搜索策略产品经理必知必会
一个完整的搜索引擎应该有的功能模块,从用户使用搜索引擎进行查询,到最终得到查询结果,一般需要经过5~6个环节,常见的流程包括建立物料索引、查询语义理解、召回、粗排、过滤、精排、重排,最终在前端为用户返回搜索结果。接下来将对每一模块进行详尽的介绍。
1.搜索引擎实体识别
实体识别可以理解为搜索引擎对检索词的认知。认知首先需要一套标准认知体系。
1.1.实体识别是什么?
实体识别,全称命名实体识别(NER,named entity recognition),指对检索词中具有特定意义的语义实体进行识别,根据识别的结果构建召回策略和排序策略。
实体识别依赖于我们针对当前业务场景构建的实体体系,即认知体系。
实体体系即该领域具有特定意义的语义实体。例如电商领域的实体体系可以简单分为品牌(brand)、一级品类(CATG1)、二级品类(CATG2)、三级品类(CATG3)、尺寸(size)、颜色(color)、产地(origin)等。
1.2.实体体系的构建

构建实体体系时,需要结合业务的实际情况进行判断。
2.搜索引擎词库
针对每一个领域设置好对应的实体体系后,需要针对实体体系里的每一个实体类别构建词库。词库中的每一个词都需要具备词频和词性两个基本属性。词频用于统计在实际语料里面该词出现的频次,后续其他策略要参考这个指标,词性表示该词的性质。
词库的构建一般分为两种:开源词库;人工标注。
- 开源词库:以网上开源词库为基础,人工二次筛选符合业务场景的词,目前开源词库有SogouW、THUOCL。
- 人工标注:基于用户的历史检索词进行人工标注。没有捷径,必须不断积累。
3.搜索引擎物料索引
高效的索引是搜索引擎检索的基础,主要有两种:正排索引;倒排索引。
- 正排索引:遍历所有物料,查找物料中是否存在与检索词相匹配的实体,如果存在,则记录物料SKU ID(电商),最终查出所有包含该查询词的物料。
优点:构建索引简单且迅速,方便管理。后续加入or删除,可以直接添加/删除。
缺点:必须遍历所有的物料,检索效率低下。
- 倒排索引:以词或实体为关键词进行检索,表中的每一行记录为包含该索引关键词的物料在平台上的表示ID。
优点:检索效率极高,可以快速检索出查询词对应的所有物料
缺点:初期构建和后期维护较为复杂,新增/删除时涉及多条记录的修改。
- 正排索引与倒排索引的差异:正排索引是物料对关键信息的映射,倒排索引是关键信息到物料的映射。实际工作中均使用倒排索引进行信息检索,后使用正排索引进行信息补全。
针对物料构建倒排索引时,物料的信息来源有以下三种:标签体系;物料标题;物料正文内的实际内容(小红书)。
4.搜索引擎查询语义理解
当用户搜索时,搜索引擎首先要理解用户的搜索意图,通过对检索词进行一系列智能分析,对检索词进行归一化、纠错、分词、实体识别、类目预测,再进行搜索结果的召回和排序。
4.1.归一化
查询语义理解的第一步是对检索词进行归一化处理,一般包含以下几个步骤:大小写统一。把所有大写都转为小写;将拼音转为汉字;将英文转为中文;去除特殊符号。
4.2.纠错
归一化处理的下一步是纠错。检索词纠错是搜索引擎必备的基本功能,有助于提升UE、降低用户重搜率、扩大召回结果,提升平台整体搜索效率。
- 中文检索词常见的两种错误原因:1.拼音原因 2.知识错误
- 检索词纠错方法: 1.基于词典的方法 2.基于规则的方法 3.基于N-Gram语言模型的方法
简单介绍下N-Gram语言模型的基本原理。语言模型是评估文本序列符合人类语言使用习惯程度的模型,用于综合评估该序列在日常生活中出现的概率和语法上合理的概率,一个语言模型上所有句子出现的概率和为1。
N-Gram语言模型基于马尔代夫假设,随意一个词的概率只和它前面出现的有限N-1个词有关,基于以上假设的语言模型即为N-Gram。模型基于分词后的短语进行基于中文编辑距离和拼音编辑距离的相似短语召回。
检索词纠错的评估指标:召回率、过纠率。
- 召回率 = 错误检索词被纠正的个数/错误检索词的个数
- 过纠率 = 正确检索词被纠错的格式/正确检索词的个数
检索词纠错的触发方式:词典触发;零少结果触发;直接针对原始词进行纠错
4.3.分词
在中文中,词代表具有独立意义的最小语义单元。检索词分词的目的是将整个检索词切分为一个个独立的词,然后做进一步处理。然而分词过程中面临着同一个语句有多种切分方法、未登录词识别等挑战。
常见的分词方法有三种:基于词库、基于语言模型、基于字

分词的评估标准:一般用5个指标进行综合评估,精准率、召回率、F1、未登录词召回率和登录词召回率。
- 精准率(P) = 实际分词后得到的正确分词数/实际分词后得到的词数
- 召回率(R) = 实际分词后得到的正确分次数/正确分词后得到的词数
- F1 = 2PR/(P R)
- 未登录词召回率 = 实际分词中精准识别的未登录次数/语句中出现的未登录词总数
- 登录词召回率 = 实际分词种精准识别的登录词总数/语句种出现的登录词总数
在应用分词结果时,很多次如“的”“地”“得”等时不具备语义的,对后续环节没有任何作用,这类词被称作停用词,在最终的分词结果中予以去除,以减少后续环节的计算量,降低处理复杂度。
4.4.实体识别
当检索词经过分词后,我们需要为每一个单词匹配对应的实体类型,常见的方法有以下两种:基于词库的识别方法;基于序列标注模型的识别方法。(主要用于识别不在词库里的实体词)
在实际工作中,无论使用哪一种实体识别方法,首先都需要构建实体体系,然后在现有的实体体系框架下进行实体识别。
4.5.类目预测
类目预测有助于更好地计算检索词和物料之间的相关性,并应用到后续搜索类目导航功能中。
常见的类目预测方法有以下三种:
基于人工规则:通过日志信息将热门检索词提取出来,然后人工匹配检索词和相关类目。
优点:可以实现快速上线
缺点:可拓展性差,人工运营成本较高,在搜索引擎初期使用。
基于用户行为的数据统计
优点:利用用户历史行为数据,可以从数据中学习,具有一定拓展性。
缺点:对于长尾检索词的覆盖度较低。
基于类目预测模型:前两种方法的类目预测覆盖率都很低,拓展性也一般,实际工作中需要构建专门的模型。
1.构建类目预测模型的第一步是构建训练样本,在电商领域可以将商品标题或用户历史检索词与对应类目构成一对,一对代表一条训练样本。类目预测模型是一个多分类魔影,一个检索词可能对应多个类目,目前行业内多使用DNN模型进行构建。
2.针对类目预测的相关性设定阈值。
在实际应用时,一般将类目预测模型分为线上、线下两部分(由于线上模型对实时性要求很高)。
优点:泛化性强,对于长尾检索词,类目预测的准确率很高。
缺点:线上模型耗时较多,需要设计合理的系统架构。
4.6.查询改写
一方面针对简洁的检索词尽可能地扩充召回条件,丰富召回结果,另一方面针对复杂的召回词精简条件,提升召回效率。
常见的方法有两种:
1.基于同义词的改写
2.对于长尾检索词通过其他辅助行为信息来进行改写。
5.搜索引擎召回策略
和推荐系统一样,召回模块决定了搜索引擎整体效果的上限。搜索引擎常见的召回策略有三种:文本相关性召回;语音相关性召回;个性化召回。
策略一:文本相关性召回——对原始检索词进行实体识别后构建查询语法树(实体重要性、预测类目召回),再和倒排索引里面的实体进行匹配。(注意匹配规则)
策略二:语义相关性召回——基于原始检索词的隐语义和物料标题信息隐语义向量的相似度进行召回。(构建语义相似度模型、相关性控制模型)
策略三:个性化召回——本质上还是语义相关性召回,更充分考虑了用户的个性化行为数据。
6.搜索引擎粗排策略
粗排逻辑的关键在于在召回的上万个物料中初筛出和检索词匹配度较高且用户比较感兴趣的物料,量级由万到千。为了更好促进用户转化和维持平台整体生态建设,粗排阶段会加入更多考核指标。公式如下
$$Score_粗=a*相关性分 b*质量分 c*转化效率分$$
在粗排环节必须对物料和检索词的相关性进行严格把控,在召回策略中,一些宽泛的检索词可能匹配非常多的物料。在粗排环节需要通过相关性分数进行初步把控,首先需要计算每个物料和检索词的相关性。
相关性分数 = a*文本相关性 b*向量相关性 c*个性化相关性
物料质量分一方面取决于物料历史线上表现效果,另一方面取决于物料的创作者和商家对平台整体生态建设的贡献。以电商平台店铺星级分为例:简单四维度权重分布转化成公式:
店铺星级分 = a*流量分 b*转化分 c*服务分 d*售后分
转化效率分主要由物料的CVR和CTR两方面评估得出的,为此需要构建专门的CTR和CVR预估模型,目前通用的是DNN算法,只不过相比于推荐场景,在搜索场景模型需要加入更多的检索词特征。
补充:因子间耦合严重导致因子计算方式的调整会引起超参数变化,这时可以划分区间解决。
7.搜索引擎精排策略
7.1.排序策略与特征
精排环节的排序分为相关性排序和多目标排序。
相关性排序:很多公司起初并不具备精细设计排序模块的能力,一般会将粗排、精排、重排融合在一起,仅通过召回阶段的相关性分数排序。千人一面,但可以保证检索词和物料的相关性。
多目标排序:$$Score_精=a*相关性分 b*质量分 c*转化效率分$$,因子权重与粗排公司不同,更侧重转化效率分,模型特征和网络结构远比粗排模型复杂。
在搜索场景中,相比于推荐特征,搜索特征增加了一系列以检索词为核心的特征。
7.2.PageRank算法
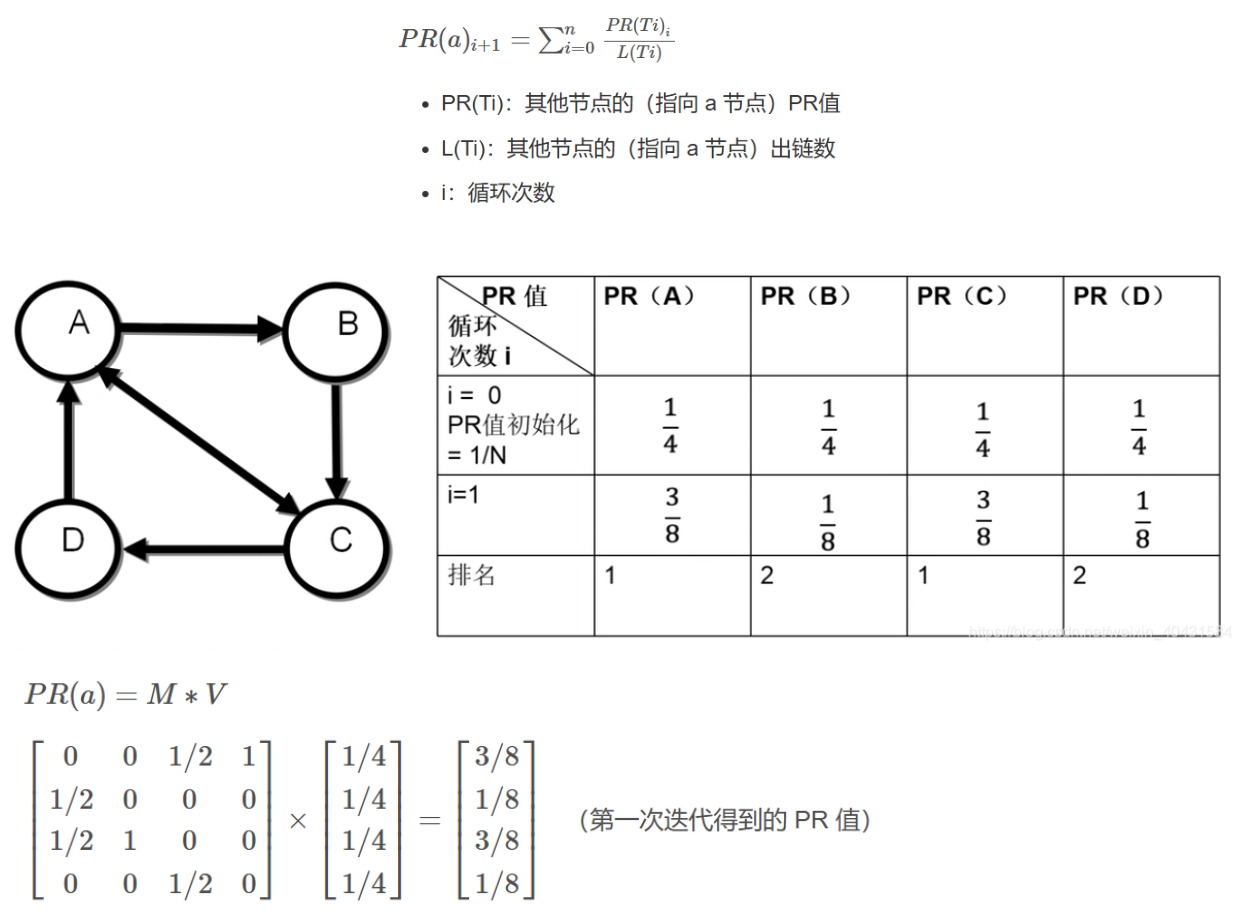
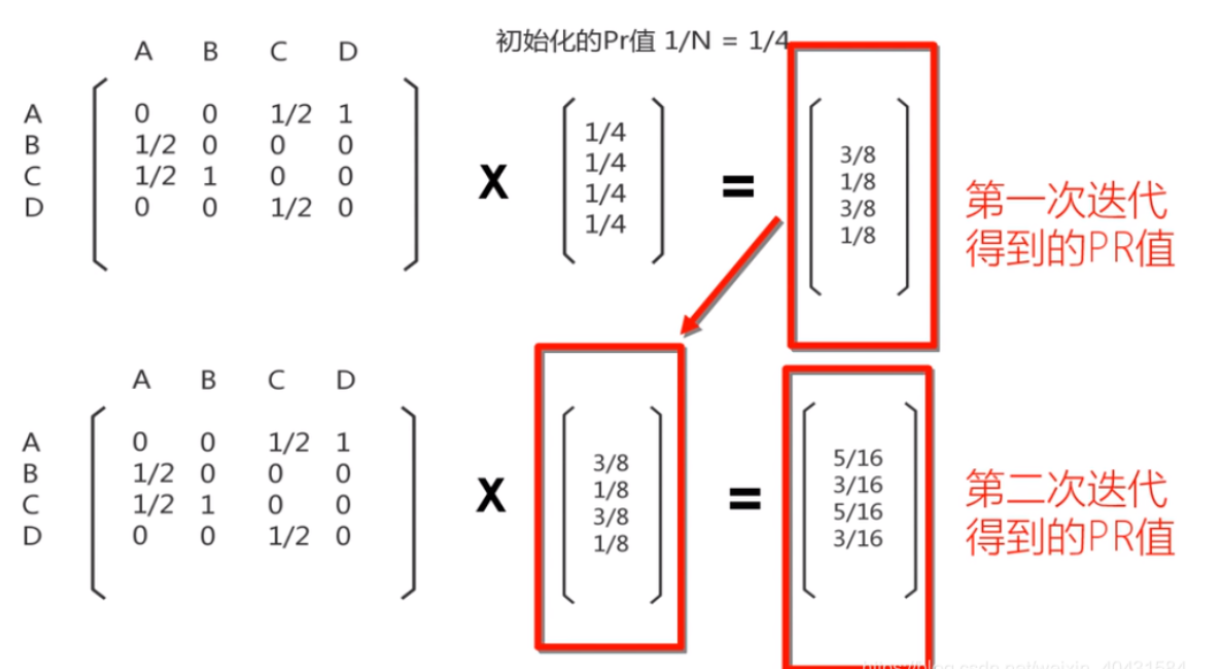
7.2.1.基本假设:
1.数量假设:一个网页被其他网页链接的越多,则该网页越重要。
2.质量假设:一个网页被高质量网页链接,则该网页质量很高
7.2.2.基本算法:
将互联网想象一张图网络,网络上每一个节点(node)就是一个独立的网页,如果两个网页之间存在超链接关系,则它们之间存在一条有方向的边(edge),每个节点向外链接的节点数被称为该节点的出度,每个节点的PageRank值(以下简称PR值)表示该节点的权威性。
8.搜索引擎重排策略
重排环节起到的作用和推荐系统一致,也分为全局最优策略、用户体验策略和流量调控策略。搜索场景中用户带有明确的意图,所以序列优化的收益没有推荐场景大。搜索场景对物料多样性的要求远远不及推荐厂家,搜索场景一般基于检索词返回结果,大多数情况都是相同类目,一般针对同商家、同创作者、同首图进行打散,也使用推荐策略中讲到的滑动窗口法。
搜索和推荐是App的两大主要流量场,但在电商App中,如淘宝平台70%左右的GMV都是由搜索场景转化的哦!
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
