轻松搭建AI应用的三个大模型技术路线
时下聊起AI,想必最热的就是使用AI 的应用(chatGPT,文心一言等)来提升自己工作的效率,比如破局俱乐部,洋哥带领星球2万多人开启大航海,教人使用这一波新起的应用进行赚钱与赋能。
在我的视角来看,当下仍然是前期的红利,现在这趟车就像是凌晨的“高铁检测车”,是先行军,估计在2024年才会迎来真正的爆发。
今天的话题,就相当于大模型应用大爆发前的“闪电”,我们将从技术介绍,适用边界,操作步骤和应用示例来聊聊三个大模型技术路线,帮助你开阔它背后的秘密:
- 指令工程技术
- 表示学习和检索技术
- Fine-tune(微调)技术
01 指令工程技术
谈起指令工程,用过chatGPT,文心一言等等对话式AI应用的你并不陌生,就是通过输入prompt指令,来达到输出你想要的文字,图片或者视频。
更专业的大厂在去年6月爆发式的招收过一批prompt engineer,他们的作用就是不断的调整指令来搭建不同的领域型应用。比如AI心理医生,AI聊天助手等等。
当时我搭建过一个AI苏格拉底,聊起来颇有压力。但聊着聊着就我就发现它不知道自己是谁了,这也是这种技术的限制。
技术难度:⭐️⭐️
适用边界:适用于可以被简洁指令描述的任务,如内容创作(文章、故事、代码)、问题解答、推理分析等。
实施步骤:输入指令词。尽量使用结构化提示词:背景,角色,目标和任务。
应用示例:
02 表示学习和检索技术
表示学习和检索技术是互相配合的两种技术。
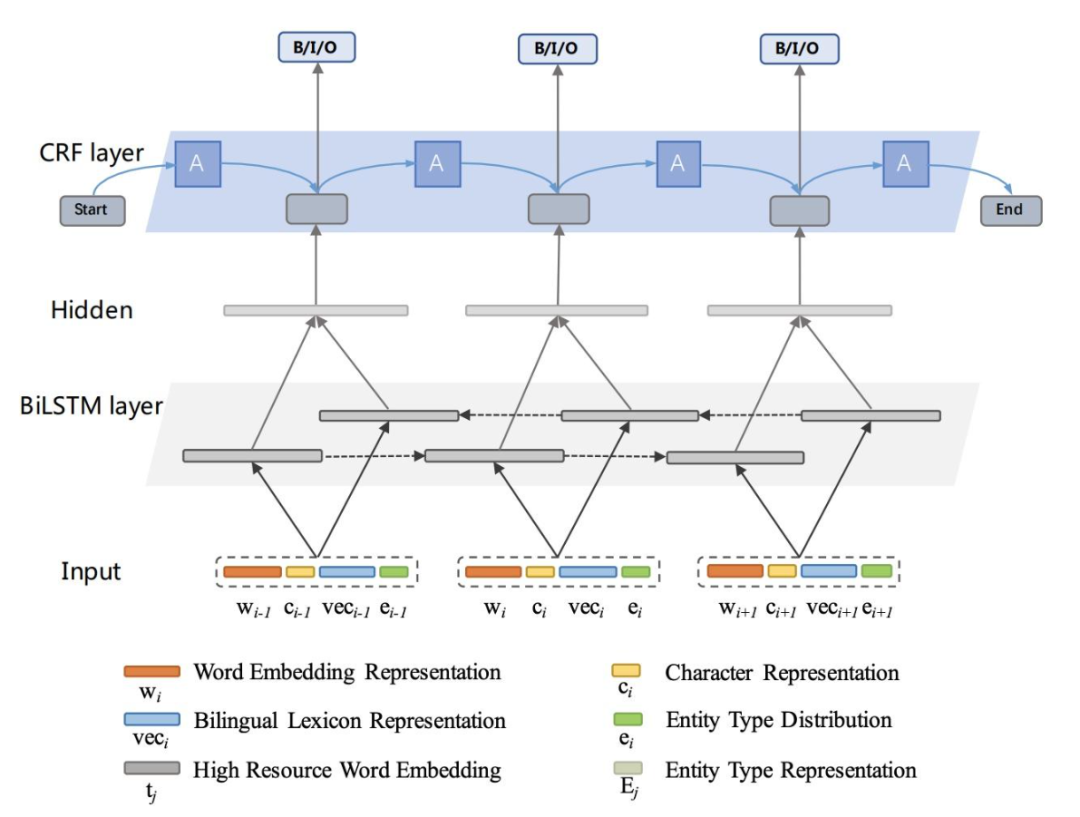
(来源于网络)
表示学习是指将文本、图片等数据转化为数学向量,这些向量能够捕获原始数据背后的语义信息。
检索技术则是利用这些向量化后的数据进行高效查找相似内容的过程。
简单来说,就是我们可以自己“投喂”自己家的知识库进去了,整个运作机制是先检索自己的知识库,通过向量运算来将距离最近的结果返回前给用户。
技术难度:⭐️⭐️⭐️⭐️
适用边界:
主要用于搜索、推荐、问答系统等领域,解决模糊查询、相关性匹配等问题。
(构建表示学习和检索系统需要一定的机器学习基础和专业知识,涉及深度学习模型搭建、向量数据库管理和索引算法等方面。)
实施步骤:
第一步:准备知识库
第二步:运用深度学习模型将文本或其他类型的数据转换为向量;
第三步:将这些向量存储在专属的向量数据库中;
第四步,当用户发起查询时,计算查询向量与数据库内所有向量的距离,找出最相近的结果返回结果。
应用示例:
在新闻推荐系统中,系统可以将用户的历史阅读行为和新闻标题转为向量,然后快速找到与用户兴趣相关的最新文章推荐给用户。
03 Fine-tune(微调)技术
Fine-tune俗称 “微调”,就是“借用”预训练模型的强大基础,通过少量额外训练让它掌握更专业、更精细的技能,从而解决实际问题的一种高效策略。
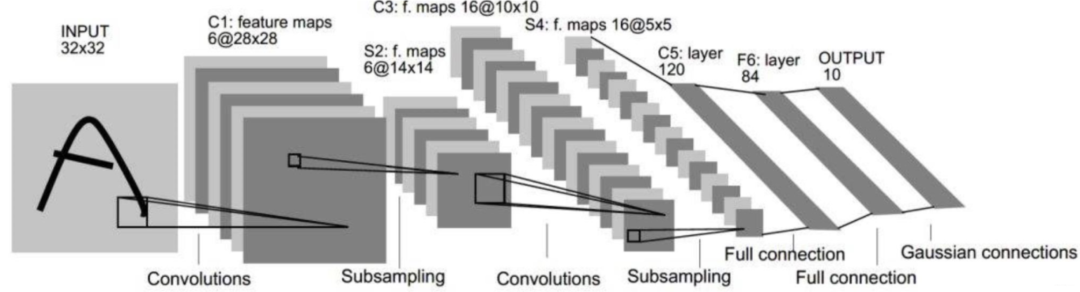
(来源于网络)
打个比方,就像是让你的孩子在已经学会基础数学知识之后,再针对某个专门的数学奥林匹克竞赛进行针对性训练的过程。从而对某一个细分领域有更深的掌握。
技术难度:⭐️⭐️⭐️⭐️
适用边界:
适用于各种定制化的自然语言处理任务,包括但不限于情感分析、文本分类、命名实体识别以及特定领域的问答系统等。
(Fine-tune需要具备一定的机器学习实践经验和数据集准备能力,但许多平台提供了便捷的微调工具和教程,降低了入门门槛。)
实施步骤:
第一步:选用一个适合的预训练大模型作为基础;
第二步:收集并整理用于特定任务的数据集;
第三步:在该数据集上对预训练模型进行额外训练(微调),以使模型更适应特定场景;
第四步:评估微调后的模型在验证集上的表现,并根据需求持续优化。
应用示例:
若要创建一个餐厅评论的情感分析工具,可以采用预训练的语言模型并对其进行fine-tune,使其学会准确地判断评论中的情感极性和倾向性。
最后的话
简单做个总结,指令工程是当下最简应用的一个实施路线,但它用的是基于某个大模型的原生知识,并且会受制于token等类型限制,会导致回复前后不一致的情况,不太适合商用。
表示学习与检索技术专注于从大量文本中提取和利用语义表示以支持高效的检索和相似性比较。
微调技术则是在预训练模型的基础上进一步优化模型能力,使其更精准地完成特定的自然语言处理任务。
对比表示学习和检索技术和Fine-tune技术,这两个技术实现的应用则更加灵活,通过知识库就可以调整输出内容的专业度,达到商用目的。应用这两种技术实施的团队至少得3个人:算法,全栈开发和产品。
人好找,技术路线也好定,此时比拼的就是数据的质量和数量了。
希望带给你一点启发,加油。
作者:柳星聊产品,公众号:柳星聊产品
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
