与算法攻城狮一起工作时,产品狗需要做什么?
在过去的一年中,有幸参与了一个全新算法的从立项到最后上线,感触颇深。所以今天来聊聊整个过程中产品经理都要做些什么工作。
一、概念普及
算法:标准概念
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。
算法中的指令描述的是一个计算,当其运行时能从一个初始状态和(可能为空的)初始输入开始,经过一系列有限而清晰定义的状态,最终产生输出并停止于一个终态。一个状态到另一个状态的转移不一定是确定的。随机化算法在内的一些算法,包含了一些随机输入。
来自:百度百科
看不懂有木有,那么通俗版本解说一下:
算法就是一个问题的解决方法,可以理解成高中时候做的应用题,题目会给你一些已知条件(输入),让你根据这些已知条件,求出最后的解(输出)
二、算法问题提出的准备
根据上面算法的定义,当我们决定新开发一个算法的时候,这个题目(需求)肯定是来自产品。作为出题者,我需要给研发出一道题目,利用产品已有的一些数据,产出一个希望得到的需求。
为了让这个偏技术的文章没那么枯燥,我们还是用举例的方式(怎么办,我超爱举例的,这可能已经成为我的文风了)来描述准备提出新的算法问题的流程。感谢提问的来自某二次元社群的产品黄同学。
按照黄同学给我的描述,他想做一个这样类型的推荐算法:
1.在APP端的某个tab页上,做一个短视频的瀑布流。
2.这个瀑布流里的内容主要是平台推荐给用户的一些用户可能会喜欢的视频类型,
3.做这个需求的目的:增强用户黏性、吸引新用户留存的目的。用户每次刷新显示的结果要有区别和不同。
那么我们首先要做的就是拆解问题,把问题从一个口语化的语言转换成略微程序化的语言。(这里就简单写一下,具体的这种准备还是要准备更加详细的PRD为好,里面的数值都是我瞎写的,具体指标还是要黄同学自己来确定。)
- 输入: 每个用户都有的个性化标签(包括喜欢的二次元内容的种类、常用的论坛分区等),论坛已有的热门视频队列,论坛所有的短视频队列,
- 限制条件: ①在每次给用户出现的新的推荐视频队列中,需要按照一定比例n,来展示热门内容和猜测用户喜欢的内容。②多次刷新时推荐视频队列中有一定比例m出现新内容。③用户喜欢的内容,根据用户个性化标签的特征向量的方式来设置用户不同标签的视频显示在C端的权重比例。④热门指数需要通过一定指标来确定来源。
- 输出: 一个符合用户爱好的推荐视频队列。
- 指标检测标准: 用户在tab页上面的平均留存时间超过30s的比例超过50%,单个推荐视频的停留时间超过5s的比例占所有观看视频数量的60%以上,每次出现队列中用户观看的数量占本次推荐视频的80%以上。
这样看起来,就是一个合格的能够快速让研发get到精髓的问题。问题提出之后,算法攻城狮们就会进入到紧张的解题过程中。这个阶段你需要做的,就是稍微了解一下他们的解题思路是否和你想象中的有偏差,确认最终的所要达到的效果是否能够满足你的需求。
最后黄同学给出的他们团队确定的方案(确认的无比顺利、老板也没意见、黄同学很开心的样子)如下,希望对在看这篇文章的各位有所帮助: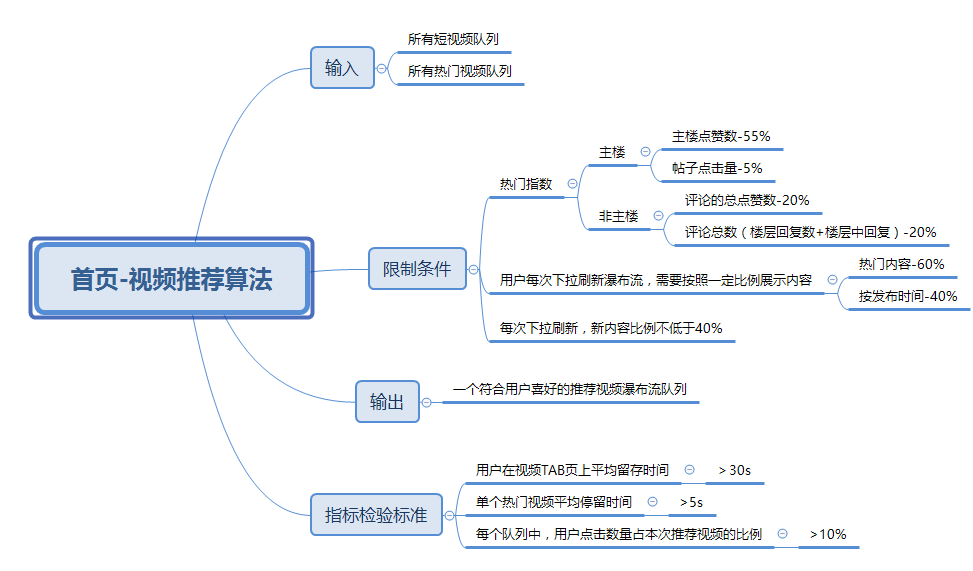
三、算法研发过程中你需要帮助研发准备的
人工智能算法的基础就是数据。不管是推荐算法、语音识别、自然语言分析、模式识别、机器学习等等这些看起来高大上的算法都离不开一个东西:数据。
在介绍你需要给研发准备的东西之前,这里还要介绍算法的3个概念:测试集、验证集、训练集。
在机器学习和模式识别等领域中,一般需要将样本分成独立的三部分训练集(train set),验证集(validation set ) 和测试集(test set)。其中训练集用来估计模型,验证集用来确定网络结构或者控制模型复杂程度的参数,而测试集则检验最终选择最优的模型的性能如何。
来自:百度百科
OK,再用个通俗化的语言来简单解释一下这三个名词:
- 训练集:我拿N个用户作为样本案例,先来验证一下我这个算法跑不跑的通,能不能推荐出来对应的结果
- 验证集:我拿一些和之前不同的用户,他有更多更复杂的用户标签,我来试试在复杂情况下的我出来的结果是不是符合预期。
当这两个都算完了,攻城狮也都调教好了推荐算法中的不同标签和内容的比例了之后。就要用到测试集这个东西了。
- 测试集:我取一些从来没跑过推荐算法的用户作为样本,跑一遍算法,这些用户用某种方式抽取没有特定的规律,然后看输出的推荐集合是不是满足自己的要求。
尽管,研发可能根本用不到你去专门制造一些数据,(毕竟人家搞算法的,还有专业的测试去做整个算法的训练集和验证集的构成),但是如果你能参与到其中的一小部分,可能会对结果有一定的帮助。
例如,准备一些你觉得有这样的输入应当给出什么样的输出结果,比如我更喜欢日剧和美剧,我就希望推荐里更多的就是日剧和美剧,再加一点点动漫。
例如,具体推荐内容的比例(你期望的输出)可能会影响到用户留存(你希望通过算法解决的问题)的权重,还是要产品经理去确认。当然最后的算法的优化,还是要利用长时间的收集用户数据来完成。
四、验证效果
很多时候,一个算法的1.0版本总是差强人意的,尤其需要大量的数据去训练的这些最近很时髦很流行的(人工智能、机器学习、模式识别)算法。(这些算法有机会可能会单开一个文章去讲讲非技术出身产品经理如何理解这些看起来高端洋气上档次的算法,其实并没有想象中的那么复杂或者高端。)
当新算法上线之后,你需要一段时间去收集用户反馈的新数据。按照上面的这个例子,应当就是收集用户在tab页上面的平均留存时间超过30s的比例,单个推荐视频的停留时间超过5s的视频数量占所有观看视频数量的比例, 每次出现队列中用户观看的数量占本次推荐视频的比例等等这一系列数据,然后根据数据结果的优劣,再让研发重新调整对应的权重和参数,来达到最终的目的(增加留存blablabla)。
以上就是描述一下产品如何推动算法研发的一个小例子咯。当然我自己做的算法不是推荐算法(是排课啦,NP困难问题比推荐难大约一个量级),但是和算法工程师工作的流程基本上不会有改变,希望大家在碰到类似的工作的时候不要一脸懵逼,不知道如何下手。
作者:CresYan,3岁B端教育行业产品经理,大龄失业女青年,猫奴,欢迎勾搭~(≧▽≦)/~
关键字:算法工程师, 攻城狮, 产品狗, 产品经理
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
