AI产品经理是如何理解机器学习的(附注释)
本期目的:回顾之前敲代码的日常,利用生活场景帮助AI产品经理认识机器学习及学习过程中常用算法和评价指标。
适用读者:AI/数据产品经理。
阅读重点:品,细品,结合班级故事再品。
最近看了很多关于机器学习相关的文章或书籍,可以归结为两类吧。第一类,百科型:说它是BD百科吧,它不如BD百科智能,说它不是BD百科吧,它只能给你拽名词解释名词,还解释得特别专业,晦涩难懂。第二类,伪专家型:满满的全是干货(太干了……)。各种专业的名词,专业的数学公式,小白看不懂,专家懒得看,完全没有发挥出那一堆文字的价值。
本文将全程通过讲故事聊天的方式介绍机器学习,让小白也能学会机器学习原理。总共分三部分:认识机器学习、机器学习原理和常见问题、案例实操。
1)认识机器学习:普及一下机器学习的基本理论(定义、场景、分类、要素等),方便小白同学更好地进入状态。小灰同学,也可以对照基本理论,沉淀一下自己的项目经历。很多知识一遍是学不明白的,多学几遍,每一遍都有不同的收获。
2)机器学习算法原理评价指标:介绍一些常见算法、怎么评价不同模型的好坏。
3)代码实现:通过逻辑回归案例,认识机器学习的工作流程。本章会设计代码操作,非技术人员可以跳过代码,看注释文字,不懂代码也能看明白机器要怎样才能学习到历史规律的。
一、利用生活场景认识机器学习
1. 相关名词介绍
机器学习(ML)、深度学习(DL)、自然语言处理(NLP)、计算机视觉(CV)等,相关名词介绍去B度百科搜索一下,那里比我解释的详细。相关名词还是有必要了解一下的,这样有助于理解后边的学习内容。
产品经理要懂业务也要懂技术(最起码专业术语要了解),尤其是数据或AI型的产品经理。可以去这个地址(http://dict.code-nav.cn/)学习一下,好心人整理的编程词典,汇集了计算机大部分领域的专业术语。向好心人致敬!!!
2. 定义
定义:为了解决任务T,设计一段程序,从经验E中学习,达到性能度量值P,当且仅当有了经验E后,经过P评判,程序在处理T时的性能得到提升。
定义虽然有点绕口,但是已经把机器学习的原理讲的很明白了。需要你品,而且静心细品。联想生活实例,咱们小学学习写字时,是怎样的一个学习场景?
- 为了写字工整好看(任务T)
- 我们照着课本写,照着字帖写,照着同学的写(经验E)
- 直到有一天,老师说,“瞧你写的一手好字”(度量值P)
化悲伤为动力,你反复练习,老师多次指导,日复一日,年复一年……
- 小学六年级的铅笔书法大赛(处理任务T)
- 你拿着写好的大字(已经有了经验E)
- 请老师点评:恭喜你小学毕业了(通过P评判)
故事讲到这里,你应该能品明白这句绕口的话了吧(任务T),如果还不明白,就反复去品更多故事(经验E),直到品明白(评判P)。
3. 应用场景
无人驾驶 、人脸识别、语音识别、智能互动(小爱)、个性化广告。

4. 机器学习有哪些分类
按学习方法可以分为:有监督学习、无监督学习、强化学习;
按任务类型可以分为:回归、分类、聚类和时间序列。
强化学习和时序分析比较少见(fact:我还讲不明白),可以共同讨论。

(看图识意1.0)
5. “监督”是什么意思
对于机器而言,就是用来学习的数据集,有没有明确的标签(回归也是有标签的,只不过是连续的)。就好比,你在学习写字的时候,众多的参考文字中,老师有没有告诉你,什么样的字代表着好,什么样的字代表着不好。
1)有监督学习(有标签)
分类,样本标签属于离散变量(垃圾邮件、肿瘤检测),ChatGPT就属于分类问题中的生成模型。

回归,样本标签属于连续变量(预测房价、预测销售额)。
2)无监督学习(无标签)
聚类:用户分群,朋友分组(朋友分组),细分市场,异常流量监测。
降维:线索太多可能干扰判断,影响判断速度及准确度。
6. 学习方法三要素
模型、策略和算法是学习方法的三要素。不要急,咱们先专业得讲,再结合生活实例去理解他。
1)模型
- 要学习的概率分布或决策函数(这就是模型,这就是模型,这就是模型!!!!!!)
- 假设空间:所有可能的条件概率分布或决策函数构成的集合
2)策略
从假设空间中学习最优模型的方法称为策略。衡量模型好与不好需要一些指标,这时候我们引入损失函数来衡量,衡量预测值和真实值的差距。常用损失函数有:0-1损失函数、平方损失函数、绝对损失函数、交叉熵损失函数等。
3)算法
计算损失函数最优解(可以理解为最小)的方法。
看完上边的解释小白同学可能一脸蒙,算法的同学可以去深究一下具体有哪些实现的方法和公式推导。对于产品经理实在理解不了,也不勉强,毕竟产品经理靠脑子比较吃力。不过我们可以通过接下来的生活场景去理解模型、策略、算法三个层面含义。
故事背景:
学校要组织数学竞赛,每班只允许推荐一名同学参加。小白的班里共50名同学。为了班级荣誉,班主任打算在这50名同学中选择一个数学成绩最好的去参加学校的数学竞赛。
如何选择找到这名数学成绩好的同学呢?用什么指标评判数学成绩好坏呢?是最近一次月考成绩?还是期中或期末成绩?还是下半年或本年度平均成绩或最高成绩?
班主任考虑到数学竞赛是考察数学方面的综合能力,既要考虑这名同学对知识掌握的全面性又要考虑稳定性。最终决定:参评分数 = 期中成绩 * ⅓ + 期末成绩 * ⅔ 。谁的参评分数高,就代表谁的数学成绩好,可以代表班级参赛。
参照机器学习:
每名同学都是一个模型,班级50名同学组成了假设空间;众多的评判指标(期中成绩、期末成绩、最高分、平均分等)就是策略,依据目标任务实际特征,选择了班主任认为合理的策略(参评分数);参评分数具体的计算方法就是算法。
故事讲完,小白同学输得心服口服。
二、机器学习算法原理和评价指标
刚通过粗糙的小故事带大家初步认识了机器学习。那么接下来就讲一下机器学习的常用算法?
机器学习常用算法:线性回归、逻辑回归、支持向量机、决策树、随机森林等。因本文预期读者都跟小白同学一样,只是初识机器学习,所以本文先通过线性回归和逻辑回归带大家走近算法。
1. 线性回归
还记得模型是什么吗?第一章强调过三次(概率分布或决策函数)。线性回归模型就是由多个(无限)决策函数组成的。
“f(x)=ax+b”,看到这个熟悉吧,但凡上过中专的同学都不好意思承认说不认识,最简单的线性回归模型就是这样。
线性回归的目的:预测。通过学习大量的历史数据,发现一条尽可能多的涵盖旧数据的直线,当以后有新的特征(x)产生时,就能预测目标值(f(x))。
看图知意,品一品下面这幅图,结合上边小白班级选择数学王子的故事去品(没上过职高的同学可以先别看损失函数)。
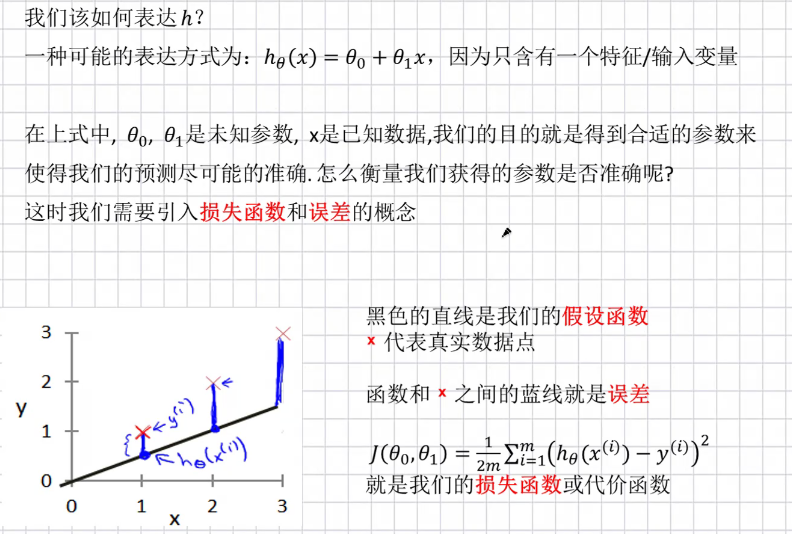
(看图识意2.0)
损失函数或代价函数,就是我们之前将的策略。怎么判定那条直线是拟合效果最优的,就可以通过损失函数来判断,损失函数越小就说明该直线(预测函数)拟合度越高。
上图只是在二维空间展示,只有一个特征(X),属于一元线性回归,当有多个特征(X1,X2,X3…)时,空间就是多维的,叫多元线性回归。
当一条直线能很好的拟合历史数据时,会出现变相的函数,比如指数函数(y=a^x)、幂函数(y=x^a)、多项式(如:y=ax^2 + bx + c)等。
2. 逻辑回归
逻辑回归虽然叫回归,但是在解决分类问题,通过找到一条曲线(其实是概率)可以将两种类别的数据划分开(二分类),可以参照《机器学习有哪些分类》中(看图识意1.0)。
逻辑回归的假设函数:结果是[ 0 , 1 ]的概率数字,表示:样本是1类的概率。
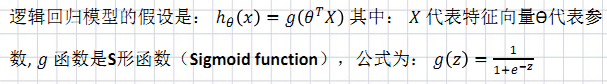
(不用理解,就知道这是一条曲线,可以将样本划分成两类即可)
想通过这种方式了解更多算法的同学们可以下期见。
3. 回归模型的评价指标
- 均方差(Mean Squared Error,MSE): 该指标通过计算预测值与实际值之间的偏差平方和的均值,反映了模型对数据的拟合程度,越小越好。
- 均方根误差(Root Mean Square Error,RMSE):该指标将 MSE 的结果开根号,以便于和原始数据的单位保持一致,反映了模型对数据的拟合程度,越小越好.
- 平均绝对偏差(Mean Absolute Deviation,MAE) : 该指标衡量的是预测值与实际值之间的平均偏差的绝对值,反映了模型对数据的拟合程度,越小越好。
- R方(Coefficient of determination):该指标衡量的是预测值和实际值之间的相关程度,取值范围为 0-1,越接近 1 越好。

(珍藏手抄版)
4. 分类模型的评价指标
不同评价指标,不同的适用场景,本期先让大家消化一下,各指标都是如何计算的,代表的什么意思。下期通过实例分享各指标的适用场景。所有指标并非人工计算,sklearn库自带计算公式,模型训练结束后直接调用对应指标就可以输出各指标值是多少。
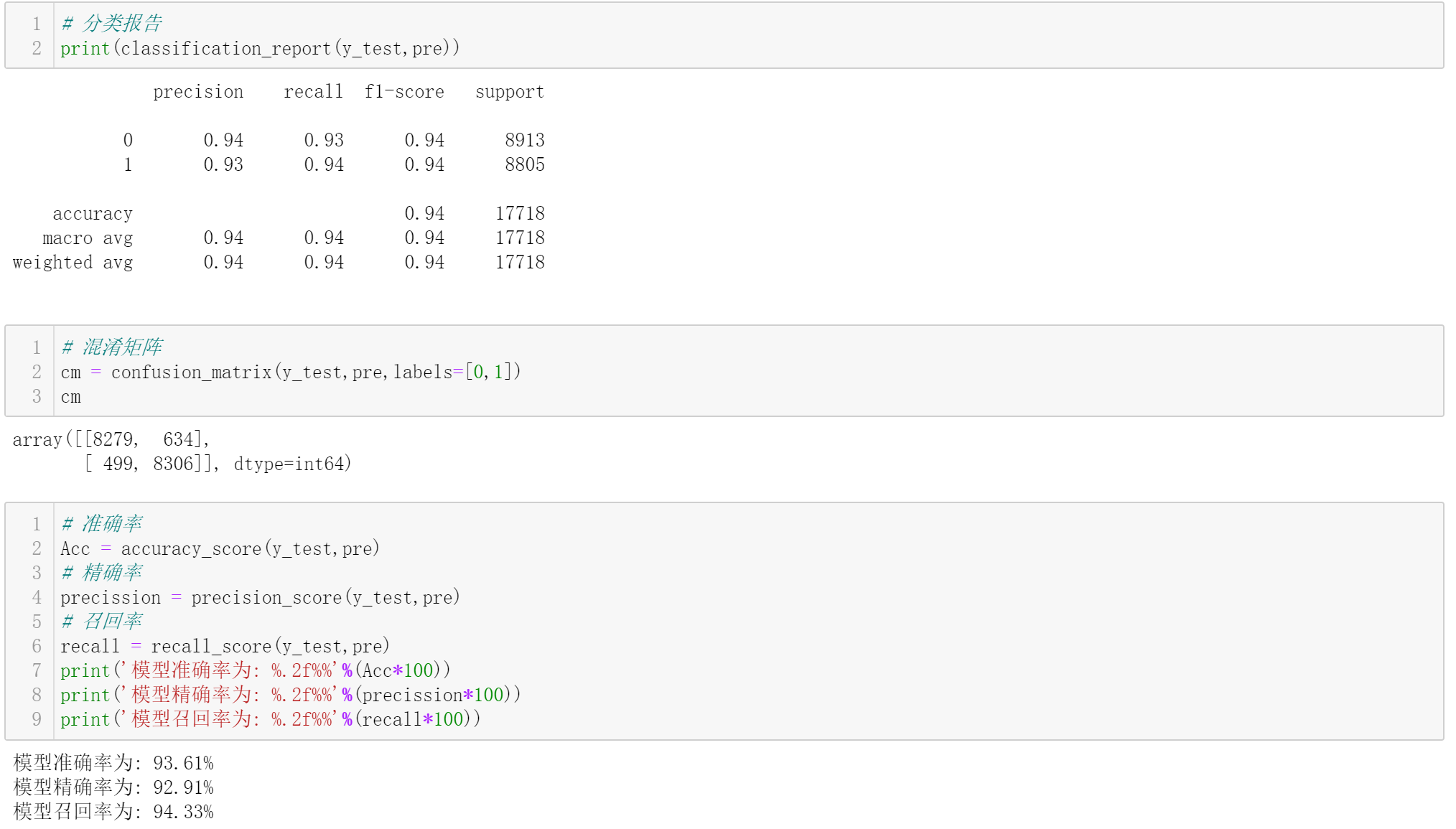
1)Accuracy(准确率)

2)Precission(精确率)/Recall(召回率)
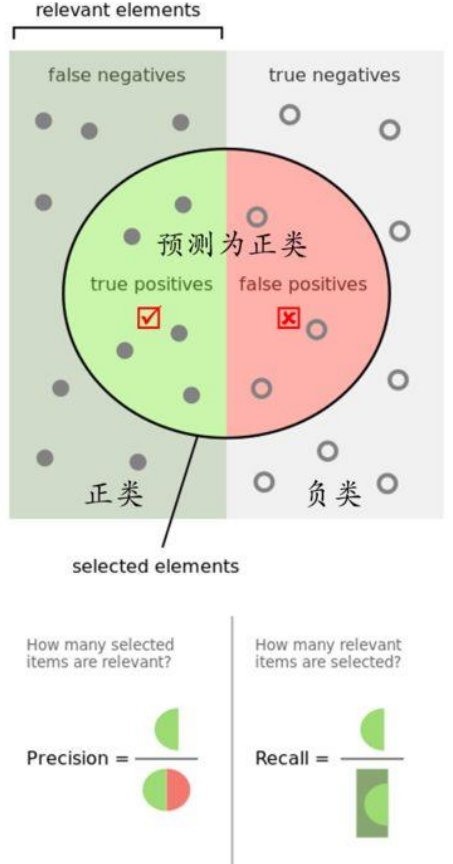
3)混淆矩阵
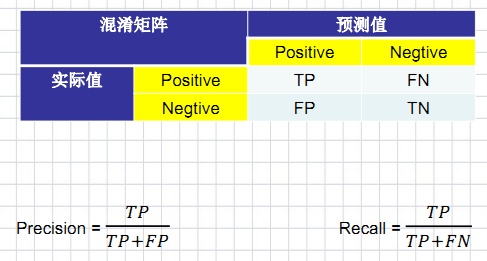
4)F1(调和均值)

5)Fβ

6)AUC(Area Under Curve)
为ROC曲线下与坐标轴围成的面积(不会大于1),衡量二分类模型优劣的一种评价指标,表示预测的正例排在负例前面的概率。
AUC反映模型对正负样本排序能力的强弱,对score的大小和精度没有要求.AUC越高,排序能力越强. 模型把所有正样本都排在负样本之前,AUC为1。

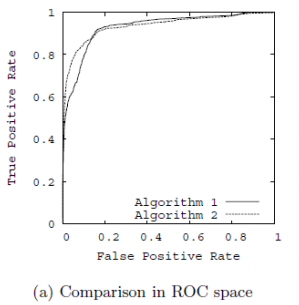
7)ROC曲线
全称为受试者工作特征曲线 (receiver operating characteristic curve),它是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(特异度)为横坐标绘制的曲线。

二、分类案例实操——看注释就能读懂代码
业务目标:通过逻辑回归将实验数据进行二分类(0,1),标签为“activity”。
流程导读:①获取数据—>②数据基本处理—>③特征工程—>④模型训练—>⑤模型评估
导入机器学习需要的各种工具库。因为我们要用到相关库中很多现成的能力,之前讲到的很多理论知识只是为了让同学们了解机器学习的底层原理,现实作业中,一行代码就能实现,哈哈哈,就是这么简单。

①读取文件数据
产品经理要对业务数据有一个初步了解,了解数据的特征之间的关系,数据特征与标签之间的关系。同开发同学讲清楚数据这些关系,才能帮助开发的同学构建更合理的特征。
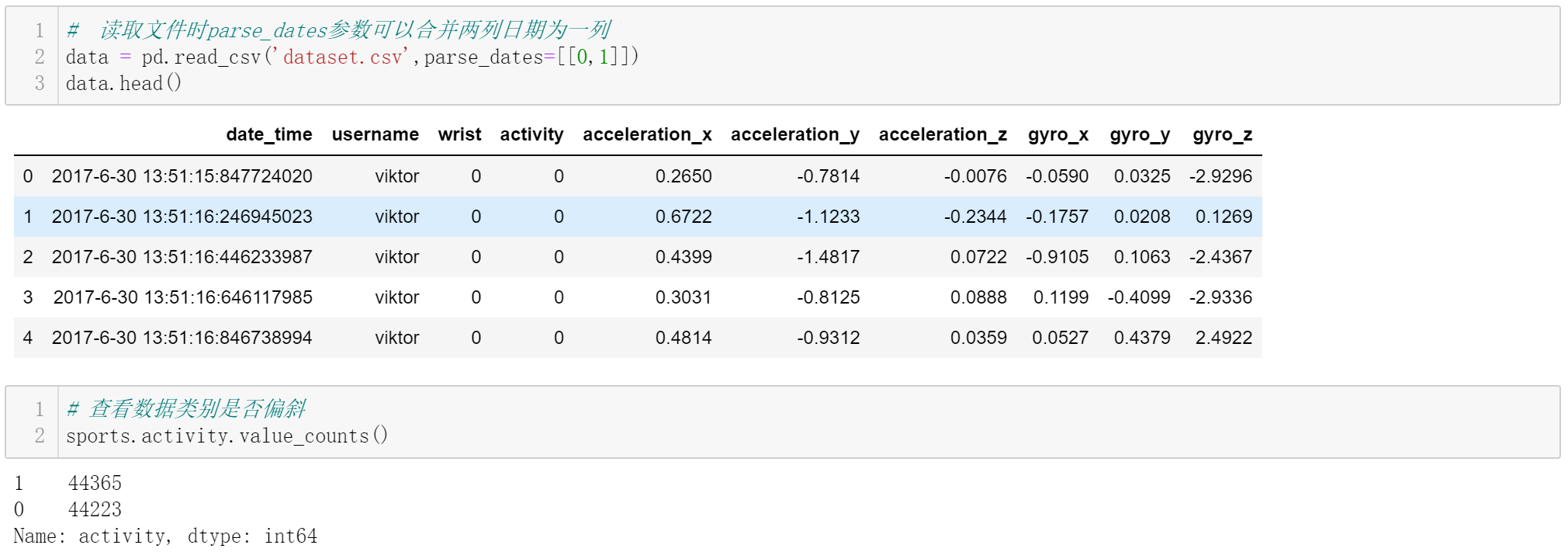
②数据基本处理
更多的是数据清洗工作,比如数据审核(数据特征是否均衡,不均衡的数据集,影响模型可信度和评价指标的选择)、空值异常值的处理等。因为本数据集是经过清洗后的数据集,比较完整,没有体现清洗这一步。下图可以看出来,数据类别比较均衡。
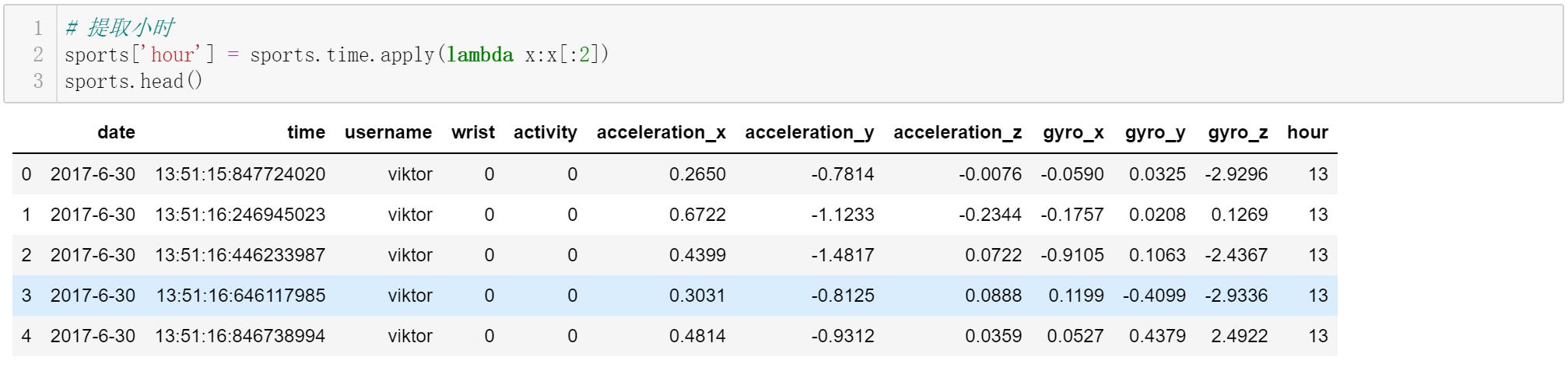
③特征工程
特征就是函数中的X。开发的同学可以通过相关性分析等方法,不断构建合理的特征,产品的同学也可以依据对业务经验,帮助开发同学快速构建特征。特征不是越多越好,而是约精炼约好。特征越精炼,模型性能(收敛速度,评价指标表现)越好。下图,构建了两个特征:hour和week。
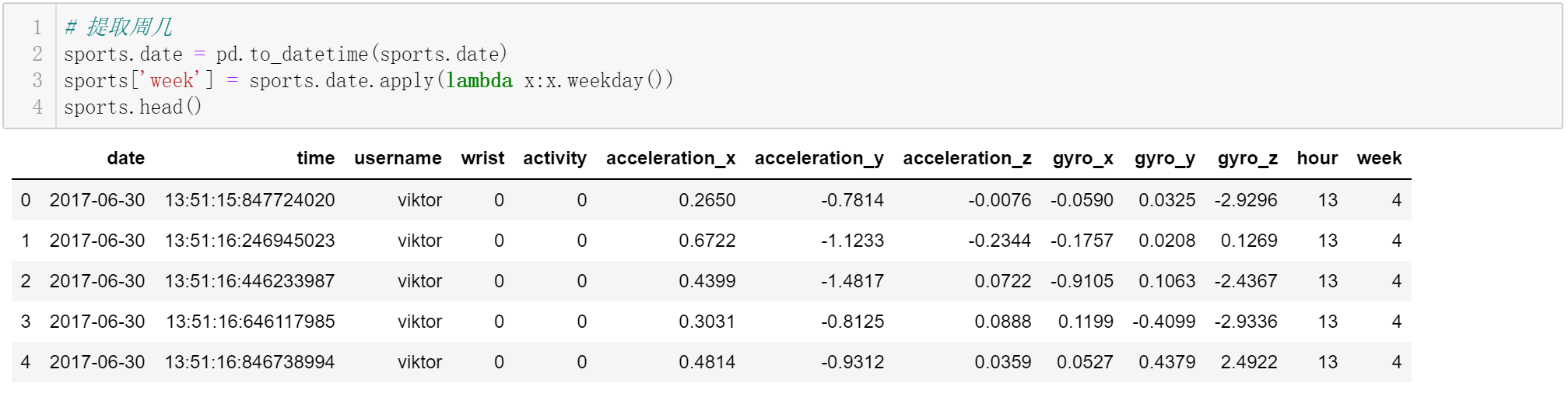
④模型训练
产品经理无需关注具体函数的实现细节,只需要了解实现步骤即可(红色字体)。

⑤模型评估
模型评估就是用适合业务场景的指标来评判模型的性能。代码介绍开始部分,调用的sklearn库,包含各种机器学习的评级指标算法,直接调用即可。
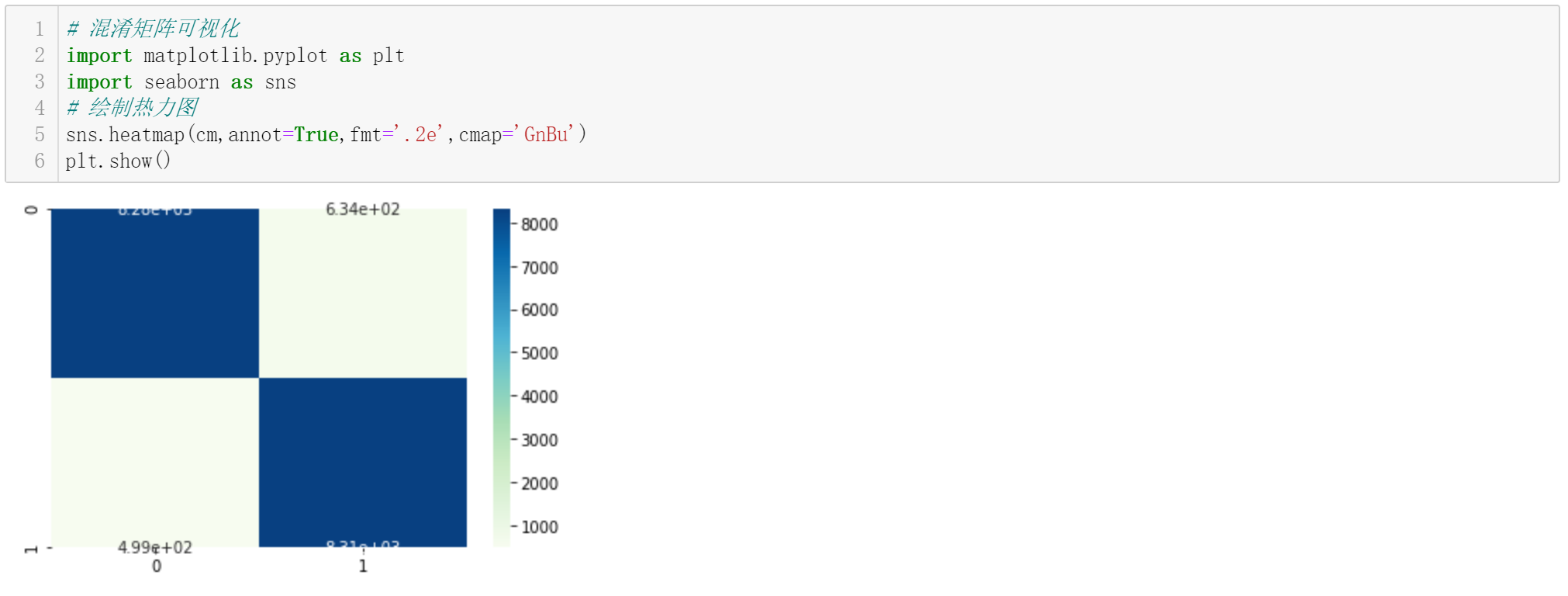
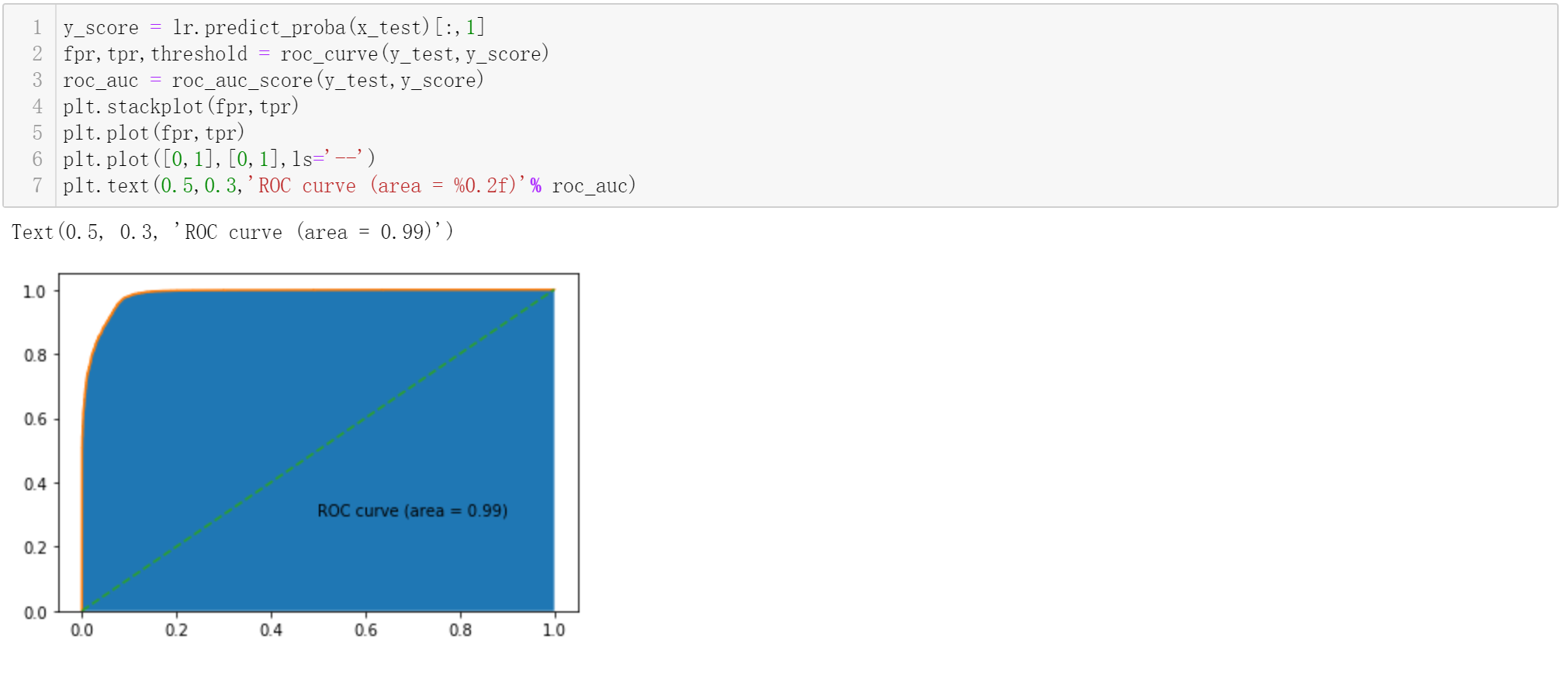
参考文献:
算法图解.[美]巴尔加瓦,[译]袁国忠,人民邮电出版社,2017-03
机器学习:Python实践.魏贞原,电子工业出版社,2018-01
Jared Dean. 大数据挖掘与机器学习[M]. 林清怡,译. 北京:人民邮电出版社,2016.
数据思维:从数据分析到商业价值.王汉生,中国人民大学出版社,2017-09
本文作者 @天儿 tiān er
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
