互联网数据工作流
节假日最适合做的事,是从日常事务里跳出来,尝试做一些抽象思考,例如说,纷繁复杂的互联网数据工作,大体是怎样一个架构,通俗地说,也就是内部结构和具体工作分布。
作为类比,先看看已经被布道好多年的,相对成熟的互联网产品流程:
需求产生的环节在业务,比如财务、市场,包括内外部;
需求翻译到用例的环节是售前,产品,测试;
用例进入开发流程以后,对产品流程来说进入一个黑盒,围绕实现,辅助职能分布在进度控制,性能优化,基础运维,需大概了解;
需求实现以后,逆向走开发-测试-产品-业务去核验和优化,循环这个过程,形成工作流。
互联网数据工作流也可以这样分,如下图。概括一下职能分布,1是技术,2是业务模式,3是商业智能,4是学术。
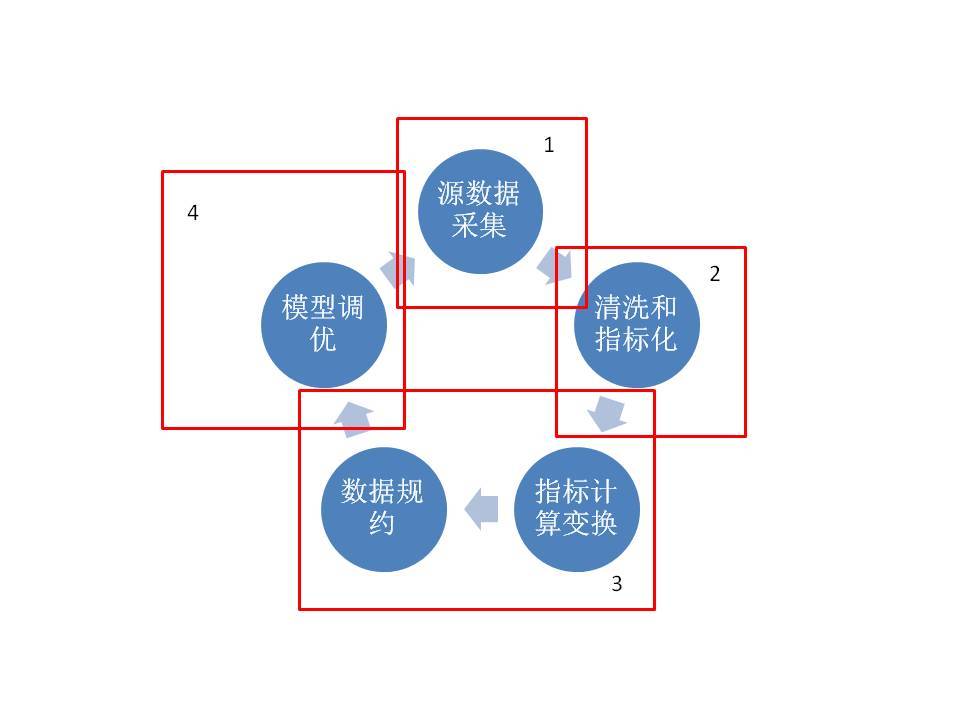
自己画的
1的环节是外部爬虫和内部埋点
表面上看,这是一个”上帝说,要有光,于是就有了光“的业务步骤,实际这是一个纯粹技术的领域,例如爬虫的资源调度,埋点的性能平衡,后台海量存储等等。
(创业公司基本都用第三方,因为自己做太奢侈了,有理想/有机会的大司CTO都会自己搭,很锻炼团队,同时大团队会有人出去创业,形成技术溢出,福泽没有能力的中小网站。)
为了方便表达,插一个例子,假如我们用温度计测水温,温度计本身是凉的,那么测出的水温就可能偏低一丁点(量子力学里更有所谓,看一眼,用来观察的粒子影响被观察粒子,状态就变化的测不准原理。)
与此类似,互联网数据最好玩的地方是,为了通过数据观察一个应用的各方面表现,取数方法本身也是一个应用,因此如上所述的”观察方法对观察结果的干扰“就特别大。
我们经常听到互联网数据讲座里,花n小时说ga的老版本js和新版本ua有什么不同,或者各种tag manage工具的数据对接坑,做互联网数据的人对此是习以为常的,你可以完全不知道如何写代码,但你必须知道一堆的同步异步,cookie、uuid的术语。
具有讽刺意味的是,步骤1里的工程师往往不知道提数据需求的人到底想做什么(有时候是真的没人知道,埋着当买保险),他们接下去会在没有使命感的情况下,烦恼性能和如何在混乱的版本合并里保持一切井井有条,而没有使命感,对于代码质量经常有致命的负面影响。(因为代码质量无法用传统方法qa,纯靠良知操守和使命感)
小结一下,1的环节是纯粹技术的、门槛很高的环节(索性有大量现成第三方,这也是为什么说现在数据的时代来临了,之前很痛苦),所有非技术的、要用到数据的同学都必须有1的基本知识,在下一步的数据清洗,异常识别和指标排障里有很大用处。
2的环节是把源数据洗干净,变成可以看的指标
按道理2是技术环节(比如cookie传值和uv的对应规则),但是因为互联网广告的高度发达(都是烧钱烧太多搞出来的),这方面已经有很成熟的用来解释和优化烧钱的数据指标体系,实际上2已经是纯业务的环节。(例如,由于pv、uv、visit过于有知名度,很多人会忘记这些也只是一些自定义指标而已。)
这个步骤往往由业务部门的分析师进行,主要工作概括起来,是使常人能够理解数据,将原始日志/数据集,翻译成一些比如转化率,比如独立访客带来的收入之类直观的数字,进而形成一些简单报表,基于对这些报表的使用,来支持拍脑袋(也叫决策)。
在水平较成熟的团队里,会看到大量自定义指标,这些指标的建立原则很简单,针对kpi,或者更时髦的okr(模糊版的kpi),比如视频来说,基本的访问量和播放量之外,可以有播放中拉条快进的比例(不要想歪)之类,来细致考察用户感兴趣的程度。
这个”解释和使用数据“的环节,是市面上绝大多数所谓做数据的人的日常工作(比如广告公司,比如传统公司市场部、信息部、电商部,第三方运营等等),虽然门槛很低,但由于大部分企业现在数据意识刚刚觉醒,需求大的惊人,完全供不应求。
3的环节开始小众,是所谓用大数据解决实际问题
还是举例,比如一个OTA经过1和2的步骤,有了客人预订各区域酒店的数据,有了订单量流量转化率,也有自己的成本,有该区域的资源分布情况,以及爬虫获取的对手的大致资源情况-无非是价格啊库存啊覆盖啊,或许还有点评之类。
那我们要解决问题,比如我希望将市场区域分成咨询公司常说的各种动物的分类,不同分类对应不同竞争阶段(或动物),不同阶段有不同增长预期,同时可以辅助各渠道预算分配,和2不同的是,2只要有个报表参考,3可以给出基于一定概率的结果。
3的环节是商业智能BI出场的时候(遗憾的是大部分BI还在2的世界里,甚至1的世界里)。
这里主要的任务和1很像,克服性能瓶颈。只不过不是爬虫和埋点的性能,我们这次并不会爬的竞争对手网站瘫痪,或者搞得用户在app点击下一步的时候为了传输他选的增值产品而卡死在中间,这次可能卡死的是后续的分析模型,为了能反复迭代,必须在进入挖掘之前,找出少数主要特征。
传统经验模式,讲究靠老师傅从几千个可能出问题的地方指出最可能的几个,数据规约就是通过对几千个指标的相似度/信息量/不确定性的计算,来将这类老师傅经验变成一个可复用的函数。
举例子来说,如果研究肥胖,有四个数据,一是每天吃几顿饭,二是每顿吃几碗,三是每天摄入的卡路里量,四是每天运动消耗卡路里量。老师傅会说,你傻啊,前三个可以合并一个,而数据规约是通过指标选择算法(比如lasso)给重复指标打很大的惩罚分,也可以得到前三个指标只需留一个的结论。
3的世界是反反复复和业务方(2的人们)聊需求到底是什么,目标是翻译成数学语言;同时反反复复和数据来源方(1的人们)聊异常值,目标是理性对待奇怪的看似是误差的数据,不要为了预测而预测(过度拟合和拟合不足)。
在充分了解的基础上,下面就可以把数据往聚合分类、多阶(说人话,比如斜率)等各种复合方向,套业务需求形成二次计算过的专门指标,尽可能减少数据维数(好吧用人话来说,就是列数),只留下最关键的优化过的复合维度,并且尽可能合理地处理(或解释)源数据的瑕疵。
这时会发现当一切准备好以后(花了95%的时间),现成的一堆模型和验证打分工具,直接去跑,对比结果就好了。后续整合发布到生产(实时推荐之类)等等的工作,已经不算数据工作流,而是进入传统互联网产品流程,双方对彼此来说都是黑盒。
回过神来,你可能会说,那这些现成的模型靠谱么?
我们进入4的世界,桃花源里的学术世界
学术世界的仙人们其实和1一样,远离整个数据工作的对于企业来说的初衷,他们既不考虑数据怎么来的,也不考虑某种生活现象为什么要服从某种分布,这里只关心模型本身的数学特征(和流派),对123世界的凡尘俗世的人来说,也许刚毕业的时候还期待大数据应该是玩4,工作一段时间以后才发现2才是真相。
只有很少的人能一直留在学术道路上,虽然统计学是数学里很low的分支,但是却是最接地气的分支,比如,你能把图片的模糊和精细,往颜色值的矩联想么?统计学家会告诉你这是常识,根本不用解释。可见概率的思考方式,会导致比程序员思考模式更大地有异与常人。
那么图上4为啥能回到1呢?
我们回到3的BI工程师队伍里,如果建模以后,发现运气不太好,无论参数怎么调,匹配的程度都并不好,那么有两个方向:
一个是比较PR比较酷的方向,例如不断尝试学术世界4的新模型,或者干脆搞kaggle这样的数据大赛,征集学生的突发奇想,避免数据规约中的"历史经验‘’路径依赖,时髦的说法叫产学研联动;
另一个更契合实际的方向,是把匹配失败的例子抽样出来,看看是不是漏掉特征,没洗干净,或者需要额外维度之类,总之去步骤2和步骤1里补,这个方向很苦,一点也不酷。
注意大部分PR文章说的大数据”不需要理解为什么,只需扔进去所有数据,然后看结果“,就是指预期的匹配失败,反而发现一些意外结果的情况。
实际上绝大多数进入建模分析的都是精挑细选过的维度,是经过反复认真的调研和理解的,只是结果有偶然发现而已。不可能是随意乱看,性能不允许。
这样一来,4就回到了1,经过这样一个循环,越来越多的数据被采集,被指标化,和被用来建立老师傅经验函数,以解决实际问题(而且老师傅函数可以嵌套迭代,这对现实世界的老师傅来说就有难度了)。
作为结尾
全局看工作流可能并不解决实际问题,但是经常定位自己和周边,是不错的习惯。
而且这个简单的圆圈1234图也可以作为一个所谓职业规划的大体方向,毕竟现在查询如何转行大数据的关键字流量是越来越高了。
谢谢阅读。
作者 scvhuang
关键字:产品经理
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
