浅谈AI Agent在B端的设计思路
随着AI的快速发展,各种先进的大型模型、产品和工具层出不穷。作为一名B端产品经理,我们需要积极拥抱这种变革的AI技术,将其应用于我们自身的业务,以确保企业的效能不会落后于行业的发展。
一般来说,如果企业没有自主研发大型模型,就需要依赖第三方的大型模型能力来开发AI能力,从而构建适用于企业自身的AI产品或工具。
如下图所示,常见的大型模型方向包括自然语言处理(NLP)、多模态(multimodal)和语音识别。大型模型厂商基于特定方向的能力进行AI训练,从而使得AI能够在某些领域上替代人类进行“可重复的”和“可标准化的”任务。
图片引用于开放隐私计算的《百模大战!AI大模型你更看好哪一家?》
为了确定我们业务所需的AI能力,我们需要对相应的AI模型进行调研,并评估大型模型的输出能力。我们可以从召回率、准确率、安全性、可解释性、稳定性、成本和发展潜力等多个维度对大型模型进行评估,以最终选择适合我们需求的大型模型。关于这一主题,我在之前的文章中有详细介绍如何选择适合自己的大型模型。
然而,当前的AI技术仍处于第二代系统阶段,尚未达到AGI水平。目前可接入的大型模型仍存在一些问题,主要包括以下几个方面:
1. AI幻觉:
AI幻觉是指AI在知识记忆、理解能力、训练方式和模型技术等方面存在的局限性,导致其在输出结果时表现不准确或不可靠。常见的问题包括数据偏见和解释性差。
由于AI幻觉的存在,即使我们期望AI能够稳定输出可靠的解决方案,仍然会有一定比例的错误答案产生。例如,如果AI在某个领域的准确率为50%,那么在50个答案中会有25个错误答案。对于需要高精确度的业务来说,AI无法直接应用。
2. 答案合规问题
AI是基于统计学的结果预测,本质上缺乏明确的是非判断能力。因此,在涉及道德、法律等方面的问题上,AI无法进行准确的判断或甄别,容易给企业带来负面影响。
3. 不够原生:
目前,AI的交互方式主要是通过输入-输出的方式进行,用户输入内容,AI输出结果。然而,这种流程并不符合所有业务人员的使用习惯。
以翻译场景为例,翻译人员的业务流程通常包括以下几个步骤:
- 确定翻译需求:确认翻译的源语种、目标语种、翻译风格以及不同地区的文化差异和调整方案等内容。
- 批量执行翻译:翻译任务通常涉及多条内容,翻译人员需要在同一时间内批量完成处理。
- 校对:翻译完成后,需要由校对人员进行校对,判断是否符合业务需求。
- 修改:如果翻译结果不符合需求,则需要进行修改。修改完成后,继续进行翻译、校对和修改的流程,直到修改通过。
- 交付:将通过校对的内容应用到业务中。
然而,如果要使用AI进行翻译,以节省人力成本,直接使用大型语言模型的对话输入交互方式会带来以下问题:
1)打断原有工作流程,难以形成使用习惯:
使用大型语言模型的对话窗口会打断原有翻译工作的业务流程。原本只需要在翻译工具或文档上完成工作,加入大型模型对话后,每个翻译文本都需要在输入框上进行输入交互。
2)操作成本增加的上限问题:
大型语言模型存在对话长度的限制,如果翻译内容量很大,就需要分批次进行交互,这会增加人力成本。
3)满足特殊翻译需求的操作成本增加:
如果存在特定的翻译需求,比如术语翻译或指定翻译风格,每次都需要进行交互,这进一步占用人力。
以上问题导致AI无法有效提高业务的翻译效率。由于操作繁琐,用户很难形成使用习惯,他们往往会下意识地认为直接自己翻译比使用AI更好,因此替换成本较高。
此外,AI翻译存在幻觉问题,无法提供超出预期的用户体验。
由此,【(新体验-旧体验)-替换成本】 并没有大于0 ,直接使用 AI 的原生的交互方式并不能有效地提高业务率,因此需要一些更 native 的方式。

一、什么是AI Agent
基于当前人工智能存在的挑战,我们需要思考如何在B端建设我们自己的应用。一种可行的方式是尝试构建专为业务定制的AI Agent。
所谓AI Agent,又称人工智能代理,是指能够理解、学习和执行任务的自动化程序。可以将其比喻为”将AI视为实习生,让其承担琐事,而我们则负责指导这位实习生,确保其产出符合预期的结果”。
与大型模型不同,AI Agent并非仅通过提示与人进行交互。它是基于特定工作目标,并输出符合需求结果的系统。AI Agent的核心是大型模型,同时在此基础上扩展了感知模块、计划模块和行动模块。
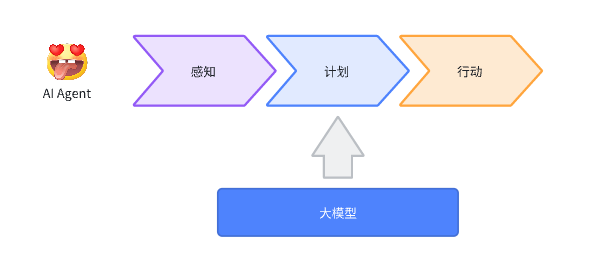
- 感知模块:感知模块通过与业务数据源和外部数据源的连接,将数据组装到提示词中以进行输入。
- 行动模块:行动模块可以通过与业务能力接口的连接,根据感知和规划的结果执行相应的业务操作。另外,还可以通过反馈系统将业务实践中的反馈数据与代码、策略和提示词进行优化。
- 规划模块:规划模块是AI Agent的核心。除了利用大型模型的能力外,还需要根据业务需求结合代码逻辑进行设计。在这里,我们需要构思大脑的运作方式,并采用适当的输入输出方式来推动业务。
二、如何设计AI Agent
那么怎么设计符合业务需求的 AI Agent ?
1. 找到合适的业务场景
首先,我们需要确定适合AI Agent 的场景,通过模拟数据输入和收集输出结果的方式来评估所选场景的适宜程度。在判断输出结果的同时,需要考察是否符合预期。若结果不符合预期,则需要评估误差的严重程度,以及准确率和召回率是否存在改进空间。若存在改进空间,可以通过优化提示词,或者通过引入感知、行动和规划模块的构建,使得AI符合我们的场景需求。
其次,我们可以将业务场景进行划分,让AI仅负责适宜的场景,作为业务的辅助与补充,即使无法完全覆盖整个业务,也能发挥作用。
2. 梳理输入和输出预期
我们需要明确对于AI Agent的’目标’和’要求’,以确定我们输入什么,Agent需要输出什么。
基于这些’目标’和’要求’,我们应该思考如何选择合适的输入输出方式来满足业务需求并为业务赋能。这将有助于我们设计后续的输出流程,并在设计验证阶段进行评估,以确定是否符合要求。
3. 梳理输出流程
当我们面临复杂的输出要求时,需要设计多个AI会话流程,以使各个AI之间相互协作,最终实现符合要求的输出结果。例如,在文本分类场景中,我们可以首先使用3.5版本的大模型进行准确的一级分类,以满足需求。
由于4.0版本的成本是3.5版本的几十倍,而3.5版本在一级分类上已经足够使用,因此可以选择使用3.5版本以节省成本。接着,我们可以使用4.0版本进行二级分类,以获得更好的分类效果,确保我们输出所需的内容。
在设计流程时,需要考虑以下几个因素:
- 成本因素:不同大模型及其版本的费用各不相同,我们需要权衡业务收益,选择一个合理的大模型使用方案,以避免得不偿失。
- 效果因素:不同大模型及其版本的效果各有差异,并且在不同领域有其擅长之处。我们需要结合使用需求,选择最适合的方案。
综合考虑成本和效果因素,最终确定一个合适的方案。
4. 输出检验机制
为了避免AI输出结果中存在误导性内容对业务产生影响,我们需要建立一套有效的验证机制。常见的验证方法包括词库匹配、正则表达式匹配和人工检验。通过使用词库或人工方式拦截具有误导性的内容。此外,我们还可以构建质检Agent,让AI自身对输出进行质检,以过滤出存在问题的内容,提高误导性内容的检测率。
5. 幻觉兜底方案
幻觉的产生是无法完全根除的现象。为了避免对业务造成不良影响,我们需要制定兜底方案,例如:
1)人工检验:在AI输出传递给用户之前,引入人工检验环节。只有在人工检验通过后,才将结果输出给用户。这样一来,我们能够完美地防止AI幻觉对业务产生负面影响,并且还能够利用AI的输出结果提升效率。然而,这种方法需要人力审核,因此会增加一定的人力成本。

2)合理包装:考虑到我们是面向B端的AI应用,我们可以采用包装输出应用为“AI助手”等方式,直接向用户明确表示:“这里的输出结果由AI生成,仅供参考”。通过这种方式,我们能够让用户形成合理的心理预期,避免在出现幻觉输出时产生不良反应。
三、总结
基于以上思路,我们便可以构建B端的翻译Agent、数据分类Agent、智能客服Agent等等业务了,当然这仅仅是我个人的一些思考,欢迎大家交流讨论。
为我投票
点击下方链接进入我的个人参选页面,点击红心即可为我投票。
投票传送门:https://996.pm/7d9yE
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
