浅谈审核召回策略优化思路
引言:什么是审核召回策略
“召回策略”(match)是指从全量信息集合中触发尽可能多的正确结果。当我们聚焦于新闻内容类APP或资讯型产品,在内容理解、内容标签和审核相关的业务中,召回策略指的是通过算法模型、规则策略等识别不同的内容类型,并应用直接机审判黑或人机结合等方式赋予内容特定的标记,使其可以在下游内容入池、推荐分发等环节应用。
召回策略的评估主要根据两个评价指标:召回率和准确率。以内容质量审核为例:
- 召回率(Recall)=策略正确识别到的低质内容/系统所有低质内容总数
- 准确率(Precision)=策略正确识别的低质内容/策略识别到的低质总数
本文以内容质量审核为例,主要讨论如何提升审核环节召回策略的召回率,即,我们怎样才能扩大标签识别的范围,尽可能全面、高效地为内容打上业务所需要的标记。
一、为什么要优化召回策略
在新闻类、内容类APP中,内容理解是内容生产加工流程中不可或缺的一环,只有给内容打上足够精细化的特征和标记,才能基于用户画像使用协同过滤等方式给用户更精准地推荐内容。全面高效的召回策略是下游推荐分发环节不可或缺的基础因素之一。
在内容质量审核相关的业务中,为了能更精准地为内容打标,通常会采用人机结合的方式,即用召回率较高的模型尽可能多召回疑似质量有问题的内容,再由人工审核进行判断。
召回策略的有效性和线上低质内容的占比强相关,如果召回策略不够有效,那么就无法对新闻内容的质量和调性进行识别、判断和控制,也就无法达成相关业务指标,例如降低线上低质内容占比,或针对部分人群实行低质内容隔离策略等。
另外,受制于项目预算、人力成本等因素,在我们提升召回策略的召回率时,也不能忽视其准确率。如果一条召回策略能覆盖大部分低质内容,但召回量级过大(准确率很低),我们同样可以判断该策略的有效性(ROI)很低。
二、有哪些常见手段可以提升召回
方法一:从平台调性和标准入手
以某新闻类产品的质量审核业务为例,大致流程如图:
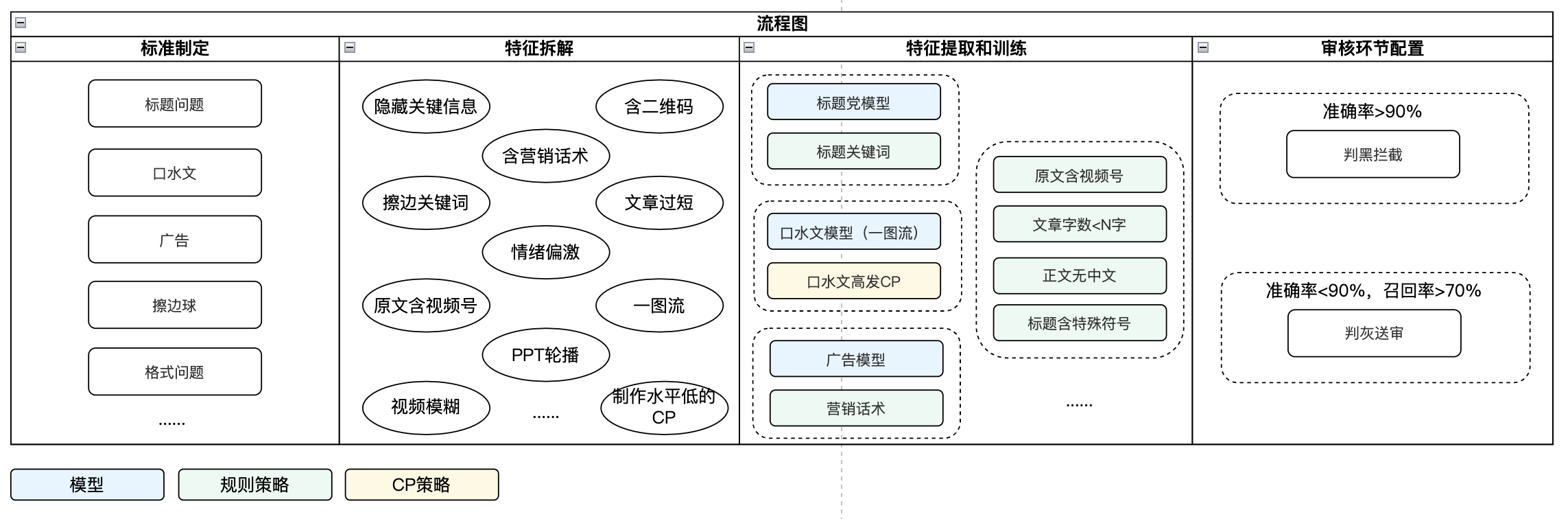
首先,业务方需基于产品定位和平台调性制定标准,准确全面定义“低质内容”的类型和含义,根据标准,进行特征拆解。例如广告类内容,通常含有营销类话术和关键词;格式异常类内容(因内容抓取和清洗导致内容缺失),可能存在文字段落丢失导致的文章过短等现象。拆解完特征后,需和算法等团队一同进行模型训练和规则定义,评估每个模型或策略的准确率、召回率和召回量级(for有效性评估)。
特征拆解关键点:
- 特征足够客观,避免程度等主观判断,使机器和人都好识别/执行;
- 特征足够细化,在应用环节可组合使用。
特征提取和训练关键点:
- 为保证尽可能多覆盖badcase,优先训练高召回识别能力,通过人机结合方式解决;再逐步迭代高准确识别能力,提升机审率;
- 应用环节结合实际业务情况配置豁免逻辑,规则和特征上不进行豁免。
方法二:从用户体感和用户行为倒推
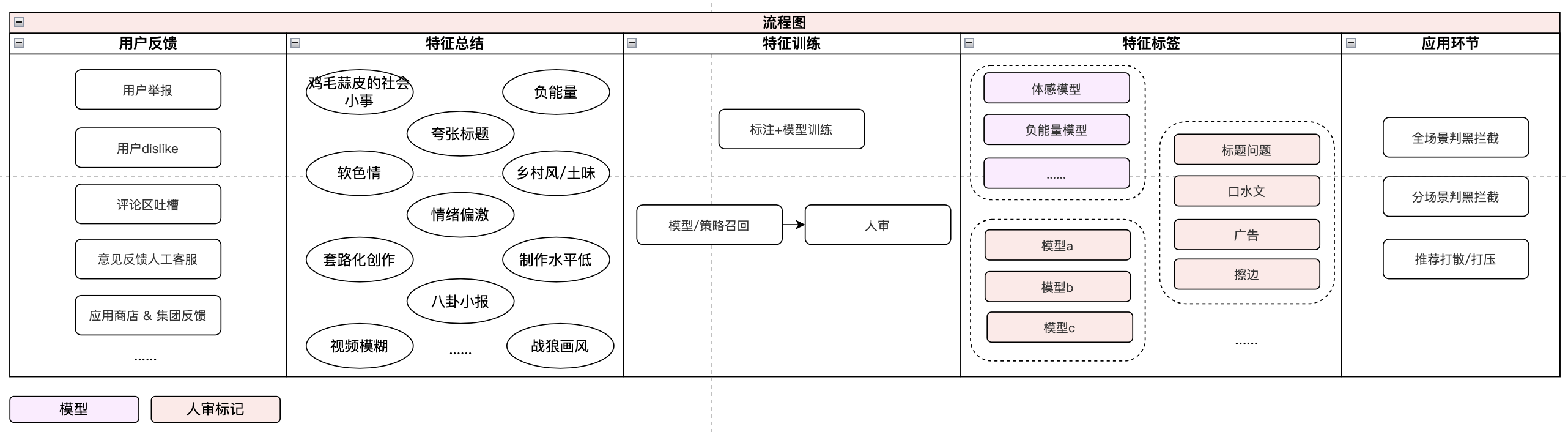
第二种方式从用户反馈出发,运营提炼出用户反感内容的特点,总结为客观特征,由算法进行识别能力建设,最终形成可用于业务的算法模型和规则。
特征提取和训练关键点:
- 从用户行为(隐性用户反馈)和用户意见反馈(显性用户反馈)中分析badcase,模拟用户感受,提取特征;
- 通过模型、人机结合方式识别特征。
三、有哪些常见手段可以验证召回策略的有效性
方法一:单个策略上线前验证,组合策略上线后整体评估
针对算法模型,上线前需评估三项指标:
- (正例)准确率;
- (正例)召回率;
- 覆盖率&召回量级。
评估要点:
- 测试集语料正例浓度需与线上基本一致,评估结论才相对置信;例如模型或策略是针对全量数据,那么测试集就需从全量数据中随机抽取;如模型或策略是针对单个场景的可分发内容池,则需从该内容池中随机抽取;
- 模型在不同浓度的测试集上效果会存在差异,如在不同场景应用同一个模型,需抽取不同场景可分发数据分别评估准召。
方法二:线上巡查
以内容质量审核为例,为了check召回策略的效果,可从线上可分发数据中随机抽样/巡检,评估线上可分发数据中是否存在质量审核环节的低质漏放数据,制定漏放率指标。
方法三:从下游审核环节回查
在各类新闻内容类产品业务中,可能会设置多个质量审核环节,例如针对部分场景设置复审,以便单独为该场景内容打上特征标记,服务于该场景的推荐策略。如存在多个审核环节,则可将整条内容加工链路看作一个漏斗,从下游环节回查上游是否存在漏放情况等。
四、召回策略的局限性和天花板
无论把标准规则定义得多么细颗粒度,把模型和规则调试得多么精准,我们不可否认的是,召回策略一定存在局限性和天花板,在实际业务中基本不可能制定出100%召回率的策略,即无法实现对标签内容的全量识别,主要原因如下:
- 在新闻内容类产品中,受热点事件影响,内容池内容结构可能存在变化(e.g.热点事件影响造成时政类发文增多),模型和策略的效果、召回率大概率会存在变化波动。实际的分发内容和评估召回策略有效性的测试集之间一定存在Gap,不可能时刻保持100%一致,这也就决定了策略上线时的指标一定会随着业务变化而波动,准确率、召回率、有效性都可能发生变化;
- 模型和策略本身可能会随着时间推移和缺乏维护而效果变差,例如有监督学习的模型,在上线后若不持续维护,则会因训练语料过旧产生效果“漂移”,在新的数据集上无法保持优异表现。
在实际业务中,召回策略若能保持90%+的召回率,已实属不易。其余不到10%的内容,通常只能通过引入巡检、单点反馈等人工运营的渠道来覆盖和解决。
本文作者 @芝士球 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
