Transformer神经网络:GPT等AI大模型的基石
上文介绍了生成对抗网络(GAN)的基础概念,今天我们来介绍Transformer神经网络。
Transformer神经网络模型仅基于注意机制(Attention Mechanisms),完全摒弃了循环和卷积的结构,以其独特的自注意力机制和并行计算能力,解决了传统模型在处理长序列时的长距离依赖问题和计算效率问题,从而在各种NLP任务中取得了优异的性能。
本文既是深度学习系列的最后一篇,也可以看做是大语言模型系列的先导篇,起到了承上启下的作用。
一、基本原理
Transformer模型由Vaswani等人在2017年的论文《Attention is All You Need》中提出。该模型完全基于自注意力机制,摒弃了传统的RNN和CNN结构,因此在处理长距离依赖问题上表现出了优越的性能。
下面我将结合《Attention is All You Need》中的这张Transformer结构图,来简单解释其原理。
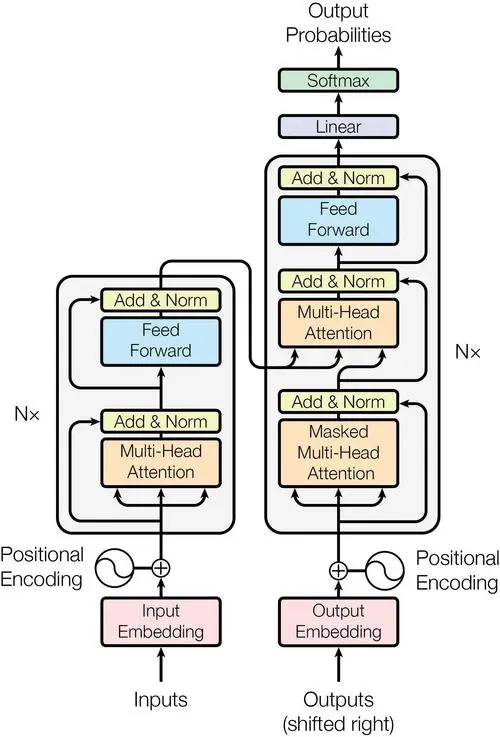
Transformer模型主要由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器用于理解输入数据,解码器用于生成预测。
接下来我们对核心部件和名词做一些解释:
- 编码器(Encoder):编码器的作用是将输入的词序列转化为一系列连续的向量表示,这些向量表示包含了输入序列的语义信息。每个编码器层包含两个子层:自注意力机制和前馈神经网络。每个子层后面都有一个残差连接和层归一化,这有助于模型学习复杂函数并稳定训练。
- 解码器(Decoder):解码器的作用是根据编码器的输出和已经生成的部分目标序列,生成下一个目标词。每个解码器层包含三个子层:自注意力机制、编码器-解码器注意力机制和前馈神经网络。每个子层后面都有一个残差连接和层归一化。
- 自注意力机制(Self-Attention):自注意力机制的作用是计算序列中每个词对其他词的注意力,使得模型在生成每个词时都能考虑到整个序列的信息。例如,在处理句子“The cat is black”中的“black”时,自注意力机制允许模型同时考虑到“cat”,从而更好地理解“black”的含义。这种机制解决了长距离依赖问题。
- 多头注意力机制(Multi-Head Attention):多头注意力机制的作用是让模型能够同时关注序列中的多个位置,从不同的角度学习序列的信息。例如,一个头可能专注于学习语法关系,如“cat”和“is”的主谓关系;另一个头可能专注于学习词义关系,如“cat”和“black”的修饰关系。
- 位置编码(Positional Encoding):位置编码的作用是给模型提供词的位置信息,因为Transformer本身无法处理词的顺序信息。
- 残差连接(Residual Connection):残差连接的作用是帮助模型更好地学习复杂函数。在Transformer中,每个子层的输入不仅被送入子层进行处理,还会与子层的输出相加。这样,模型需要学习的就是输入和输出之间的差异,即残差,而不是直接学习输出。这使得模型能够更容易地学习复杂函数。
- 层归一化(Layer Normalization):层归一化的作用是稳定模型的训练。在Transformer中,每个子层的输出会被规范化,即减去均值并除以标准差。这使得模型的输出在不同的层和位置都有相似的规模,从而稳定了模型的训练。
- 线性层:线性层的作用是将解码器的输出转化为预测每个可能的目标词的分数。
- softmax层:softmax层的作用是将线性层的输出转化为概率,使得分数最高的词被选为下一个目标词。
接下来,我们举个栗子,来说明Transformer的处理流程:
假设我们要翻译句子“The cat is black”到汉语。
- 首先,我们需要将输入句子转化为词向量,这是通过词嵌入(Word Embedding)实现的。然后,我们将位置编码添加到词向量中,得到了包含位置信息的词向量。
- 接下来,这些词向量被送入编码器。在编码器的每一层,每个词向量都会通过自注意力机制,计算与其他词的关系,并生成一个新的向量。然后,这个新的向量会通过前馈神经网络,得到最终的编码器输出。
- 编码器的输出被送入解码器。在解码器的每一层,除了有一个自注意力机制和一个前馈神经网络外,还有一个编码器-解码器注意力机制。这个注意力机制会计算目标序列中每个词与输入序列中每个词的关系,帮助模型更好地生成下一个词。
- 最后,解码器的输出被送入一个线性层和一个softmax层,生成最终的预测。在我们的例子中,模型可能首先生成“这只”,然后生成“猫”,接着生成“是”,最后生成“黑色的”,完成了翻译。
整体来看,Transformer模型解决了RNN等模型在处理序列数据时的几个核心问题:
- 长距离依赖问题:在处理序列数据时,经常会遇到长距离依赖问题,即序列中相隔较远的元素之间可能存在关联。RNN由于其递归的特性,处理长距离依赖关系的能力有限,尤其是在序列较长时,可能会出现梯度消失或梯度爆炸的问题。而Transformer通过自注意力机制,可以直接计算序列中任意两个位置之间的依赖关系,从而有效地解决了长距离依赖问题。
- 并行计算问题:在处理序列数据时,RNN需要按照序列的顺序逐个处理元素,无法进行并行计算。这在处理长序列时,会导致计算效率低下。而Transformer模型由于没有使用RNN,可以在处理序列数据时进行并行计算,大大提高了计算效率。
- 可解释性问题:RNN模型的中间层通常难以解释。而Transformer模型通过注意力权重,可以直观地理解模型在做决策时关注的区域,提高了模型的可解释性。
二、Transformer的优缺点
Transformer模型在自然语言处理任务中取得了显著的成果,我们来总结下它的优缺点。
优点:
- 并行计算:由于没有使用RNN(循环神经网络),可以并行处理序列数据,提高计算效率。
- 长距离依赖:通过自注意力机制,能够捕捉到序列中的长距离依赖关系。
- 可解释性:通过注意力权重,可以直观地理解模型在做决策时关注的区域。
- 模型性能:在许多NLP任务中都取得了最先进的结果,如机器翻译、文本摘要等。
- 模型结构灵活:编码器和解码器结构可以根据具体任务进行调整。
- 可扩展性:可以通过堆叠更多的层或者增加更多的注意力头来增加模型的容量。
缺点:
- 计算资源:需要大量的计算资源。尤其是在处理长序列时,由于自注意力机制的复杂度是序列长度的平方,需要大量的内存和计算能力。
- 训练时间:尽管可以并行计算,但由于模型的复杂性,训练时间仍然很长。
- 对位置编码的依赖:需要依赖位置编码来获取序列信息,可能会限制模型处理超出训练时序列长度的能力。
- 需要大量数据:通常需要大量的标注数据进行训练,对于数据量较小的任务或者领域,可能无法充分发挥其性能。
- 缺乏对序列长度的适应性:对于不同长度的序列,模型可能需要重新调整和训练。
三、Transformer的重要应用:GPT
最近爆火的GPT(Generative Pretrained Transformer)是OpenAI提出的一种预训练语言模型,全名叫生成式-预训练-Transformer模型,说明Transformer是GPT的重要基石。
GPT采用了Transformer的解码器(Decoder)结构,但是去掉了编码器-解码器的注意力(Encoder-Decoder Attention)部分,使其成为一个纯自回归模型。
GPT之所以在生成自然语言文本方面表现如此出色,除了以Transformer模型为底座,优秀的预训练技术同样功不可没。以下是GPT预训练过程的一些主要亮点:
- 自监督学习:GPT利用自监督学习的方式,通过预测下一个词的任务来进行训练。这种方式不需要额外的标注数据,而是利用文本自身的信息来训练模型,从而降低了对数据的需求。
- 掩码技术:GPT在训练过程中采用了掩码技术,随机选择文本中的一些词进行掩码,然后让模型根据上下文来预测这些被掩词的原始词。这种技术有助于提高模型的泛化能力,使其能够更好地处理未见过的词汇和句子结构。
- 高效处理长序列:GPT模型采用了预测掩码技术和动态掩码技术,使得模型在训练和推理时能够高效地处理长序列。这在对长文本进行生成时尤为重要,使得GPT模型比其他模型更加高效。
四、总结
本文介绍了Transformer模型的基本原理、优缺点,并简单提到了其爆款应用GPT,希望对大家有所帮助。
这样,我们的深度学习系列也就宣告完结,我们陆续介绍了人工神经网络ANN、卷积神经网络CNN、循环神经网络RNN(LSTM、GRU)、生成对抗网络GAN和Transformer模型,当然这些只是深度学习的冰山一角,感兴趣的朋友可以自行扩展。
接下来我们将正式进入大模型的学习,下篇文章,我会介绍在大模型中非常重要的提示词工程,敬请期待。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
