图灵测试2.0:怎么判断AI到底能干什么不能干什么
图灵测试本身是一个定性的、概念性的测试,理论上随便哪个程序都可以通过缩窄测试范围、限定测试集然后通过所谓的图灵测试。
换成产品视角,情况则有所不同,这时候能否通过图灵测试就会限定在产品的边界以内,并且拳拳到肉,一旦不灵,AI驱动的产品就不成立了。本次测试就是抽取了真实产品的部分场景进行方便理解的再包装,目的主要用于说明图灵测试2.0这概念。
考虑潜在的误读,预先做如下声明:
1. 本测试不权威也不全面,但可复现,过程数据有留存。可复现是指按照步骤每个人都可以测试。
2. 本测试不代表各个模型优劣,只代表和设定场景的匹配度。
3. 本测试选择模型有主观性,在用的起和好用上做了权衡。
一、角色中心式计算与图灵测试2.0
角色中心式计算是相对功能中心式计算说的。
到现在为止差不多所有我们用的APP是以功能来划分的,职能相对单一,比如IM、搜索、外卖、打车等等。
一个角色职责的完成往往需要组合很多的功能,比如那怕一个招聘的角色它背后都必须组合十几个工具(从IM到招聘APP等)才能完成招聘某个人的工作。
现在AI可以承担这个居中调度的角色,所以应用的下一步必然是角色中心式计算。
而角色中心式计算是否成立,核心则在于AI的智商程度是否能够处理角色边界内的一切事情,比如招聘的时候要能判断当前的JD的描述是否匹配需求方的需求也要判断一个候选人是否初步匹配对应的招聘需求等。
如果角色的每一个这种关键步骤的都可以用AI来完成,那对这个角色而言就不单通过对话无法区分出这是真人还是AI,从现实的反馈也无法区分。
这就算通过了图灵测试2.0。
这点之前展开比较多,这里不过多重复了。
在过去的文章里一直缺一个往下一步,怎么设计和实现图灵测试2.0的例子,这篇文章重点在这里。
我们抽取一个真实场景的核心步骤,从易懂的角度包装成一个极简的例子,来说明图灵测试2.0的概念怎么分解,和一个具体的角色怎么融合。
二、图灵测试2.0的示例
假如我们打造这么一个简单角色。
它是你的代理,可以帮助你按照你的设定在特定UGC平台上发布你生成的内容。(OpenAI发布会上Greg Brockman演示过类似的例子)
我们略去大量细节来描述这个角色。
这样一来这个角色就有4个关键内涵:
1. 完成你对自己做的人设。
2. 针对特定话题或者问题生成内容。
3. 确保内容的质量。
4. 发布等执行步骤。
第四步的发布等是传统的RPA等技术,其实并不关键,后面就都略过了。
在这三个关键步骤里面,除了内容生成,还需要AI做的判断是:
1. 生成的内容是不是真的匹配对应的话题或者问题?(内容生成是一次性的,在多个平台发布是多次性的,所以要经常做匹配的判断)
2. 内容的基础质量到底怎么样?
这两项工作别看简单,但在没有AI大模型前还真的很难做好。在过去你就没办法针对特定问题、话题实时生成内容,也很难实时大批量的判断匹配度。
有点像无机物到单细胞生物。
为了缩减文章篇幅,我们进一步降低目标。
完成第一项工作就变成生成一个内容的概要,然后大模型判断内容概要和问题的匹配度。这里其实可以直接用模型,也可以用Embedding算法。
两者各有利弊,但这里只关注用模型的判断结果。
这步骤做完之后,比如你生成的内容是:青玉案元夕相关,那就可以匹配到古诗词的标签或者特定问题下面。
都测试完了之后,还需要用人来标注下最终测试结果,这样就提供个绝对的尺度,知道AI大模型算法能进行到什么程度了。
第二项的评测简化成使用BLEU算法来评测生成内容的相似度。
这是避免内容生成的重复。
为什么做这个呢?因为最终不希望反复发表一样的内容。即使输入相对一致,比如人设、话题等有相似性,也不希望内容一致。
至于是不是内容生成的足够优美,就先不管了,那十分麻烦。
为了完成这个测试,需要一些真实数据,这可以手动编辑或者抓取。这部分和具体你辐射的领域有关系,文艺青年、斜杠青年等需要的数据不怎么一样。但这和RPA一样是个传统的活,大部分程序员都会做。这里为了避免不必要的麻烦,数据先不公开了。
完成了上面的工作,其实就完成了从一个角色到图灵2.0测试集的基础映射:关键是要分解角色内涵,为关键判断建立测试集。
三、测试结果
在准备的1000条测试数据上,第一项测试最终结果是下面这样:
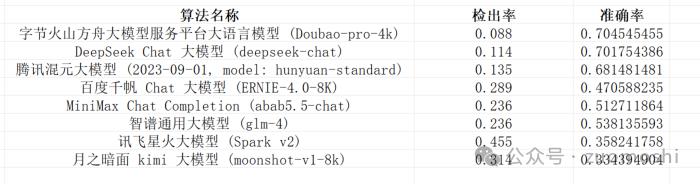
这里面检出率是指在1000条测试项目里,有多少模型判断为匹配的,准确率是指在认为匹配的项目里面和人的标注比,准确率什么样。
这个测试结果最终怎么用会和你的倾向性相关,显然的数量优先和质量优先结果是不一样的。
结果里面最有意思的点是:至少在这一个判断项上,AI还不如人。所以如果判断项比较多,整体精度的控制会是很有挑战的问题。
然后我们测试的是内容生成部分的质量,这部分我们不测文辞是否优美这些,就测生成内容的最简单的BLEU值,其中参数都用缺省参数,temperature这些就不改了。如果做的很细,这部分可以反复试多组值。但我们是为了说明图灵测试2.0概念,就不做这部分了。
最终测试结果中得分前三的是:

全部模型的测试结果是:
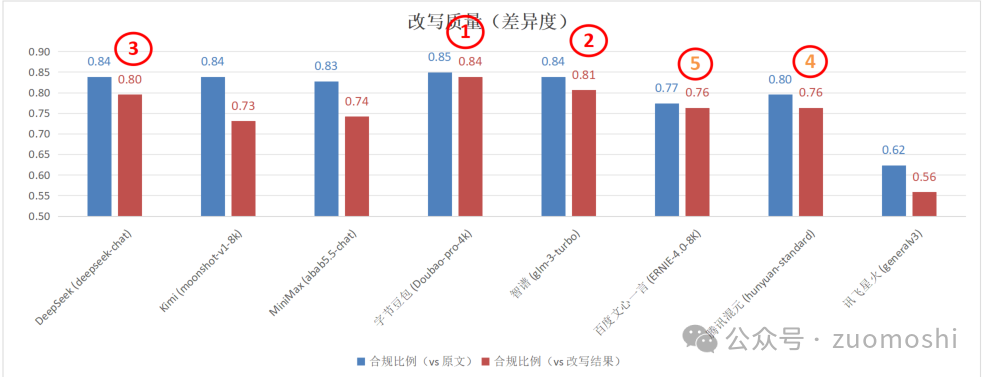
这里面和原文对比是指创作内容和原始种子做比较,然后统计BLEU值小于0.75的比例,0.85就意味着85%的内容差异度大于0.75。(原文可以看成是内容的种子,基于原文和提示词生成对应内容。)
和改写结果比是指,同样的方法会生成3次内容,然后看BLEU值,把小于0.75的除以3就是上面的结果。当然提示词中会包含加大差异度的部分。
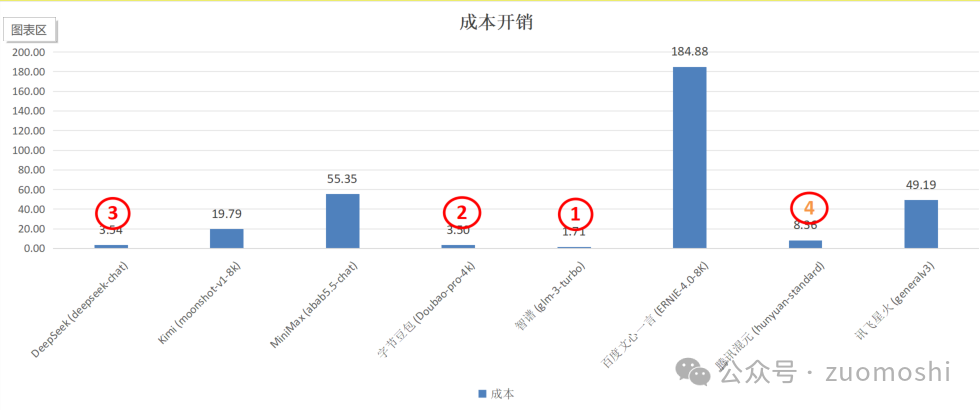
内容生成会比较耗费token,所以同步要记录下token数目和费用。最终出了个价格离谱的,说明模型初选的时候选错了。
四、例子的意义
当这种测试可以通过,那就意味着最终从技术视角看,对应的角色可以通过图灵测试2.0。如果精度达不到一定程度,那你设定的角色在当前AI的智商下就不成立。不管多酷炫、别人多么吹捧但对解决你设想的问题都没意义。
其次是要理解,任何一个角色的成立要涵盖对应角色的N多方面。
用AI来做亮眼的Demo,和用AI做真正能用的产品,两者的难度不在一个数量级,虽然看着都是差不多的东西。这就是一般镜头和哈勃望远镜的镜头的区别。
这种测试结果也可以标识从产品角度看到的AI的真实进展。往往和某些媒体上来的认知有很大偏差。
落地时里面的项目和复杂度当然需要进一步增加。
但如果真想用AI,那现在开始就需要建立你自己的测试集,并且在模型还不稳定的时候定期测试。
假设这个测试集里面的数据采样足够丰富,再加上一个对接到各个大模型的测试框架,那在你的领域你会比任何人都权威,不用听任何人的。
这就是之前说的一手体验。
这里面对一般人有点挑战的倒不是提示词怎么写,这部分资料比较多,反复测试可以找到解决方案,最不济还可以问AI。
麻烦一点的是怎么组合各种算法。
不是所有的时候都只用大模型一种算法就行的。
这部分只能陆续探讨,没有唯一解决方法。
限制
上述方法现在可以用于支持一些比较简单的角色。
但因为角色自身的行为模式还是基于规则,只能在限定的流程框架里面完成任务。
如果角色过于复杂,可能还需要进一步的AI进步,暂时可以先别整。
但这已经能够打造一些和过去不一样的应用了。
五、小结
最终再总结下图灵测试2.0的全过程:先定义你认为有商业价值的角色,然后依据角色挖掘它的内涵,具体成相应的图灵测试2.0的测试集,然后就反复测试各种模型。如果能通过,那从技术角度角色也成立,产品可以启动。否则就得等等。回到现场的一手体验,是AI产品的最最关键的起点。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
