大数据人才,到底应具备哪些技能?
我是西索,最近这段时间,和几个大厂的TL 做分析「价值」方面的探讨,在大数据时代要怎么才能发挥更高的数据价值,刚好涉及到这部分的讨论,把讨论结果做个分享,供同行参考。
这几年听到最多的一个声音,我们要开始“卷”价值了。那么“你的价值体现是什么?”、“当前还有多少价值可以做”、“接下来我们要创造什么价值”…
一、认识数据分析流程
对于刚入行的同学来说,需要了解大数据分析过程中涉及到的流程和环节,再结合大数据的要素进行能力拆解。
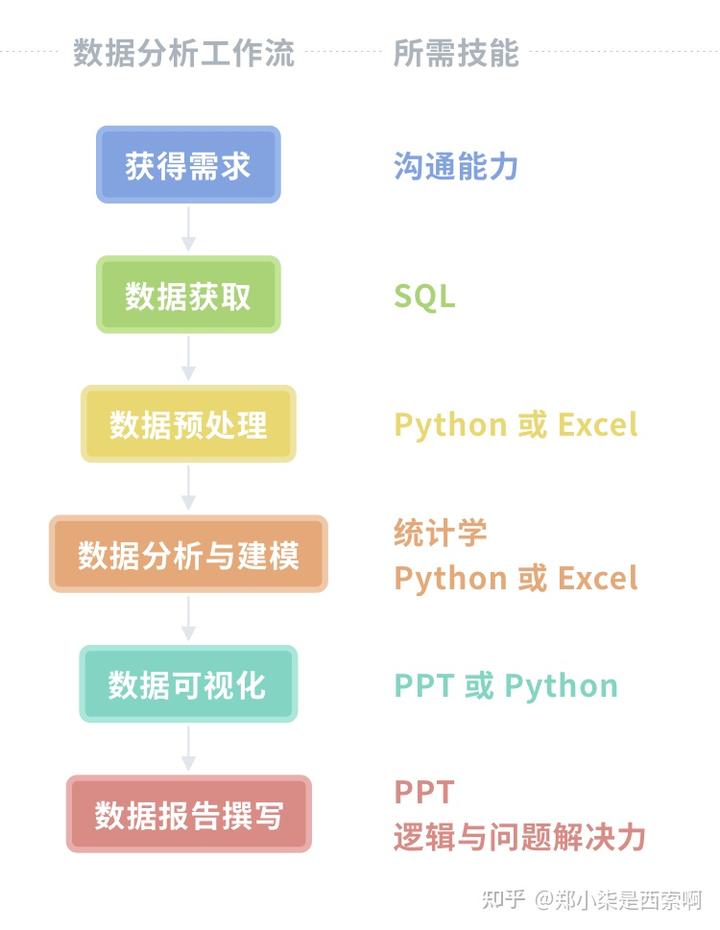
1. 认识大数据架构能力
以下是一个比较典型的大数据架构:
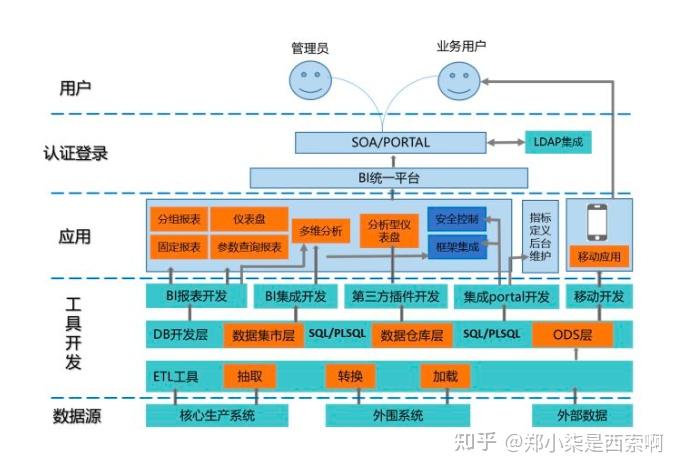
3. 认识大数据指标体系
关于大数据工具的介绍,可以参考这篇文章:大数据常用工具集合。
三、做好大数据需要储备的职业技能
我们把职业技能划分为显性和隐性两个方面,从大数据各种岗位的job model中可以抽象成为集中能力,见下图:

2. 常用的统计学知识
分析过程可能是做一些探索性数据分析、统计分析、机器学习建模,甚至是做AB测试实验,最终交付分析报告。数据分析离不开统计学、运筹学,以下罗列了日常过程中经常用到的统计方法。

3. 重要的商分类知识
“无场景不分析”、“脱离业务场景的分析都是耍流氓”等资深数据分析师的建议无不说明业务场景的重要性,数据分析在不同场景下,也有不同的“分析”招式来满足不同的业务需求,熟悉下面的商业分析模型有助于建立业务信赖。

4. 掌握的算法类模型
有监督模型,对于企业销售的预测、还是对用户行为的预测,都能帮助提升业务效率。比如常见的预测用户流失分析,及时得到高概率流失的人群名单,运营通过提前营销干预,提高用户留存率。
无监督模型,可以应对未知模式的分析。譬如,不知道应该把现有人群分成多少个组来进行营销最合适,就可以对人群基于核心特征做无监督的聚类分析,得出有效分组的界限。
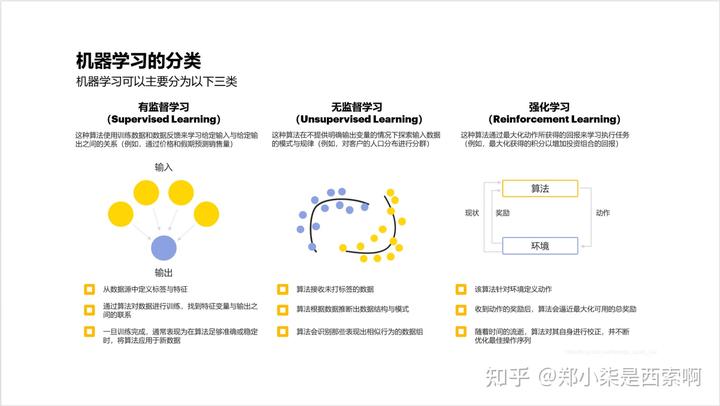
5. 机器学习和深度学习算法
几个基础概念:
- 数据集合:训练集、测试集、验证集;
- 数据检查:描述性统计(最大、最小、中位数、众数、四分位)、缺省值填充、卡方分布;
- 数据校验:共轭线性、相关系数(Pearson Correlation Coefficient);
- 特征工程:什么是特征工程、特征工程构建、特征工程权重查看、特征选择(filter/Wrapper/Embedded)
- 归一化:虚拟变量,labelEncoder/OneHotEncoder/get_dummies;此外可以参考核函数构建方法,通过log、ln、e的方式构建,缩小极大值之间的数据离散度;
- 数据标准化:z-score、max-min scaling;
- 算法校验:卡方校验、5-fold、
机器学习:
知识重点:距离、信息熵、梯度、L1/L2、鲁棒性(稳定性)。
L1-曼哈顿(绝对值相加,不唯一解)、L2-欧氏距离(欧几里得距离之和,平方和,唯一解)。
无监督学习:
聚类(cluster):k-means、cart(核心是距离-欧式/马氏/曼哈顿/切比雪夫,高斯密度/正态分布)。
半监督学习:
监督学习:
回归(logistic):线性回归、LR(ridge/lasso,L1/L2)、预测(Arima、prephet);
分类(classification):KNN、Decsion Tree、XGBoost、Random Forest、GBDT、SVM、Bayes。
深度学习
知识重点:损失函数、核函数。
用途:文字识别、图片识别、语音识别、视频处理。
文本挖掘:
NLP:tf-idf、LDA、CBOW、word bag
目标检测:
神经网络:BP(CNN)、RNN、LSTM。
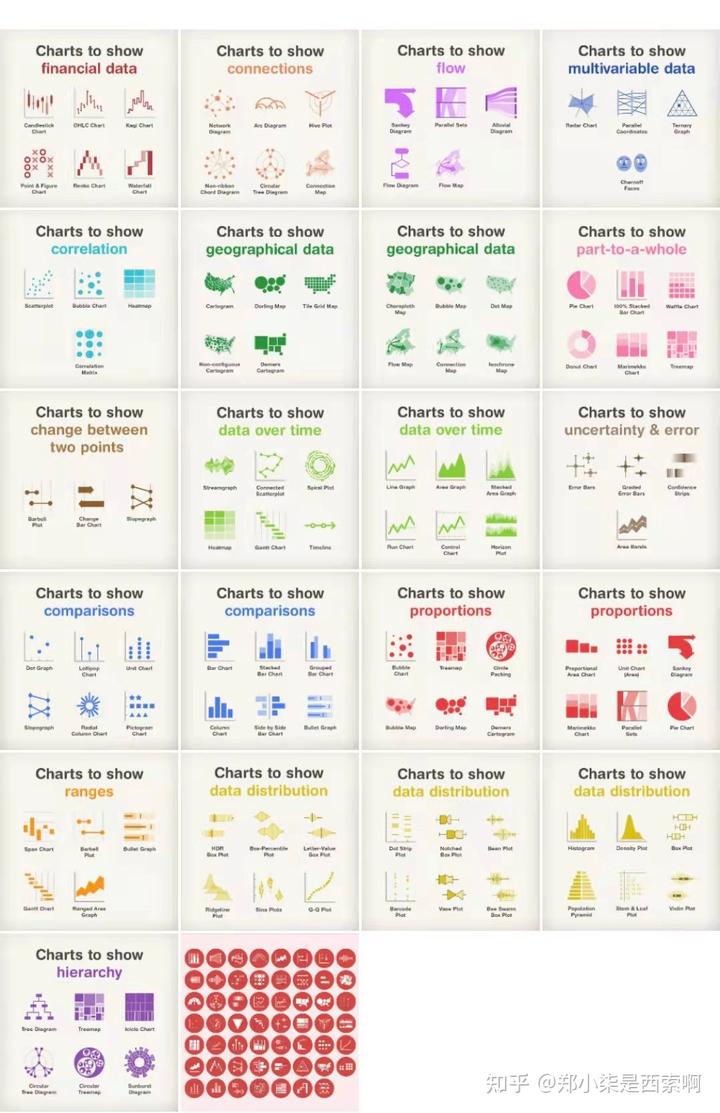
6. 数据可视化的能力
图表是数据可视化的常用表现形式,是对数据的二次加工,可以帮助我们理解数据、洞悉数据背后的真相,让我们更好地适应这个数据驱动的世界。
四、擅长的·爱好的·世界需要的
在布赖恩·费瑟斯通豪《远见:如何规划职业生涯3大阶段》一书中提到,你要不断问自己这三个问题:我擅长什么?我爱好什么?这个世界需要什么?三者交集的部分,找到自己的目标,当前应该做哪些方面的刻意练习,强化优势,用长板补短板。
工作规划,是结合公司整体方向而开展的规划过程;个人规划,是结合个人职业发展而开展的规划过程;彼此之间的交集在于,如何通过规划把两个方面进行融合!
而个人职业成长旅程中有三个定位:岗位定位,管理定位,行业定位。
- 28岁前,用岗位专业定位自己,你干啥最专业?
- 32岁之前,用管理角色定位自己,你做项目、带团队、搞运营的能力怎么样?
- 38岁之前,用行业品类定位自己,你在哪一个行业领域做到了顶尖?

版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
