布者,或是关键剧情的⼈物,或是玩家要挑战的对⼿,抑或仅仅是玩家擦肩⽽过的路⼈。
但是他们串联起玩家与游戏世界的作⽤依然没有变。如果没有他们,游戏设计者是很难构建出⼀个充盈丰富的虚拟世界的。
很多经典的NPC由于背负着丰富的故事剧情,成为⼀代玩家⼼中宝贵的回忆。⽐如⼤家熟知的《超级⻢⾥奥》中的碧琪公主(Princess Peach),就是玩家操控的⻢⾥奥⼀直去努⼒营救的对象。
尽管碧琪公主在游戏中更像⼀个花瓶NPC,与主⻆的交互并不多。但是正是由于她的存在,赋予了《超级⻢⾥奥》整个游戏的原始驱动⼒。
更有甚者,诸多游戏NPC的原型就是取材于我们的真实⽣活。
⽐如《魔兽世界》中的暗夜精灵⼥猎⼈凯莉达克(CayleeDak),她的原型就取材于现实⽣活中的⼀个猎⼈玩家,由于她经常在游戏⾥帮助别⼈⽽备受⼴⼤玩家欢迎。
后来她因⽩⾎病不幸逝世后, 游戏中的公会专⻔为她举办了盛⼤的虚拟葬礼以纪念她的乐观友善。
葬礼上数百名玩家集结在暴⻛城的英雄⾕,⼀路游⾏⾄暴⻛城的花园区,并按照美式习俗鸣放了21响礼炮。《魔兽世界》官⽅得知后便专⻔为她设计了这个NPC和相关的剧情任务,为游戏增添了不少温度。

NPC可以说是游戏中不可或缺的⼀部分。是他们点亮了整个游戏虚拟世界,⼀⽅⾯让玩家更好地融⼊游戏,另⼀⽅⾯传达了游戏的态度。但是随着游戏创作者的野⼼越来越⼤,玩家对游戏的要求也越来越⾼,单纯只会读剧本的NPC已经很难满⾜构建⼀个优秀虚拟世界的要求。
这些NPC的⾏为必须变得更加丰富⼀些,能处理的问题必须更复杂⼀些才能让这个虚拟世界变得更有趣,更吸引玩家。其实早在1950年,游戏AI的概念就被引⼊到了电⼦游戏中[2],就是为了⽤⼈⼯智能的技术来设计出更智能的NPC,因此游戏AI也常常成为了游戏NPC的⼀种代称。
但是传统的游戏AI制作技术存在着诸多缺陷,使得这些游戏中的⼈⼯智能⼀直饱受⼈⼯“智障”的骂名,这不仅极⼤地影响了游戏的体验,也制约了游戏开发者设计游戏的思路。如何能够制作出优秀的游戏AI(游戏NPC)⽆疑是游戏开发者苦苦探求的问题。
二、为什么现在的AI是智障?
为什么现在的AI很多时候总是看上去像个智障呢?其实背后的主要原因是驱动AI的模型太简单了。⽬前主流的游戏AI都是基于⾏为树这样的规则系统实现的,它的复杂度有限,并且规律易寻。反观⼈类⼤脑⾥这么多神经元错综复杂的交汇着,⾄今科学家们也没完全解开⼤脑的秘密。

我们以经典的《吃⾖⼈》游戏为例来介绍⼀下如何⽤⼀个规则系统实现游戏AI。吃⾖⼈游戏的玩法如图所示,就是要控制吃⾖⼈尽可能多地吃掉散布在迷宫各处的⾖⼦。但是其中的难点在于,会有能够伤害吃⾖⼈的幽灵在其中游荡,吃⾖⼈为了得到更多的⾖⼦不得不躲避幽灵的进攻。

那么如果要⽤规则系统设计⼀个吃⾖⼈的AI,该怎么做呢?⾸先,我们需要考虑吃⾖⼈可能会遭遇哪些状态?⽽当遭遇这些状态后,吃⾖⼈⼜可以采取怎样的操作?不同的操作⼜可以把吃⾖⼈引⼊怎样的状态中去?当把这些问题答案罗列出来之后,我们就能够组织出吃⾖⼈在不同状态下应该如何决策的规则系统,如下图所示:
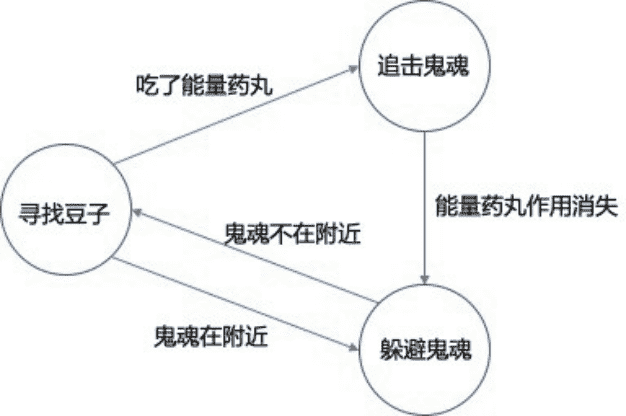
在“寻找⾖⼦”状态下,可以设置让吃⾖⼈随机游⾛,如果看到⾖⼦就去吃掉它的⾏为。⽽当发现幽灵正在附近的时候,就进⼊到“躲避幽灵”状态,这时可以将吃⾖⼈的⾏为设置为远离幽灵,⽽⽆视⾖⼦的存在。
当幽灵脱离了之后,状态⼜可以转换到“寻找⾖⼦”。如果吃⾖⼈很幸运地吃到了⼀颗能量药丸,那么他就获得了击败幽灵的能⼒,此时状态可以转换为“追击幽灵”……
从上⾯的吃⾖⼈的例⼦中我们可以看出,基于规则的AI系统是有明显的缺陷的。⾸先,如果游戏场景⽐较复杂或者说对智能体的⾏为和能⼒有⽐较⾼的要求,会有⾮常复杂繁多的状态。
分解出这些状态、编写状态中的⾏为、设计状态之间的转移条件⽆疑会带来巨⼤的游戏开发成本。但是游戏开发的成本是有限的,开发⼈员的精⼒也是有限的。
其次,随着游戏的设计越来越复杂,分解这些状态、编写规则系统也已经变得越来越不太可能了,更别说开发⼀个栩栩如⽣的规则AI系统了。
但是,最重要的⼀点是当⼈类与这些AI进⾏交互的时候,可能会产⽣很多意料之外的状态,⽽这些规则系统是完全不具备泛化性的,对于这种意外状态只能表现出智障⾏为。

三、为什么游戏AI需要像⼈?
随着游戏这么多年的发展,游戏的形态和玩法都变得越来越丰富。但是我们可以发现,在那些特别吸引⼈的游戏中,有两种类型的游戏是特别突出的。
⼀种是构建了⼀个引⼈⼊胜的虚拟世界,⾥⾯的⼈和事是那么真实,以⾄于让我们深深沉浸其中。⽐如在《荒野⼤镖客》中,当你漫步在⼩镇的街道上,也许会看到⼀个妇⼈倒在地上哭泣求助,如果你过去帮助她,她会突然变脸掏出枪指着你说“抢劫!”。
这种看似对玩家的当头⼀棒,却⼜是⾮常符合那个时代背景的事件真的让玩家⽆法⾃拔。

⽽同样也是打造了⼀个⻄部场景乐园的《⻄部世界》更是吸引了⽆数的权贵到其中游玩,它本质上就是⼀个有⾼度拟⼈AI的动作探险游戏,只不过⾥⾯AI的智能和外形都进化到了⼀个远⾼于现在电⼦游戏的形态。
另外⼀种是构建了⼀个合适的与真⼈在线竞技的场景。多⼈在线对战变得越来越热⻔,其背后的逻辑也可以解释为在游戏消费内容有限的情况下,玩家还是希望更多地与更聪明的⼈类进⾏游戏,因为⼈类的创造⼒和游戏⽣命⼒是旺盛的,即便在这个过程中可能要忍受谩骂与不快。如果我们⽤⾜够像⼈类玩家的AI来填充,这类游戏本质上和第⼀类也没有区别。
总⽽⾔之,就是游戏中的⻆⾊越像⼈,就越能给玩家带来吸引⼒。它并不⼀定需要像⾼⼿玩家⼀样将游戏玩得滚⽠烂熟,但是要能做出⼈类才会做出的反应,即便那些反应是不理智的。
因此游戏⻆⾊⾏为的智能性对于打造整个游戏的游戏性、以及对玩家体验的塑造有着⾄关重要的作⽤。但是就像前⾯提及的⾏为树⼀样,这么多年过去游戏中诞⽣了⽆数的AI,但是⼤多数还是会被玩家认为不像⼈,只会固定的套路,让玩家对游戏兴趣⼤减。
四、怎么判断AI像不像⼈呢?
那怎么才能判断AI到底像不像⼈呢?这个问题并不好回答,具体到不同的场景⾥,答案可能都不⼀样。⽐如机器可以很好地将⼀段复杂的中⽂翻译成英⽂,但是⼜很难听懂“我去!我不去”“那么到底去不去呢?”这样的对话。那么这个机器到底像不像⼈呢?
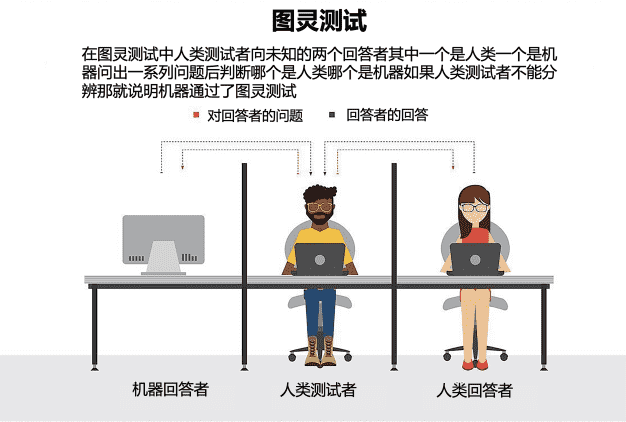
实际上,在⼈⼯智能诞⽣之初,计算机之⽗图灵(AlanTuring)就讨论过这个问题,并提出了著名的图灵测试(TuringTest)[3]作为⼀种解决⽅案。如下图所示,假设有⼀个⼈和⼀台机器被隔离在⼀个⼩房间⾥,我们看不到⾥⾯到底是⼈还是机器,但是我们可以通过⼀些装置与他们进⾏沟通。
通过⼀系列提问,我们需要判断究竟哪个是机器哪个是⼈,如果我们的误判⽐例超过30%,那么就可以说机器通过了图灵测试。图灵认为通过图灵测试的机器具备了和⼈类⼀样的智能。
在游戏中,我们其实也希望AI能够达到类似这种以假乱真的效果,⾄少在游戏的某个具体任务上,AI能够通过图灵测试,让玩家觉得AI是鲜活的,有⽣命⼒的。
虽然图灵测试对于判断AI像不像⼈直观并且可靠,但是却并不实⽤。⾄少在优化AI的过程中,使⽤这样的⽅式去评判成本太⾼了。因为我们很难直接把⼈当成AI的优化器,让⼈判断了AI做的像不像⼈之后,再反馈到AI的模型上,让AI去修改参数,再让⼈类判 断。
这样⼿把⼿的“⼈⼯”智能,对于⼈的精⼒消耗⼤不说,也很难覆盖到所有可能的场景。如何更好地度量AI的拟⼈性依然是⼀个⾮常重要的研究课题,但是最基本的我们可以从⼈类的⾏为数据和AI的⾏为数据的对⽐中罗列出哪些⾏为是不像⼈的、哪些是像⼈的,从⽽逐渐去优化不合理的部分。这对于⼀个有限的问题空间⽽⾔并不是⼀件⾮常困难的事情。
五、从⼈类的⾏为⾥学习
接下来我们就要考虑如何得到⼀个像⼈的AI模型。既然像⾏为树这种总结经验式的AI制作⼿段对于提升AI的智能性⾮常困难,⼀个最直接的想法便是能不能直接从⼈类过往的游戏⾏为⾥学习经验呢?答案是肯定的。⼈类在玩游戏的时候,能够产⽣⼀系列的游戏状态-游戏操作对,这些游戏状态-动作对我们称为⼈类示例。如果将⼈类⼀局游戏的示例按顺序组织起来,形成⼀条⾏为轨迹⼀条游戏的序列tr,即:
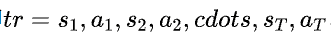
那由m条⼈类示例轨迹组成的数据集可以记为:

从⼈类⾏为⾥学习的⽬标可以认为是希望AI在游戏中的表现与⼈类的表现越接近越好。如果能够从这种数据⾥估计出⼈类的策略分布,并且引⼊⼀个回报函数来刻画这个表现程度(⽐如游戏的技巧得分、游戏的竞技得分等的综合表现)。那么模仿⼈类⾏为的学习⽬标就可以表示为找到⼀个AI策略,使得它尽量能够取得和⼈类接近的回报,即:
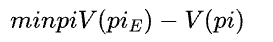
六、行为克隆
如何求解这个问题呢?⼀种直接的想法是通过⼈类的示例数据集:
来估计⼈类的⾏为策略pi* ,这种⽅式也被称为⾏为克隆(Behavior Cloning)[4]。⼀种常⽤的估计⽅法就是最⼤似然估计(Maximum Likelihood Estimation)。假设要求解的策略模型表示为pitheta(theta是模型的参数),那么它产⽣⼀个数据样本(s,a)的似然即可以表示为pitheta(a|s)。最⼤似然估计可以转换为最⼤化对数似然,即:
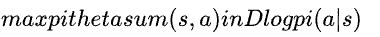
这是⼀个凸优化问题,我们可以直接使⽤⼀些强⼤的机器学习学习⽅法来求解。⽐如,近⼏年⻜速发展的深度学习,由于⾮常强的学习拟合能⼒⽽被⼴泛应⽤到图像、⾃然语⾔处理等领域,它同样可以帮助我们来拟合⼈类的⾏为。
不过值得注意的是,在进⾏机器学习的时候,每个样本都是作为独⽴的样本去对待的(机器学习的样本独⽴同分布假设),但是样本实际上都是从序列数据中收集⽽来,并不满⾜独⽴同分布的假设。
这就会导致策略模型如果在某⼀步发⽣了⼀丁点⼉的错误预测,那么这个错误会被⼀直累积下去,导致AI遇到⼀些⼈类从来没有遇到过,并且AI也没有被训练过的场景。这时候AI的表现就会⾮常糟糕。
如下图所示,我们可以很直观地从⼀个赛⻋游戏的例⼦中明⽩,假如在学习⼈类的赛⻋轨迹的时候,在弯道的控制上出现了⼀定的误差,那么这个误差会被⼀直延续下去,直到赛⻋撞出赛道。但是如果没有⼈类撞出赛道之后的补救⾏为数据,⾏为克隆将很难帮助我们得到⼀个满意的⾏为策略。

不难看出,⾏为克隆虽然简单并且⾼效,但是决策序列越⻓⾏为克隆就越可能累积很⼤的误差,导致后续的决策越来越离谱。如果能够获取⾜以应付各种意外情况的海量⼈类示例数据,那么这个累积误差问题才能得到缓解,但是这⼀点在游戏研发阶段通常都很难满⾜。不然我们只能寄希望于这些累积误差不会导致对游戏致命的影响。
为了解决这个问题,也有学者提出名为DAgger(DatasetAggregation)[5]的⽅法。这个⽅法的基本思想是不断利⽤⼈类来纠正⾏为克隆中出现的错误。具体算法可以描述为:
⾸先将⾏为克隆得到的策略继续与环境交互,来产⽣新的数据
然后将这些数据提供给⼈类,以获得⼈类在这些数据上的⾏为,从⽽得到⼀个增⼴的数据
在增⼴后的数据集上,重新进⾏⾏为克隆,以得到新的策略
重复上述过程
由于在不停和环境交互的过程中利⽤⼈类的知识对数据进⾏了增⼴,DAgger算法会⼤⼤增加数据对状态空间的覆盖度,从⽽减少学习时候的误差。
但是也需要注意,不停地让⼈类提供指导本身也并不是⼀件简单的事情,即便是⼀个狂热的玩家也很难不厌其烦地教AI玩游戏,况且如果游戏⾜够复杂,游戏策略⾜够丰富, 那么DAgger需要向⼈类请教的示例数量同样可能⾮常海量。
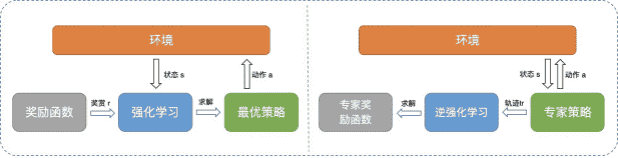
六、逆强化学习
上⼀节中我们提到,藉由⾏为克隆学习得到的策略⼀般会受到累积误差问题的影响,那么有没有另⼀种⽅法能够减轻累积误差问题带来的影响呢?答案是肯定的,这就是逆强化学习[6]。
逆强化学习与⾏为克隆不同,并不直接求解智能体的⾏为策略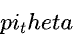 ,⽽是尝试从示例数据集中求解出⼈类所使⽤的奖励函数⽤于解释⼈类策略的⾏为。在使⽤逆强化学习解决模仿学习问题时,我们就可以使⽤强化学习在学到的奖励函数上求解最优的⾏为策略。
,⽽是尝试从示例数据集中求解出⼈类所使⽤的奖励函数⽤于解释⼈类策略的⾏为。在使⽤逆强化学习解决模仿学习问题时,我们就可以使⽤强化学习在学到的奖励函数上求解最优的⾏为策略。
换句话说,⾏为克隆是单纯的“模仿”,⽽基于逆强化学习的模仿学习则是尝试“理解”⼈类⾏为的内在逻辑(奖赏函数),再根据它“学习”⾃⼰的⾏为,⾃然⽐⾏为克隆更容易适应环境中的⼩误差。
在逆强化学习中,最核⼼的部分就是根据示例数据集求解得出的奖励函数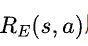 ,我们通常要求其满⾜这个性质:当使⽤这个奖励函数时,使⽤⼈类策略获得的累积期望奖赏,⽐使⽤其他任意策略所能获得的累积期望奖赏都要多。换句话说,我们认为⼈类策略是在使⽤这个奖励函数时的最优策略,也就是:
,我们通常要求其满⾜这个性质:当使⽤这个奖励函数时,使⽤⼈类策略获得的累积期望奖赏,⽐使⽤其他任意策略所能获得的累积期望奖赏都要多。换句话说,我们认为⼈类策略是在使⽤这个奖励函数时的最优策略,也就是:
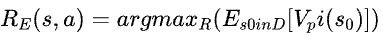
得到⼈类策略使⽤的奖励函数后,我们就可以使⽤这个奖励函数构建⼀个新的任务:
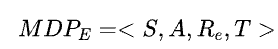
并在这个新的任务上⽤强化学习来求解最优的⾏动策略pi*。根据我们之前对性质的描述,在这个任务上表现最好的⾏为策略就是⼈类策略 ,即:
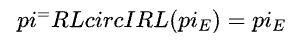
通过这种⽅式,我们就得到了⼀个能够模仿⼈类的AI策略。
逆强化学习虽然能够解决⾏为克隆中存在累积误差的问题,但它本身也存在诸多问题,⽐如逆强化学习假设⼈类总是做出最优的选择,这个假设通常在模仿⼈类⼈类的问题中显得过强了。
此外,逆强化学习问题本身并不是⼀个良定义的问题,通常有多个可能的奖赏函数能够满⾜要求,例如对任意状态-动作对都给出0值的平凡奖励函数可以成为任意逆强化学习的解。
七、对抗式模仿学习
⾏为克隆和逆强化学习作为两种模仿学习的⽅法,都存在⼀定的缺陷,我们⾃然就会考虑是否有⼀种⽅法可以将⼆者的优势结合起来,既能直接求解⾏为策略,⼜不会受到累积误差问题的影响呢?
在逆强化学习中,我们学习了⼀个奖励函数, 我们可以⽤这个奖励函数来评估智能体策略与⼈类策略的相似度,但是这个奖励函数不能直接指导智能体进⾏⾏动。那么既然智能体的⽬标是模仿⼈类的策略,那么我们是否可以不⽤显式的求出⼀个奖励函数⽤来评估AI策略与⼈类策略的相似性呢?
有没有可能直接⽤“和⼈类⾏为的相似度”这样的指标来引导强化学习对⾏为策略的学习呢?从这样的思路出发,我们就得到了⽣成对抗模仿学习(Generative Adversarial Imitation Learning, GAIL)[7],它通过⽤⼀个评估智能体与⼈类的相似度的函数作为奖励函数的⽅式来对⼈类的策略进⾏模仿。
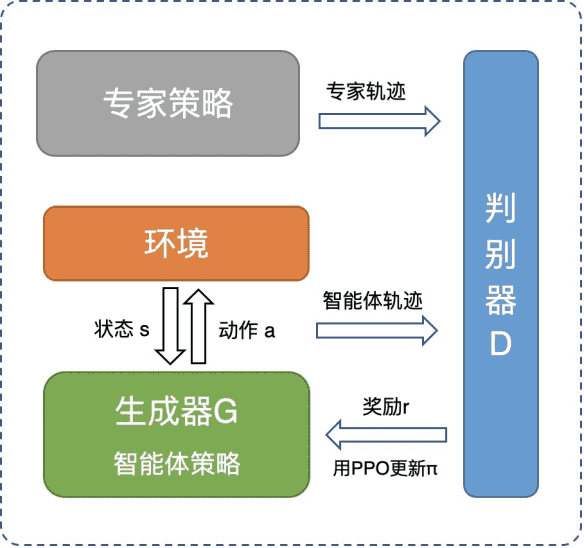
GAIL是⼀种基于⽣成式对抗⽹络的⽅法,与各种使⽤⽣成式对抗⽹络的⽅法相似,它也会构建⼀个⽣成器G和⼀个判别器D,并让⼆者不断进⾏博弈并交替进⾏更新。在GAIL中,判别器D是⼀个⼆分类器,通常是⼀个深度神经⽹络,它的输⼊是状态-动作对(s,a),输出则是⼀个(0,1)区间内的概率值,代表输⼊的状态-动作对由⼈类⽣成的概率。和⼀般的⼆分类任务相似的,每轮训练中我们可以可以简单的通过最⼩化交叉熵损失函数:
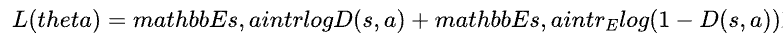
接着对D进⾏更新。
GAIL中的⽣成器G则是智能体的⾏为策略,训练中需要与环境不断交互⽣成轨迹,它会使⽤强化学习⽅法进⾏更新,使⽤判别器的输出作为强化学习任务中的奖励函数。这就意味着,被判别器D认为更像⼈类的⾏为会得到更多的奖赏,因此随着训练的推进会逐渐向⼈类⾏为策略逼近。
⼆者经过多轮迭代最终收敛后,判别器D⽆法区分出真实轨迹与⽣成器⽣成的轨迹,此时我们的⽣成器G 就是⼀个能够有效模仿⼈类⾏为策略的AI策略。
当然,作为⼀种基于⽣成对抗式⽹络的⽅法,GAIL也有与GAN相似的缺点:实际应⽤时需要⼤量经验性的trick,某些情景下很难训练到理想的收敛结果。但由于GAIL能给模型带来的更强的泛化性,以及更少的示例数据需求仍然使它成为了⼀个优秀的模仿学习⽅法。
八、Avatar平台中的模仿学习
Avatar是IEG研发效能部游戏AI研究中⼼团队⾃研的分布式在线强化学习训练框架,已经在如竞速、格⽃、FPS、Moba等多个品类的游戏上进⾏探索和实践,部分游戏AI已经上线。
本章我们重点讨论在真实游戏业务场景中训练强化学习模型的过程中,为什么需要模仿学习,并介绍我们在Avatar训练框架下在模仿学习上做的探索。
1. 真实业务需求
以我们在⼯作中的真实业务场景为例,当游戏业务与接⼊Avatar强化学习训练框架时,除通过AvatarServiceAPI将游戏客户端与训练框架交互接⼝对⻬之外,都不可避免地需要实现下列内容。

特征⼯程:将游戏原始数据转换为形如MDP(state/action)格式的数据,并设计状态和动作的数据内容
奖赏设计:针对当前对局状态和模型预测的动作给出正负反馈
⽹络设计:根据MDP设计对应的神经⽹络结构
经历过的同学⼀定能够体会到被调参⽀配的恐惧,⽽这三项每个都是调参地狱。例如[8]详解了奖赏设计(reward shaping),⽂章有多⻓,说明reward shaping这⼀过程有多困难。
调参⼯作每⼀次微⼩调整都需要数⼗⼩时甚⾄数⼗⽇的验证,⽽指东打⻄的结果太容易使⼈崩溃。
不同于研究领域中RL的重点更多倾向于关注“更⾼的分数、更强的决策”,⽽实际业务中甲⽅爸爸的要求是“⾼拟⼈性、⾼多样性、⾼可靠性、覆盖各个能⼒段”。这⼆者之间的⽬标差距为reward shaping带来了更⼤量的⼯作量。
⻓远来看,⽹络设计在学术界已有诸多的NAS(NetworkArchitectureSearch)相关研究,可以⾃适应的⽣成效果差不多的⽹络结构,与实际业务的相关性较低。
⽽特征⼯程和奖赏设计则都与业务强相关,不仅要对ML/DL/RL有相当的经验,也需要对业务有相应的理解才能训练出甲⽅爸爸满意的、“像⼈⼀样的”强化学习模型。
当有了“模型能够做出像各种各样不同玩家能做出的⾏为”,这⼀普遍需求后,如何利⽤真实玩家⾏为引导强化学习模型训练的想法就会⾃然⽽然地浮现出来。也就是如何利⽤模仿学习,推进现有的强化学习训练进⼀步提升拟⼈性、多样性。
九、Avatar框架内设计
1. Avatar设计简介
以PVE游戏为例,Avatar训练框架核⼼包含了三个服务——Agent Server, Actor Server和Learner Server。核⼼交互、MDP处理⼯作由Agent Server完成,其处理与游戏客户端和另外两个server的交互(如下图所示,红⾊部分由业务⽅实现)当客户端连接后,轮询等待预测请求,并从对应的预测服务中获取结果,返回给客户端。
当积累够⼀定数量的预测数据后,Agent Server将其组装成训练样本发送给训练服务;
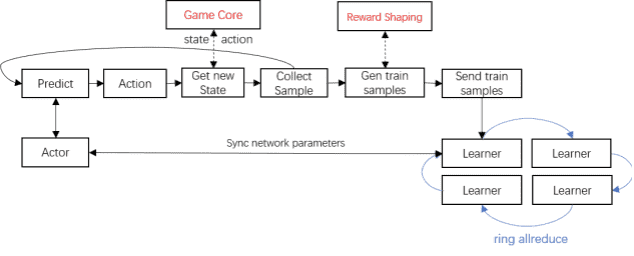
Actor Server预测训练⽹络当前policy返回的动作结果;Learner Server则负责对⽹络进⾏异步训练,并定期同步参数给Actor Server。
本⽂不具体介绍Avatar框架的具体实现⽅式和⼯作原理,详⻅我们的iwiki⽂档[9]以及《Avatar⼤规模分布式训练优化实践》[10]。
2. 辅助⽹络设计
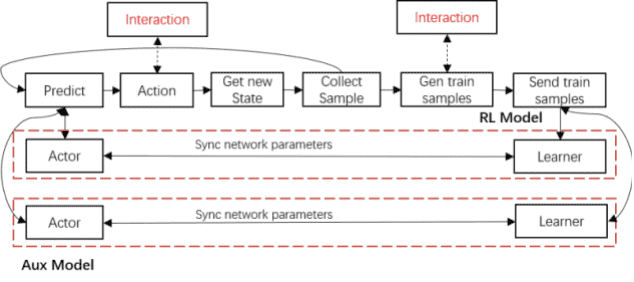
从框架设计⻆度考虑,模仿学习可以理解为利⽤某种监督学习⼿段提升强化学习训练效果的⼀种⽅法,我们将这类⽹络称之为辅助⽹络(Auxiliary Model)。为了降低业务⽅的学习成本,以及尽可能保证框架的模块化、通⽤性,我们完全复⽤了Actor和Learner 模块,仅新增对监督学习模型配置、输⼊数据标准标准定义以及loss function⽀持。
这设计过程中,我们重点处理的依然是模型间的交互流程,以及模型与游戏间的交互⽅式的变化。我们认为,在MDP结构下,辅助⽹络对强化学习主模型训练主要影响位点有以下三处:影响policy action;影响某个state,或state/action组合的reward;增加额外的loss。
由此,我们额外开放了交互接⼝(如下图所示),业务实现代码可以获取每个⽹络的预测结果,并⾃由选择交互时机。
3. 模仿学习实现
具体到模仿学习的实现,我们实现了对抗式模仿学习,模仿学习被认为是“影响到reward的监督学习模型”,主要负责判别当前状态(动作)是否是符合⼈类⾏为的状态(动作)。在实际训练过程中,模仿学习模型和强化学习模型⼀同训练。
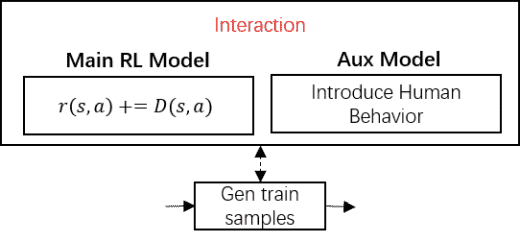
在业务同学侧,使⽤模仿学习仅除了设计⽹络结构之外,仅需要处理主模型在⽣成训练样本时叠加模仿学习输出的奖赏,以及将⼈类⾏为数据引⼊到模仿学习训练过程中即可。
十、模仿学习在竞速类游戏上的探索
我们已经尝试在竞速类游戏上对对抗式模仿学习进⾏了初期探索,将不同赛道地图中使⽤业务中已上线的不同能⼒段模型的录像数据视为模仿学习的⾏为数据。
同时,我们去除了reward_shaping中所有⼈⼯设计的奖赏,仅保留模仿学习输出和最终圈速与⽬标圈速的相近程度作为实际奖赏。
在其中⼀个赛道上的圈速收敛曲线如下图所示:
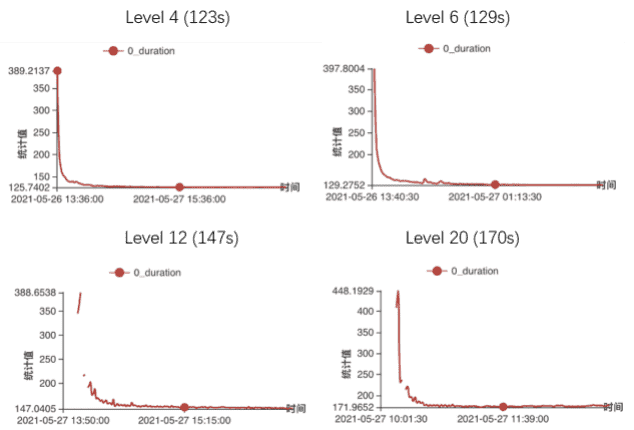
借助对抗式模仿学习,使⽤不同能⼒段位的⾏为数据,最终训练出的强化学习模型能⼒段位⼗分贴近于⽬标能⼒段位,且实际⽐较发现其收敛速度与原始的仅通过reward_shaping收敛效率相当。
在竞速类游戏中初步实现了我们预期⽬标:减少繁琐的奖励调整⼯作量,并实现模型能⼒多样化。
十一、总结与展望
打造⾼智能的游戏AI⼀直是游戏制作中绕不开的话题,但是过去由于技术所限,导致游戏AI的智能⽔平⽐较低,因此游戏制作者天然地考虑了这个缺陷,⽽将游戏的亮点设计在其他地⽅,游戏AI仅仅只起到⼀个补充的作⽤。
但是基于示例的强化学习⽅法让我们看到⼀线希望,就是仅通过少许的⼈类示例数据,也能够让游戏AI获得相当⾼程度的智能。
我们相信在未来,只要能够打造更为拟⼈、更为智能的AI,他们不仅可以帮助我们为玩家打造更好的游戏体验,甚⾄还会对游戏的制作思路和⻆度带来翻天覆地的变化。游戏AI或许会成为整个游戏的最核⼼资产,游戏的玩法也将是由玩家与这些AI来共同定义的。
注释:
⻰与地下城桌游Dungeons&Dragon
第⼀款带有AI的游戏Nim
图灵测试Turing Test
Dean Pomerleau. “Efficient Training of Artificial Neural Networks for Autonomous Navigation”. In: Neural Computation 3.1 (1991), pp. 88–97.
St.phaneRoss, Geoffrey J. Gordon, and DrewBagnell. “AReduction of Imitation Learning and Structured Prediction to No-Regret Online Learning”. In: Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. 2011, pp. 627–635.
RUSSELL S J. Learning Agents for Uncertain Environments[C] // Proceedings of the Eleventh Annual Conference on Computational Learning Theory. 1998 : 101 – 103.
HO J, ERMON S. Generative Adversarial Imitation Learning[C] // Proceedings of the 30th Annual Conference on Neural InformationProcessing System. 2016 : 4565 – 4573.
Reward Shaping https://cloud.tencent.com/developer/article/1693899
Avatar 框 架 iwiki https://iwiki.woa.com/pages/viewpage.action? pageId=612412665
Avatar⼤规模分布式训练优化实践https://km.woa.com/articles/show/522742?ts=1632620082
作者:杨敬文 、姜允执、李昭,IEG研发效能部 游戏AI研究中心;公众号:腾讯研究院(ID:cyberlawrc)
作者 @腾讯研究院
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
