如何设计一款有温度的AI产品?(三)
接上文:
- 如何设计一款有温度的AI产品?(二)
- 如何设计一款有温度的AI产品?(一)
两个小家伙天天活力无限,抱歉拖更有点严重,祝大家新年新活力,岁岁福满堂。
一、和大家汇报下亲音AI这款产品的进展
做这个产品的初衷,通过AI科技的途径,见到已逝的心心念念之人,弥补心里的遗憾,也让AI变成有温度的科技,而不是冷冰冰商业变现或是人力的替代,目前初版产品已经研发完成了,将实时的Taking Head转换成文字方式,1.5版本会将实时视频放出来(WIFI环境下实时延迟5秒以内)。
发展方面,也有几个投资人想要对这个产品进行投资,我还是想保持下初心,让我的两个孩子看看他们没有见过的爷爷,投资的事项我可能要放后面一点,在另外一个实时Agent RPA的项目上商业化,这个产品还是单纯的自私一点。
二、1.4版本的产品设计相关
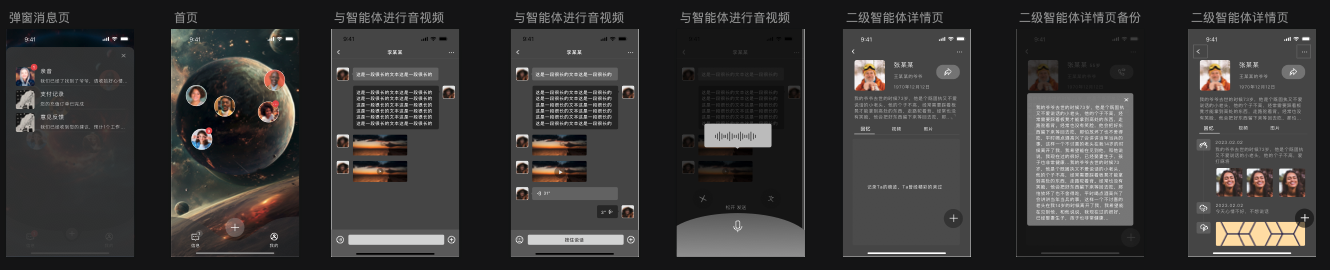
想来想去,还是V信是最习惯的沟通交互,所以你懂的像素级Copy(这被设计师朋友作为了一生的耻辱,已经和我断交了,设计了九个版本从0.5到1.4,最后改回了最初的交互,他说以后连眼神都不会和我进行交流…)。
三、几个版本的设计理念
1.4的版本设计中,智能体Agent可以主动的和人进行交流,图片,语音,文字,视频都会主动的进行发送,当然这些还是基于规则层面的,还没有达到一个智能体Agent该有的高度(能感知环境,感知交流人的情绪,安抚并善于沟通,独立推理思考这些),近期也会发布到应用市场。
1.5版本中,会加入基于RAD-NERF的实时视频相关的能力,这个改动会相对大一些,1.5版本才是我最最想要的东西,所有的思考都是源于可视化的实时交流。
1.6版本中,会将采用AI Agent框架重写下,当前智能体的交流方式,从被动Prompt,到主动使用摄像头感知交流者的情绪、当前环境,为智能体创造一个可以生存的虚拟灵域,这个并不是天方夜谭,一个微模型的环境中,有人类所需要各种设施,智能体可以生活中这个小镇中,彼此可以交流并保持长期记忆,每一次的沟通智能体都会更像自己的心心念念之人。
四、实时Agent的一些思考和技术实现
目前采用的是基于RAD-NERF的低纬特征进行音频面部驱动的,说实话论文的中的理论部分没看懂,好多公式还得先Google下才能稍稍理解。
通俗来讲就是根据一段视频,先分离音频,将视频分为一帧一帧的图像,然后通过3DMM等模型分割人像,加入背景图片进行头部、唇部、身体部分训练得到训练好的人物模型,最后通过文字转语音驱动当前的任务进行Talking head,实时将每一帧推送给需要的播放端,所以对产品的挑战就是,需要有人物的声音,视频,作为训练素材,背景不能有杂音,视频动作需要有规范。
一些改进的思考,首先speech to text耗时有一些,目前一些模型也支持,语音生成语音openai 或是达摩院的一些产品,可以省去音频转换部分的IO消耗及网络相关的耗时,推流部分应该前后有衔接动作或是语音的暂停1-2秒,更好的衔接,还有就是虚机配显卡的环境适合测试,真正使用还是需要物理机,推理性能提高10%以上,还是有很大帮助的,这部分我会单独发布下包括后面的源码。
最后,还是保持初心,科技是生活的一部分,不是全部,身边的人是最需要关注的。
未完待续。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
