GPT-4o和Gemini Live,OpenAI和谷歌都在重新定义大模型产品的人机交互标准
这是我们首次在易用性方面取得重大突破,意义非凡!因为这揭示了我们与机器之间未来的互动方式。
——Mira Murati OpenAI首席技术官
GPT-4o的发布,无疑是昨日AI圈一大焦点。很多文章都做了详细介绍和功能解析,总结下来有3个核心优势:
- 使用门槛更低:免费开放、API价格减半、Mac版工具
- 使用体验更好:速度翻倍、跨模态推理、自然对话
- 使用场景更丰富:情绪感知、实时语音、视觉增强
其中最能引发遐想的,我觉得是“实时理解世界”的能力,包括对物理现实的理解,和人类情绪的理解。

无独有偶,就在5月15日凌晨,谷歌在Google I/O开发者大会展示了名为“Gemini Live”的新体验:
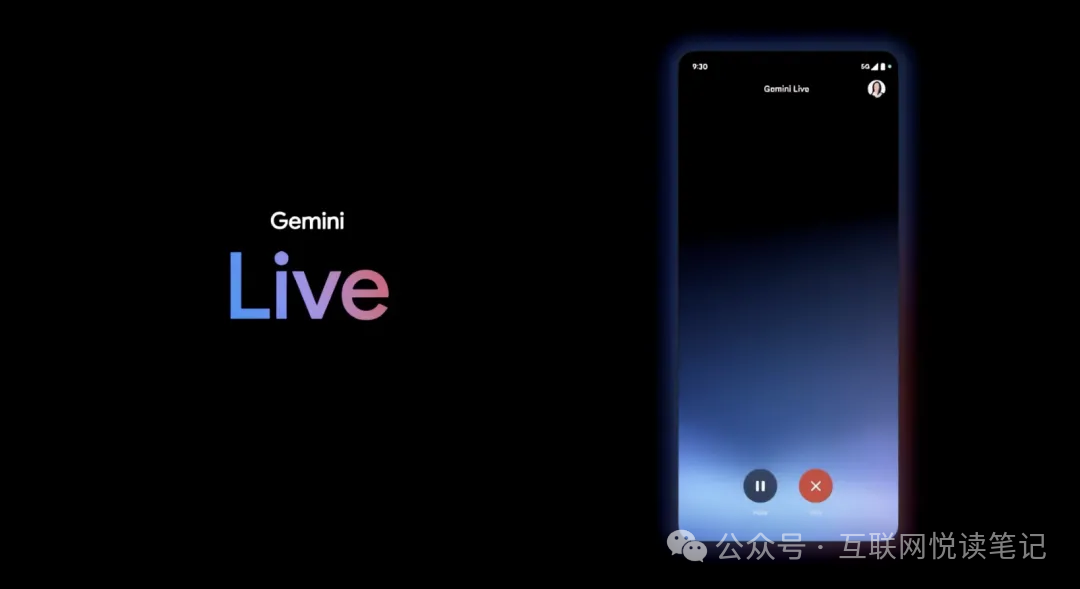
和GPT-4o一样,Gemini Live可以通过手机摄像头拍摄的照片或视频,查看用户的周围环境,并对其做出反应。作为人类的代理,它可以看到和听到我们所做的事,更好地了解我们所处的环境,并在对话中快速做出反应,从而让交互更自然。
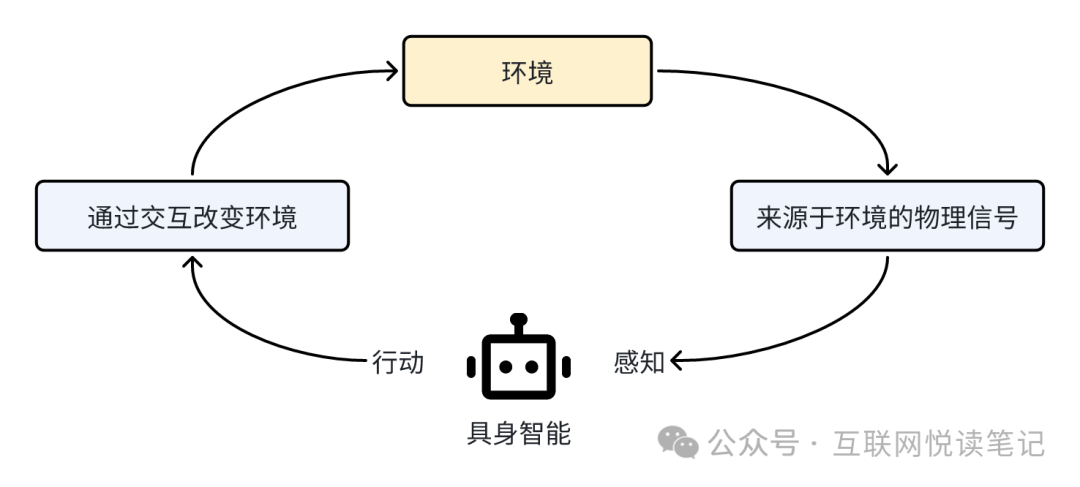
这项能力的发布,很明显都在指向一个关键词:具身智能。
具身智能强调“感知—行动回路”,并呈现出三个特点:
- 一定是多模态的,能像人一样通过视觉、听觉、触觉等感官,以及语言、运动、交互等行为,完成一系列智能任务。
- 能根据环境的交互积累经验,基于不同数据构建不同模型,产生不同的智能,在完成任务上更智能;
- 机器人或智能体有自主性,和人类的学习和认知过程一致。
尽管距离真正的具身智能还有很长的路要走,但我看到了在多模态交互上,人类迈出了关键一步。
我觉得无论是OpenAI还是谷歌,都在借助新的AI技术,为我们制定了新的大模型产品的人机交互标准。
一、大模型产品的人机交互标准是什么?
说起大模型产品的交互方式,通常第一反应都是CUI(Conversational User Interface 对话式用户交互界面),或者叫LUI(Language User Interface,语言交互界面)。甚至很多人一度认为,这就是AI产品最终的交互方式了。

然而真是这样么?回归到交互的本质,无论是图形界面,还是对话界面,目的都是要更精准地解读用户的输入意图,达成更匹配的输出。
表面上看,似乎用对话方式,用户可以更自由、灵活地表达需求,而不用局限在产品经理预设的界面上去完成任务。然而,回归到交互设计原则上看,到底什么样的交互,是真正对用户友好的?
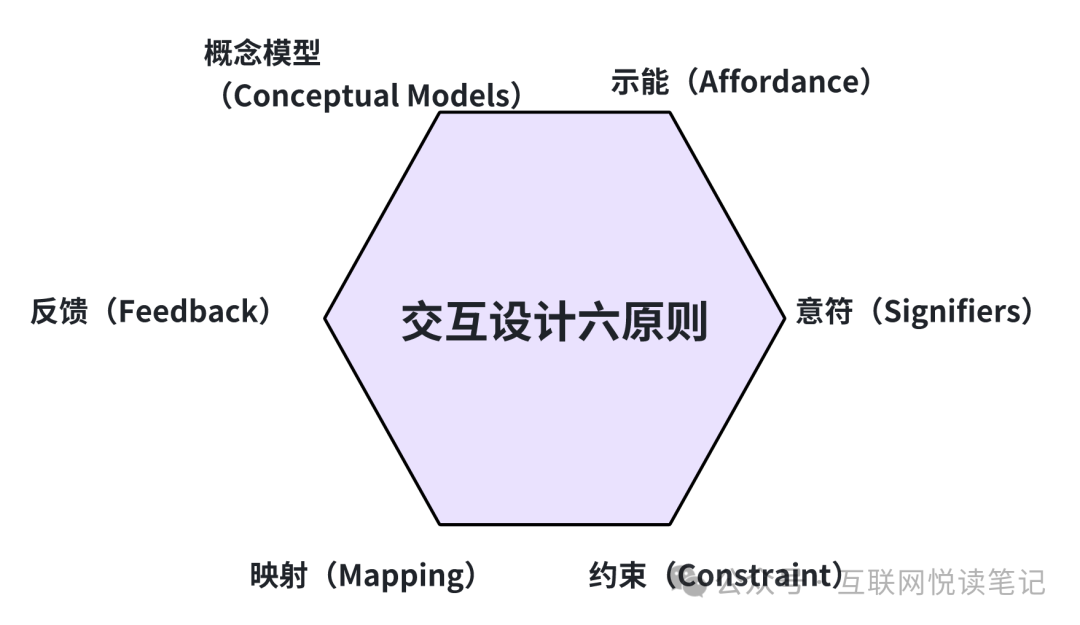
著名的美国认知心理学家、用户体验设计大师唐·诺曼(Don Norman),曾提过一个好产品的交互设计六项基本原则,分别是:
示能(Affordance)
指一个物理对象本身就有的、特定的交互方式,不需要解释,它直接就可以被感知到。比如一把椅子,不管它怎么设计,一定会有一个平面可以坐人。这里面的“平面”,就是一种示能。一出现平面,人们就会天然地认为,这个地方是可以坐的。
意符(Signifiers)
意符是一种提示,告诉用户可以采取什么行为。比如我们经常看到,有些商场的大门上,会写上“推”或者“拉”的提示,这个推和拉就是一种意符。
约束(Constraint)
约束限定了一系列可能的操作。在设计中有效使用约束因素,就可以让用户在任何未知环境下都能找到合适的操作方法。比如拼乐高积木、使用电源插座。
映射(Mapping)
映射表示两组事物要素之间的关系,是可以直观反映在物理位置上的。比如办公室的顶灯和对应的开关,它们之间的排布是一一对应的,你就可以知道按哪个按钮开关哪排灯。
反馈(Feedback)
好设计一定要有即时反馈,稍有延迟便会令人不安。生活中我们经常会碰到有人在电梯前反复按楼层键,就是因为缺少及时反馈。反馈需要精心策划,以一种不显著的方式确认所有操作。
概念模型(Conceptual Models)
指高度简化的说明,告诉用户产品是如何工作的。比如电脑中的文件和文件夹就是一套概念模型,实际上硬盘上并不存在文件夹,但这比复杂的计算机指令更能让用户理解计算机的操作。
我们把传统对话式交互,分别带入这6个原则:
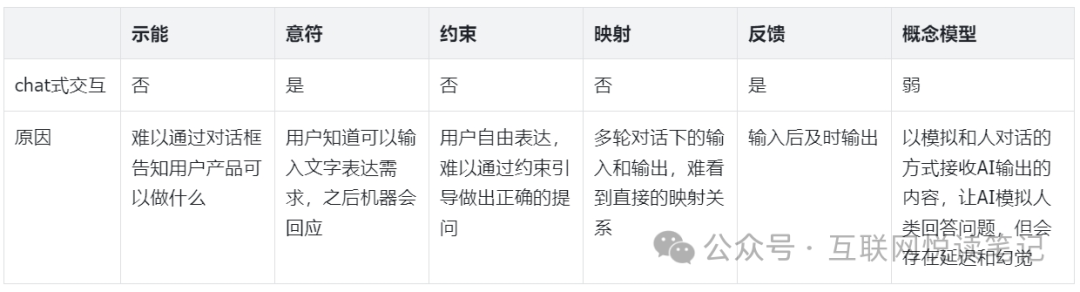
你会发现,似乎文字对话框式的使用方式,并不符合一个好产品的交互原则。
而GPT-4o和Gemini Live的出现,我认为是重新定义了大语言模型产品的交互设计标准。因为它为我们带来了:
- 更即时的交互反馈
- 更立体的交互方式
- 更情绪化的交互过程
二、更即时的交互反馈
Murati在发布会上提到,与GPT-4-Turbo相比,GPT-4o的速度快2倍。尤其在语音对话场景,GPT-3.5的平均延迟为2.8秒,GPT-4为5.4秒,而GPT-4o对音频输入的平均响应时间为320毫秒,最短的响应时间为232毫秒,与人类的响应时间相似。Gemini Live也支持在聊天时打断,让AI实时适应人类语言表达的模式。
这样的高效,带来了更自然的使用体验,让人类和大模型的交流,更符合人与人之间面对面沟通的概念模型。也创造了更即时的反馈。将这些技术和增强的语音引擎相结合,就可以实现更一致的情感表达和现实的多轮对话。
三、更立体的交互方式
人机交互的底层原理,可以概括为:事件有反馈,操作有结果。
输入的对象是机器,输入给机器的内容,是固定化的指令和多样化的信息。而输出的对象是人,输出的内容是给到人的感官反馈。优秀的交互设计,就是用更多元的输入,带给用户更丰富的输出。
乔布斯说过:
苹果电脑就是21世纪人类的自行车,只要愿意,谁都可以拥有它。它是工具,是人类大脑的延伸。
在人与电脑之间,可以发展出特殊的关系,它可以改善个人的生产力。
GPT-4o交付给我们的,不光是人类的第二大脑,更是第二双眼睛、耳朵和嘴。
通过GPT-4o,大模型的示能方式可以延展为“能说话的摄像头”,扮演教你做题的数学老师、为你同声传译的翻译官、理解你情绪的咨询师。
而文字表达带来的低约束性问题,也可以借助对视觉、声音、语调的理解,让大模型围绕特定环境给出更精准的对话引导。想象下,当打开AI后,它会先环顾四周,知道你在哪儿,身边都有谁,大家在说什么,再开启一场更符合场景的对话,这样的交互简直不能再自然了。
四、更情绪化的交互过程
“人类的生命,不能以时间长短来衡量,心中充满爱时,刹那即为永恒”
人与机器的区别之一,就在于能否理解情绪,甚至表达情绪。
AI 情绪,也一直是创业者热衷投入的赛道。无论是微软小冰、Glow、Character.AI、Replika等聊天陪伴型机器人,还是Pi、Hume.AI这种对情绪理解更深入的技术解决方案。都希望借助情感化设计,提供更贴心和人性化的服务。
唐·诺曼(Don Norman)在《设计心理学3-情感设计》中写到,情感化设计,自底向上分为:本能层、行为层、反思层三层结构。
- 本能层表现为感性认知,凭借第一印象吸引用户。
- 行为层体现在操作产品时,是否有清晰流畅的步骤,明确的使用动线,靠体验留住用户。
- 反思层则代表产品融入了独特的文化内涵和差异化的亮点设计,能打动人心,扎根在记忆中。
想象下,具备情绪感知和视觉理解的AI,可以在本能层表现的更加自然生动,在行为层给出更连贯、可打断、有记忆的个性化输出,在反思层深深植入每个人独有的陪伴角色。
当然,也许你会觉得我想多了,这些新技术没那么厉害。不就是在文字聊天的基础上,增加了语音和视频通话的功能么?说它是重新定义了AI交互,太夸张了。
说的没毛病。不过我更关心的,不在定义本身,而是想为你提供一种设计AI产品交互界面的新思路。
我的观点是:
作为生产力工具的大模型产品,在产品设计之初,就应该考虑多模态的交互方式。
- 大模型产品,应该是可以“看”的——通过视觉或其他感官,感知环境。
- 大模型产品,应该是可以“说”的——根据环境的不同,进行自然语言对话。
- 大模型产品,应该是可以“听”的——在对话和观察中感知情绪,认真聆听,做出反应。
- 大模型产品,应该是可以“记”的——在长期交互中形成记忆,动态调整和你的互动方式和输出的内容。
回看当初OpenAI发布Sora时,曾提出“视频生成模型是世界模拟器”的观点(Video generation models as world simulators)。构建世界模拟器的前提,就是要增强对世界的理解,补充更多物理规律和世界常识。多模态交互的设计,正是达成这一目标的最优解。
五、结语
最后,我们再来看看本文开头提到的交互设计六原则,我想试着把多模态交互也填进去,看看和传统chat式交互的对比差异。

客观看,就算增加了多模态,当前的大模型和人类的交互方式,仍不是最优的,那还有没有其他解法呢?
肯定是有的,好的交互,永远不是单一设计。
我们完全可以融合GUI CUI/LUI 多模态几种形式到一起,在指定场景下,为特定角色设计交互方式。比如老师机器人、医生机器人、教练机器人。人类都可以分角色,为什么AI不行呢?
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
