腾讯终究还是出了大模型,测了下感觉还行
今天,腾讯官宣亮相了混元大模型。
6 月中旬,腾讯曾推出了自己面向 B 端行业的 MaaS( Model-as-a-service,模型即服务 )解决方案,方案中包含了很多行业大模型,但没有通用大模型。
现在,腾讯终究还是忍不住了。
这次,知危编辑部也想办法获得了混元大模型的体验资格,下面就带大家看看混元的能力。
首先是常规的对话,我们先看看多轮对话:



以上内容仅能展示连续对话,内容真实性无法验证。
正常的问题是可以一直聊下去的( 与其他同行相同,混元也有最大连续对话数的限制 ),回答的内容也尚可,并且它会知道哪些信息可以说、哪些信息不可以说。
下面我们看看它提供方案的能力:

策略上没有什么太大的问题,考虑得相对周到,还是有一定参考价值的。
再让它生成一个演讲稿:

觉得有些太正式官方了,让他调整了一下:

混元的表现尚可,还是可以起到启发或者生产力工具的作用的。
下面我们再看看它的语义理解能力:

当我们要求进一步解释时,混元应对的也比较好:

除了常规的对话,混元还给出了比较丰富的 “ 特调 ” 应用,叫作 “ 灵感发现 ”,囊括了各个场景下的诸多功能:
我们测试了一下社群营销文案,刚好最近中秋节要到了,看到一些社群在发月饼团购文案,就让混元也试了一下。
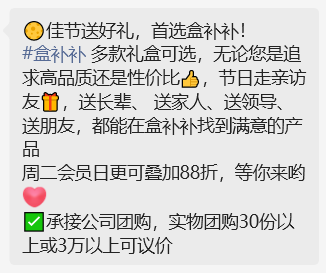
作为对比,我们先找了一下盒马社群关于月饼的社群营销文案看看大概什么样:
混元的表现如下:

感觉味儿还是对的,随便修修改改就能用。
除此之外,还有专门的代码模式和代码解释器。
我们先让混元生成了一段 2048 游戏的代码:


然后再把它生成的代码扔进它的代码解释器功能里,它解释的还行:


好了,编辑部的测试大概就是这么多,总地感觉下来,混元的水平跟国内一线大厂持平,说不上惊艳,但也没掉队,执行各种不同领域任务时的表现在 GPT-3.5 水平上下浮动。
自打 8 月 15 日《 生成式人工智能服务管理暂行办法 》开始施行后,行业开始有了明晰的规范,已经有一批大厂的大模型获得了全量面向公众开放的资格。
这意味着行业迎来了一个成熟的时机:数量不设限的用户可以更好地给大模型提供训练资料,让大模型更快成长。
所以,腾讯大模型的发布,极有可能是看中了这一点。
如此一来,最后一个一线大厂也加入了通用大模型的 “ 大乱斗 ” 中。
希望未来某一天,它们能卷出点让人眼前一亮的东西。
作者:二筒;编辑:大饼
来源公众号:知危(ID:BusinessAlert),提供敏锐、独到的商业信息与参考,重点关注TMT、出海、新消费、新能源。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
