AI大模型实战篇:AI Agent设计模式 – REWOO
在上篇文章《AI大模型实战篇:AI Agent设计模式 – ReAct》中,风叔结合原理和具体源代码,详细介绍了ReAct这种非常有效的AI Agent设计模式。但是ReAct模式有一个非常突出的问题,就是冗余计算,冗余会导致过多的计算开销和过长的Token使用。
在本篇文章中,风叔介绍一种优化ReAct冗余问题的方法,REWOO。
一、REWOO的概念
REWOO的全称是Reason without Observation,是相对ReAct中的Observation 来说的。它旨在通过以下方式改进 ReACT 风格的Agent架构:
第一,通过生成一次性使用的完整工具链来减少token消耗和执行时间,因为ReACT模式的Agent架构需要多次带有冗余前缀的 LLM 调用;
第二,简化微调过程。由于规划数据不依赖于工具的输出,因此可以在不实际调用工具的情况下对模型进行微调。
ReWOO 架构主要包括三个部分:
- Planner:规划器,负责将任务分解并制定包含多个相互关联计划的蓝图,每个计划都分配给Worker执行。
- Worker:执行器,根据规划器提供的蓝图,使用外部工具获取更多证据或者其他具体动作。
- Solver:合并器,将所有计划和证据结合起来,形成对原始目标任务的最终解决方案。
下图是REWOO的原理:
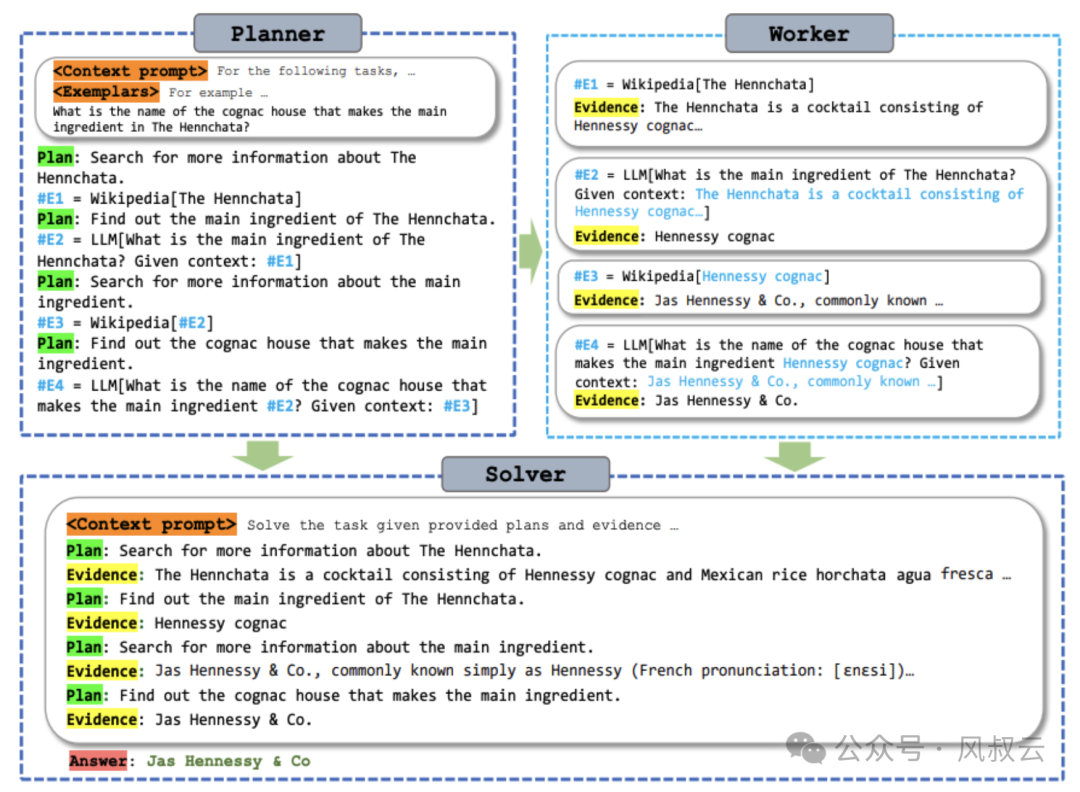
- Planner接收来自用户的输入,输出详细的计划Task List,Task List由多个Plan(Reason)和 Execution(Tool[arguments for tool])组成;
- Worker接收Task List,循环执行完成task;
- Woker将所有任务的执行结果同步给Solver,Solver将所有的计划和执行结果整合起来,形成最终的答案输出给用户。

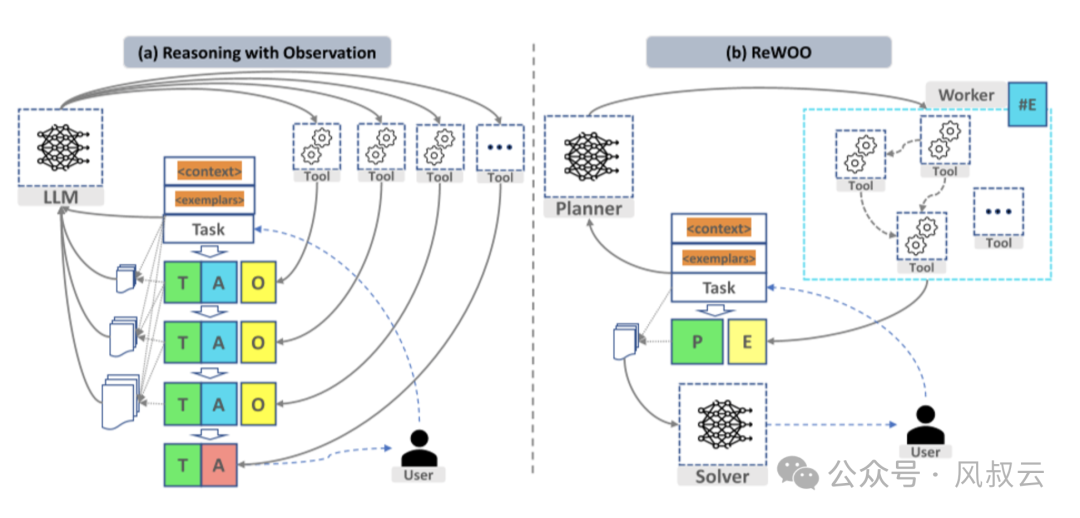
详细对比一下ReAct和REWOO,如下图所示。
左侧是ReAct方法,当User输入Task后,把上下文Context和可能的样本Example输入到LLM中,LLM会调用一个目标工具Tool,从而产生想法Thought,行动Action,观察Observation。由于拆解后的下一次循环也需要调用LLM,又会调用新的工具Tool,产生新的Thought,Action,Observation。如果这个步骤变得很长,就会导致巨大的重复计算和开销。
右侧ReWOO的方法,计划器Planner把任务进行分解,分解的依据是它们内部哪些用同类Tool,就把它分成同一类。在最开始,依旧是User输入Task,模型把上下文Context和Examplar进行输入。这里与先前有所不同的是,输入到Planner中,进行分解,然后调用各自的工具Tool。在得到了所有的Tool的输出后,生成计划结果Plan和线索,放到Solver进行总结,然后生成回答。这个过程只调用了两次LLM。
二、REWOO的实现过程
下面,风叔通过实际的源码,详细介绍REWOO模式的实现方法。在手机端阅读源代码的体验不太好,建议大家在PC端打开。
第一步 构建Planner
Planner的作用是根据用户输入,输出详细的Task List。
首先需要给Planner规定Prompt模板,包括可以使用的Tools,以及Task List的规范。在下面的例子中,我们告诉Planner,“对于目标任务,要制定可以逐步解决问题的计划。对于每个计划,要指出哪个外部工具以及工具输入来检索证据,并将证据存储到变量 #E 中,以供后续工具调用”。在工具层面,我们定义了两个工具,google search和LLM。
from langchain_openai import ChatOpenAI
model=ChatOpenAI(temperature=0)
prompt = “””For the following task, make plans that can solve the problem step by step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, …)
Tools can be one of the following:
(1) Google[input]: Worker that searches results from Google. Useful when you need to find shortand succinct answers about a specific topic. The input should be a search query.
(2) LLM[input]: A pretrained LLM like yourself. Useful when you need to act with generalworld knowledge and common sense. Prioritize it when you are confident in solving the problemyourself. Input can be any instruction.
For example,Task: Thomas, Toby, and Rebecca worked a total of 157 hours in one week. Thomas worked xhours. Toby worked 10 hours less than twice what Thomas worked, and Rebecca worked 8 hoursless than Toby. How many hours did Rebecca work?
Plan: Given Thomas worked x hours, translate the problem into algebraic expressions and solvewith Wolfram Alpha.
#E1 = WolframAlpha[Solve x + (2x − 10) + ((2x − 10) − 8) = 157]
Plan: Find out the number of hours Thomas worked.
#E2 = LLM[What is x, given #E1]
Plan: Calculate the number of hours Rebecca worked.
#E3 = Calculator[(2 ∗ #E2 − 10) − 8]
Begin!
Describe your plans with rich details. Each Plan should be followed by only one #E.Task: {task}”””
task = “what is the hometown of the 2024 australian open winner”
result = model.invoke(prompt.format(task=task))
print(result.content)
下面是根据给定的问题,Planner输出的Task List。可以看到,Planner按照Prompt的要求给出了计划的每个步骤,以及需要调用的工具。
Plan: Use Google to search for the 2024 Australian Open winner.
#E1 = Google[2024 Australian Open winner]
Plan: Retrieve the name of the 2024 Australian Open winner from the search results.
#E2 = LLM[What is the name of the 2024 Australian Open winner, given #E1]
Plan: Use Google to search for the hometown of the 2024 Australian Open winner.
#E3 = Google[hometown of 2024 Australian Open winner, given #E2]
Plan: Retrieve the hometown of the 2024 Australian Open winner from the search results.
#E4 = LLM[What is the hometown of the 2024 Australian Open winner, given #E3]
因为使用了LangGraph,为了将Planner连接到图表,我们将创建一个 get_plan 节点,该节点接受 ReWOO 状态并返回steps和 plan_string 字段。
import refrom langchain_core.prompts
import ChatPromptTemplate
# Regex to match expressions of the form E#… = …[…]
regex_pattern = r”Plan:s*(.+)s*(#Ed+)s*=s*(w+)s*[([^]]+)]”
prompt_template = ChatPromptTemplate.from_messages([(“user”, prompt)])
planner = prompt_template | model
def get_plan(state: ReWOO):
task = state[“task”]
result = planner.invoke({“task”: task})
# Find all matches in the sample text
matches = re.findall(regex_pattern, result.content)
return {“steps”: matches, “plan_string”: result.content}
第二步 构建Worker
Worker负责接收Task List并按顺序使用工具执行任务。下面实例化搜索引擎,并定义工具执行节点。
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults()
def _get_current_task(state: ReWOO):
if state[“results”] is None:
return 1
if len(state[“results”]) == len(state[“steps”]):
return None
else:
return len(state[“results”]) + 1
def tool_execution(state: ReWOO):
“””Worker node that executes the tools of a given plan.”””
_step = _get_current_task(state)
_, step_name, tool, tool_input = state[“steps”][_step – 1]
_results = state[“results”] or {}
for k, v in _results.items():
tool_input = tool_input.replace(k, v)
if tool == “Google”:
result = search.invoke(tool_input)
elif tool == “LLM”:
result = model.invoke(tool_input)
else:
raise ValueError
_results[step_name] = str(result)
return {“results”: _results}
第三步 构建Solver
Solver接收完整的计划,并根据来自Worker的工具调用结果,生成最终响应。
我们给Solver的Prompt很简单,“根据上面提供的证据,解决问题或任务,直接回答问题,不要多说”。
solve_prompt = “””Solve the following task or problem. To solve the problem, we have made step-by-step Plan and retrieved corresponding Evidence to each Plan. Use them with caution since long evidence might contain irrelevant information.{plan}
Now solve the question or task according to provided Evidence above. Respond with the answerdirectly with no extra words.
Task: {task}
Response:”””
def solve(state: ReWOO):
plan = “”
for _plan, step_name, tool, tool_input in state[“steps”]:
_results = state[“results”] or {}
for k, v in _results.items():
tool_input = tool_input.replace(k, v)
step_name = step_name.replace(k, v)
plan += f”Plan: {_plan}n{step_name} = {tool}[{tool_input}]”
prompt = solve_prompt.format(plan=plan, task=state[“task”])
result = model.invoke(prompt)
return {“result”: result.content}
第四步 构建Graph
下面,我们构建流程图,将Planner、Worker、Solver等节点添加进来,执行并输出结果。
def _route(state):
_step = _get_current_task(state)
if _step is None:
# We have executed all tasks
return “solve”
else:
# We are still executing tasks, loop back to the “tool” node
return “tool”
from langgraph.graph import END, StateGraph, START
graph = StateGraph(ReWOO)
graph.add_node(“plan”, get_plan)
graph.add_node(“tool”, tool_execution)
graph.add_node(“solve”, solve)
graph.add_edge(“plan”, “tool”)
graph.add_edge(“solve”, END)
graph.add_conditional_edges(“tool”, _route)
graph.add_edge(START, “plan”)
app = graph.compile()
for s in app.stream({“task”: task}):
print(s)
print(“—“)
下图详细介绍了Planner、Worker和Solver的协作流程。
三、总结
相比ReAct,ReWOO 的创新点主要包括以下几个方面:
- 分离推理与观察:ReWOO 将推理过程与使用外部工具的过程分开,避免了在依赖观察的推理中反复提示的冗余问题,从而大幅减少了 Token 的消耗。
- 模块化设计:ReWOO 使用模块化框架,通过planer、worker和solver的分工合作,提高了系统的扩展性和效率。
- 效率提升:实验结果表明,REWOO不仅提升了准确率,还显著降低token消耗。
- 工具调用的鲁棒性:ReWOO 在工具失效的情况下表现出更高的鲁棒性,这意味着即使某些工具无法返回有效证据,ReWOO 仍能通过合理的计划生成和证据整合,提供有效的解决方案。
但是,REWOO的缺陷在于,非常依赖于Planner的规划能力,如果规划有误,则后续所有的执行都会出现错误。尤其是对于复杂任务,很难在初始阶段就制定合理且完备的计划清单。
因此,如果要提升Agent的准确率,需要有规划调整机制,即在执行的过程中,根据环境反馈,不断调整计划。这就是下一篇将要介绍的AI Agent设计模式,Plan & Execute。
作者:风叔产品总监,公众号:风叔云
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
