Perplexity:用答案引擎挑战Google | 万字长文
从Yahoo到Google再到Perplexity
Perplexity创始人Aravind喊出了这样的口号!意味着他们开始公开叫板Google!成立一年的公司叫板市值全球第四的公司?脑子瓦特了?
在人工智能的浪潮中,每一次技术的跃进都预示着行业格局的重塑。今天,我们将深入探讨一个正在挑战搜索引擎霸主地位的新星——Perplexity。在这场技术与商业的双重博弈中,每一个细节都可能成为颠覆性的起点。
这篇文章,不仅仅是对Perplexity的剖析,更是对未来搜索形态的一次大胆预测:
如何用答案引擎“杀死”搜索引擎?
想象一下,当你的每一次搜索请求都能得到即时、准确、结构化的答案,而不再需要在海量信息中苦苦寻找。Perplexity,这个由AI驱动的答案引擎,正试图将这一梦想变为现实。它不仅仅是一个搜索工具,更是一场用户体验的革命。它的出现,让我们不得不重新思考信息获取的方式,以及在这个过程中,我们作为用户、开发者、甚至是整个社会的角色。
Take Away:
- Perplexity是答案引擎
- 在AI和搜索技术间寻找平衡
- 用户画像偏专业用户
- pplx是破局点
- Perplexity能否颠覆Google取决于新变量
感谢共创者:周慧明,做大模型&虚拟人应用
一、Perplexity有多牛?
在聊它是什么之前,先看看它哪里牛:
第一,持续的流量增长。
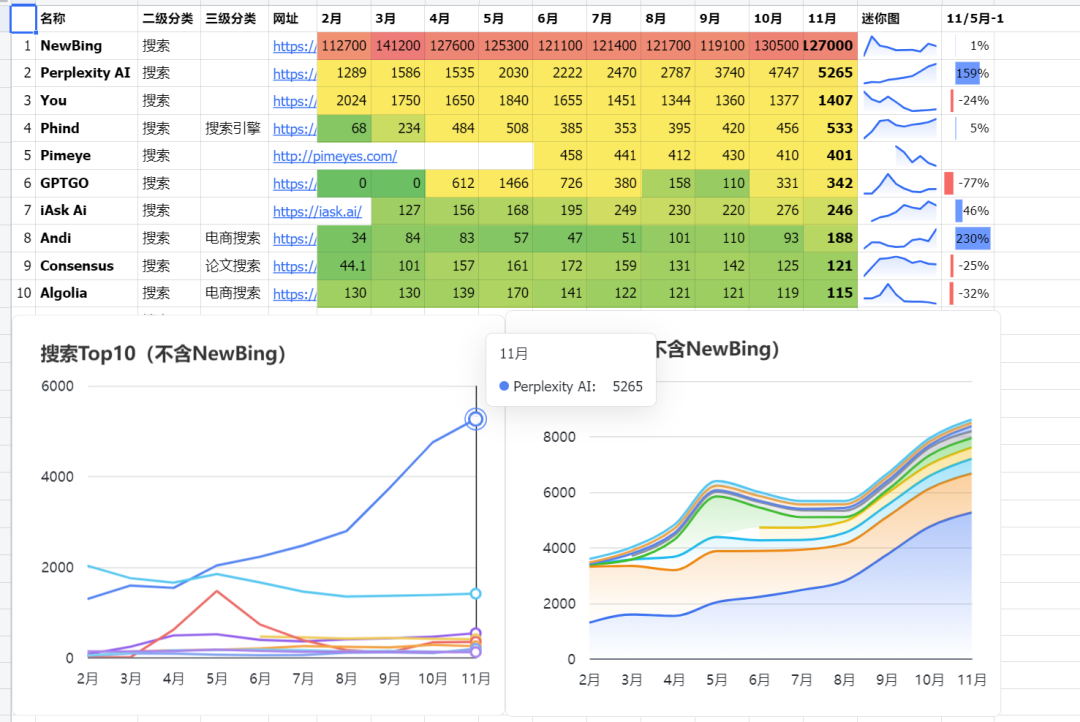
(单位:万PV,from 郎瀚威 Will整理)
第二,创始团队厉害。
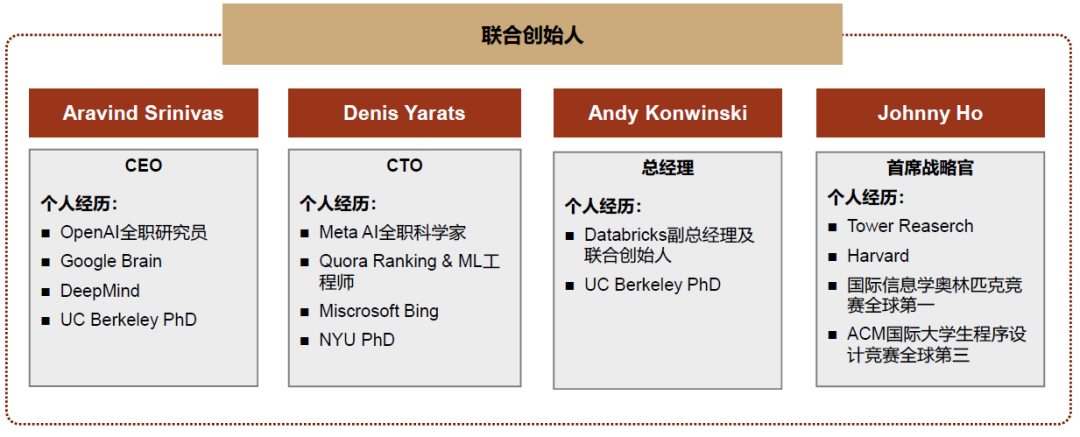
资料来源:中金公司研究部
团队成员经验丰富,对LLM及搜索引擎有深入见解:
Perplexity创始人为Aravind Srinivas、Denis Yarats、Andy Konwinski以及Johnny Ho四位。Srinivas曾于Google、DeepMind实习且曾就职于OpenAI。Yarats曾在微软Bing、问答网站Quora、Facebook担任人工智能研究人员或工程师。Konwinski为DataBricks的联合创始人。Johnny Ho曾在Quora担任工程师,研究排名与后端系统,引领系统快速迭代。
第三,强大的投资团队。
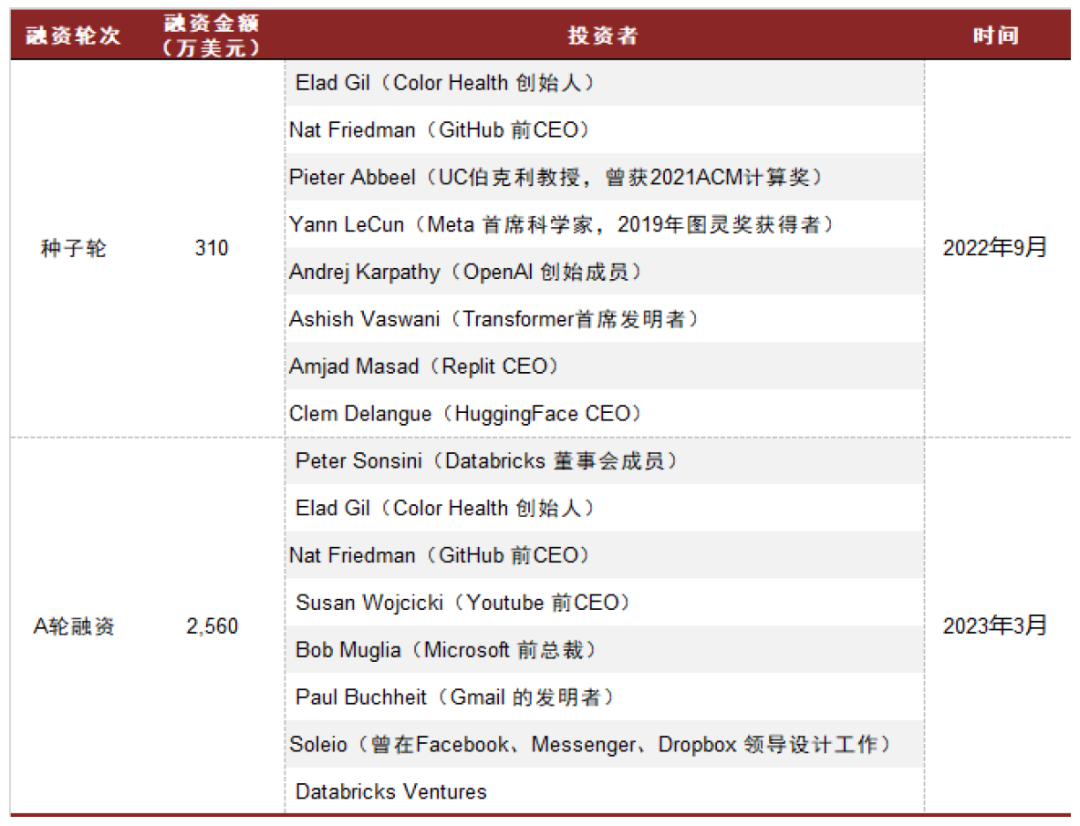
(from 中金点睛,遗漏了Jeff Dean,Google AI部门负责人)
包括后面我们会提及的优秀用户评价,种种迹象给我们一种感觉,这个产品好牛呀!那它到底是什么呢?接着往下看:
二、Perplexity是什么?
1. Perplexity是一个答案引擎
Where knowledge begins
简洁的Perplexity首页,摆着这三个单词,一切仿佛和Google搜索没有特别大的区别,在提问框输入我们的问题并回车后,不一样的地方开始显露:
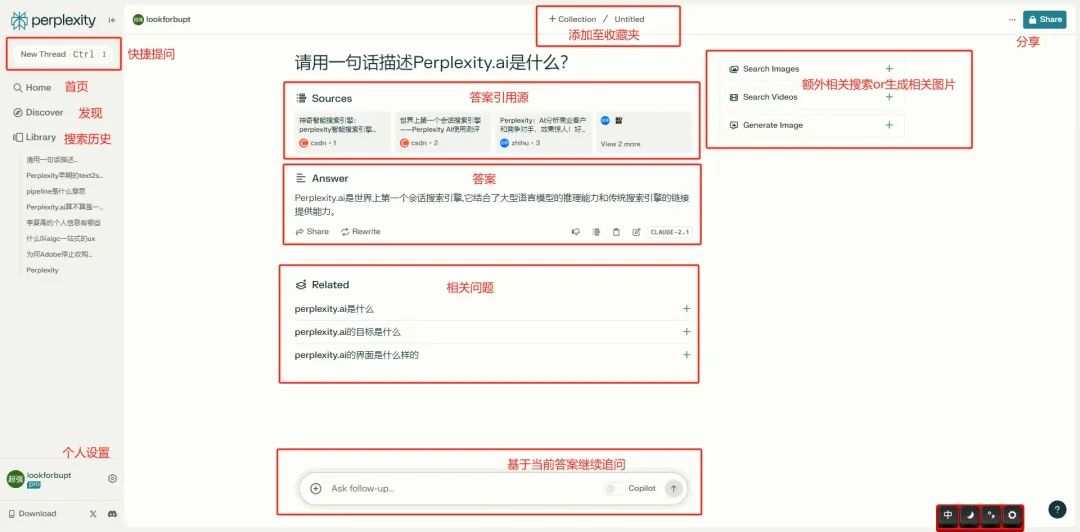
我们来看主线,也就是上图中间一列内容,包含了:
- Sources,引用来源
- Answer,答案
- Related,相关问题
- 提问框
对于我们用自然语言提出的问题,Perplexity使用Generative UI(基于用户的Query生成的结构化答案组织界面)来呈现答案:
- 首先在Sources处会明确告诉我们,答案的来源是基于这些链接里的内容整合而来,支持点击。
- 其次答案会给出结构化的明确结果,文字里会包含引用源
- 接着,Perplexity预留了你可能会追问的几个问题,点击后,会在当前页面继续向下展开对于问题的答案
- 最后,也可以继续用文字的方式提交你的问题
我们换一个问题来感受一下:
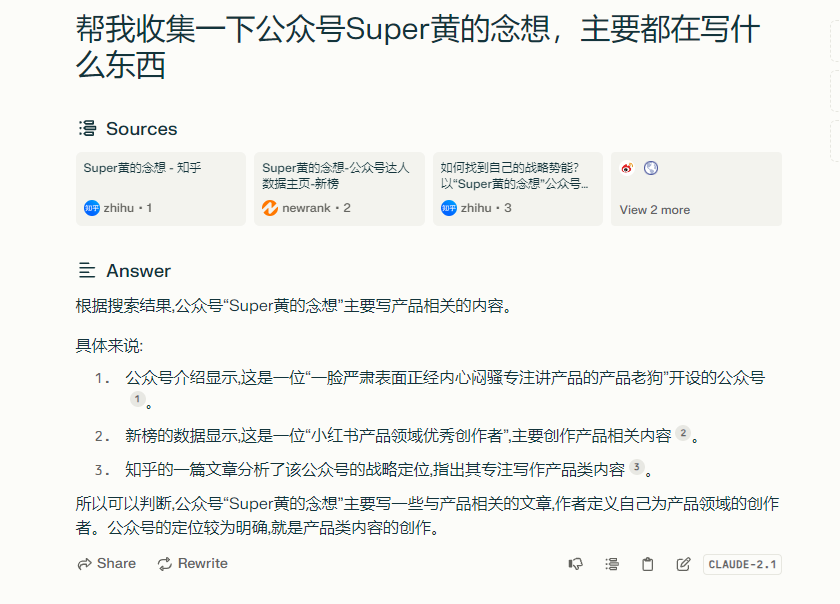
Perplexity是一个答案引擎。用户可以使用自然语言描述比较复杂的问题,Perplexity会基于理解问题的情况下,通过搜索并整合内容,明确给出一个答案,并且支持溯源,以及继续追问。
这对于用户是非常友好的,我们仔细琢磨一下,之前使用搜索,以及现在使用Perplexity的差异:
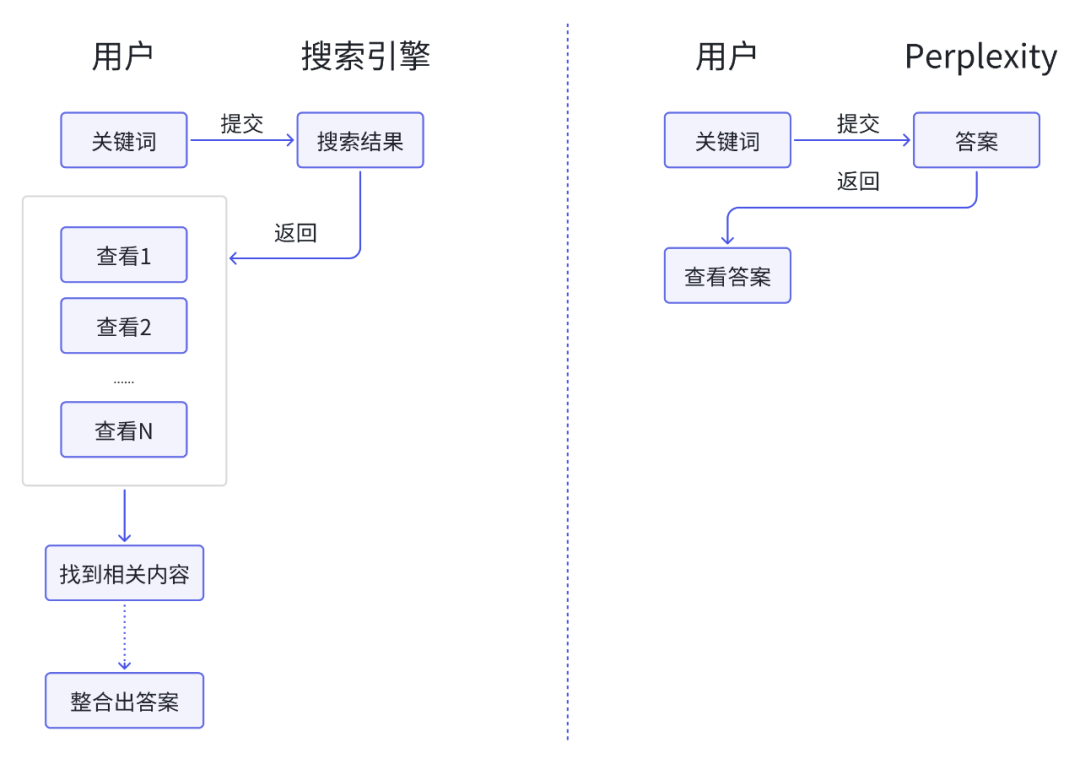
可以发现,Perplexity在大多数情况下帮助用户省去了两个关键步骤:
- 逐个链接查看
- 对多个网页内的内容进行整合
过去我写文章需要查询大量网页内容时,是需要打开很多网页,并且网页多了后,经常找不到哪个内容具体在哪个网页内,又得逐个网页打开,这个过程就非常的繁琐。
对比下来,Perplexity现在就非常简洁了!(当然对应的,我们也可以感受到Perplexity的一些约束条件,后面会进一步展开说它的缺陷)
2. 更多的功能
上面写的都是主体功能,Perplexity还做了很多额外的功能,来提高用户体验,我们说几个有意思的。
Copilot:
interactive research assistant feature(交互式研究助手功能)
Copilot的意思是增加一些助手的工作,比如会自动的增加Query的近似词,来增加获得的搜索结果,再比如对于Query不明确的地方,自动弹出提问来要求用户补全,以便获得更好的搜索结果:
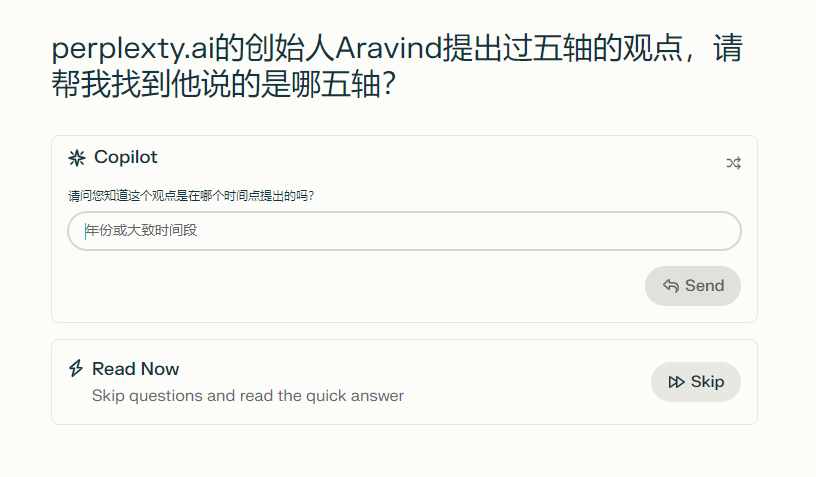
上面的输入框,就是Perplexity自动根据问题,希望我进一步描述Aravind具体何时提出过这一观点,这样能缩小搜索范围,进而提高搜索的结果准确度。
这一功能在2023年5月推出,并于8月份更新。一开始是用GPT-4来支持,后面优化成了微调过的GPT-3.5,能力差不多,但延迟减少了4-5倍,推理成本大幅下降。
Collections:
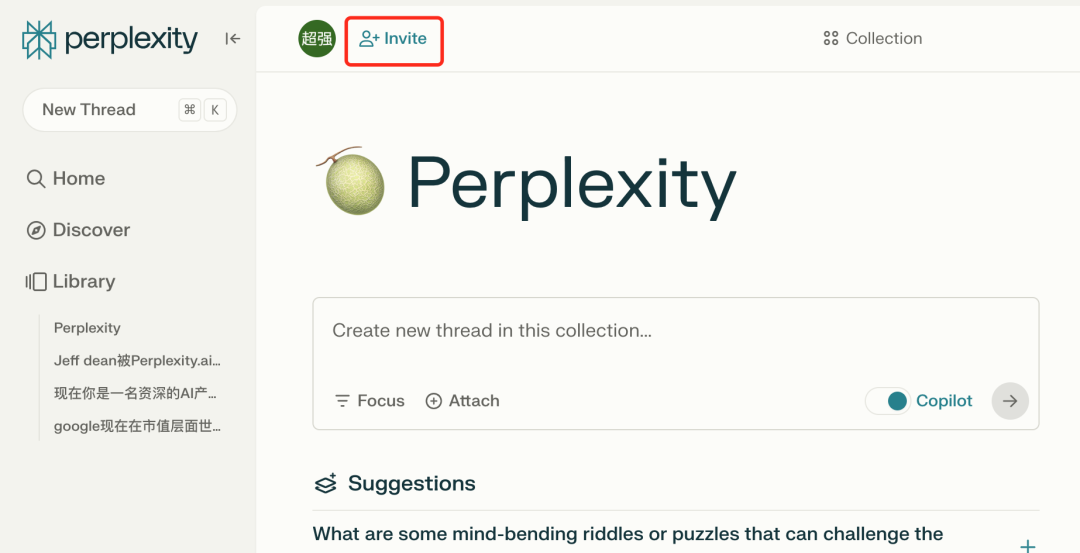
收藏夹,可以把搜索结果页的内容收藏进来,可以和其他人协作,可以公开也可以私密收藏,并且可以持续在这一收藏夹所属下面持续的搜索答案积淀下来。
它的前置功能是每一个搜索结果页都会被保存下来,也可以分享,其他用户只需要点击链接就可以完整的查看到先前Perplexity生成的答案页。
这一功能有点向个人知识库的方向做探索了。比如我可以邀请几个朋友,一起在Perplexity的Collection下面搜索,相互可以借鉴相关的答案。
Profile:
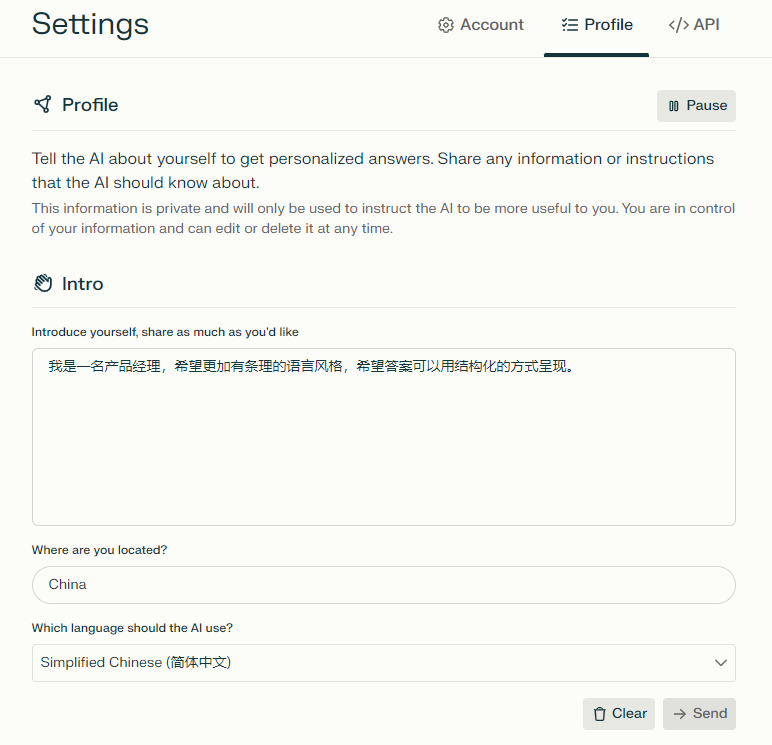
通过一些个性化的设定,让Perplexity在搜索的信息源、输出的语言、最后输出的答案偏好,更好的实现个性化!
Discover:
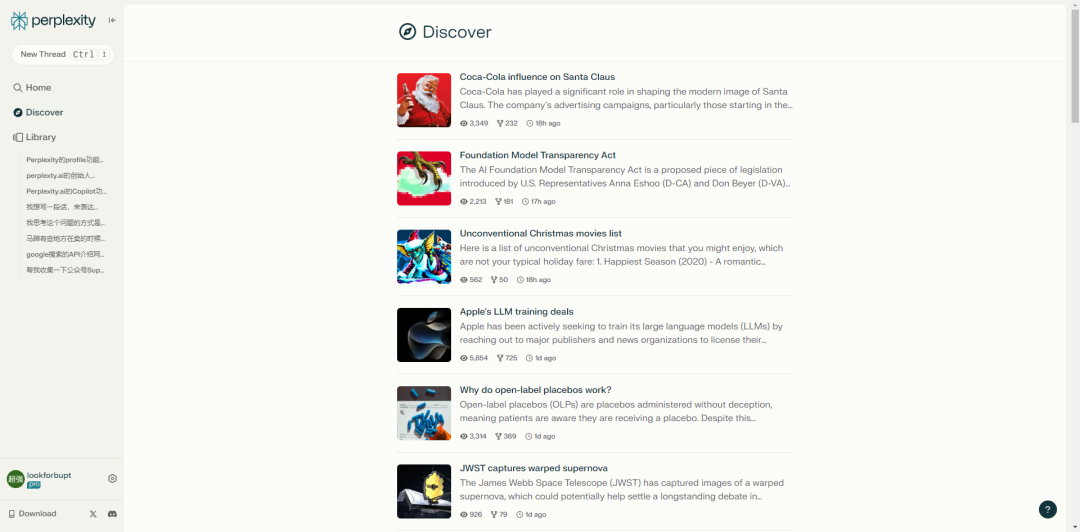
发现热门的一些搜索结果,有点简化版微博热榜的感觉。
3. Perplexity的工作机制是什么样的?
搜索 LLM的结合!但不单纯是搜索 LLM:
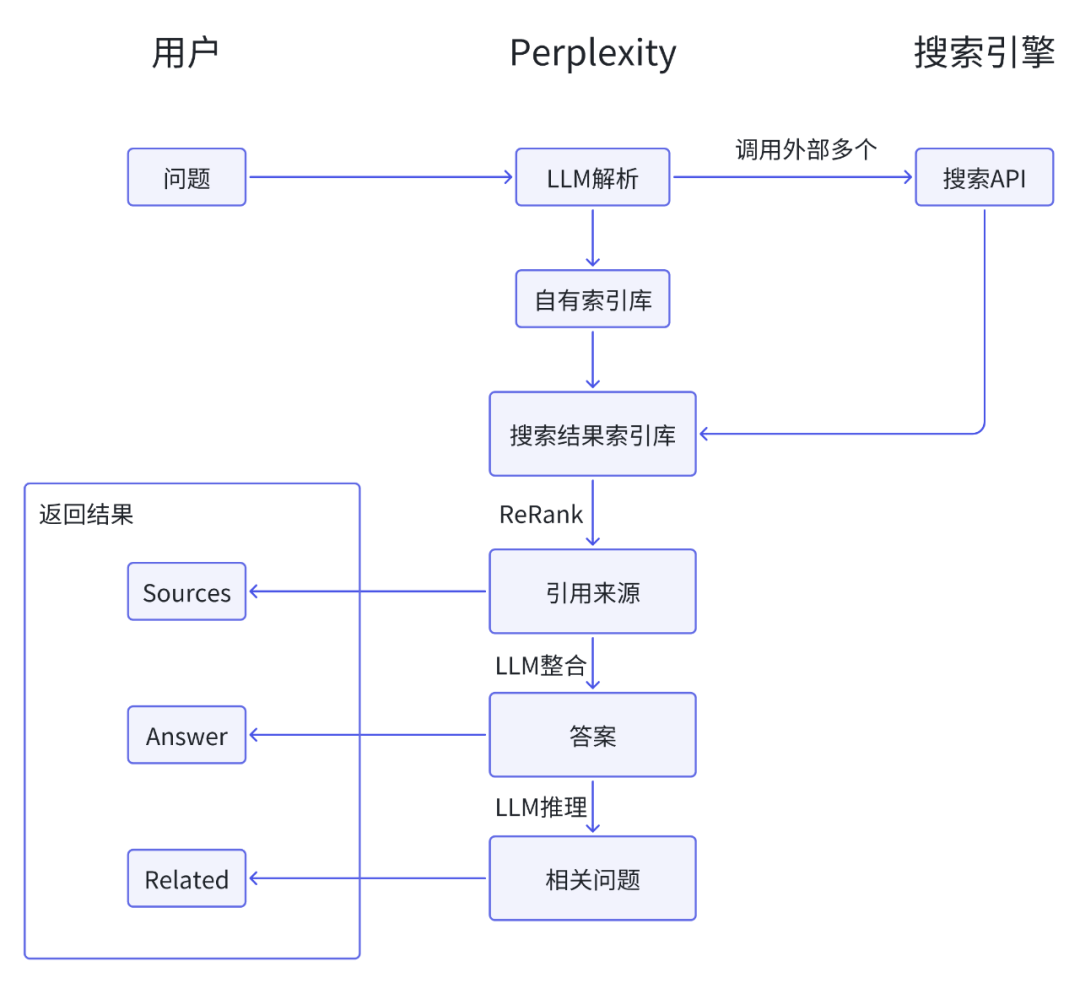
简单来说,Perplexity比搜索引擎额外多做了几件事:
第一,用LLM重新理解了用户提出的问题,然后解析为一个更清晰的搜索语句(Copilot增强了这一步)
第二,调用搜索引擎的API,比如Google、Bing的,当然现在Perplexity也创建了自己的索引库,来构建特定领域的索引库,保证搜索质量
第三,用自有的排序算法,对所有的搜索结果做重新排序,筛选出数量不等的质量不错的网页,这些网页就是Sources了
第四,用LLM来逐一阅读Sources里的内容,并输出和问题相关的答案(Answer),以及可能的相关问题(Related)
再抽象一点,就是三步:
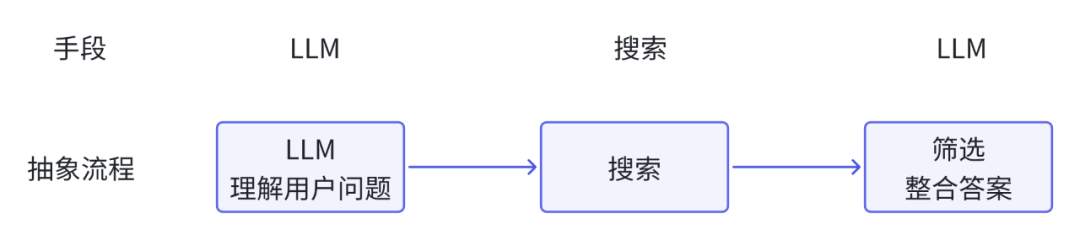
那看起来,这个产品也挺简单的呀,无非就是找个大模型,再调搜索接口,分分钟Copy一个出来,甚至说,我直接问ChatGPT不就完事了么?GPT4也有联网的功能,为啥非得用Perplexity呢?
话是这么说,但极致的追求,也让Perplexity在答案引擎上遥遥领先:
4. Perplexity和大模型有什么不一样?
确实,ChatGPT本身就能直接解答用户的提问,包括成为付费会员后,附带联网查询功能,以及NewBing 也是默认搜索加整合答案,那Perplexity为何能从中异军突起呢?
能做,和做得好,有很大的差别,以创始人Aravind的话来说就是要五轴都要做得好:
- 准确性;
- 可靠性;
- 低延迟、速度;
- 令人愉悦的用户体验;
- 产品越来越个性化,让你感觉想要不断回来。
Perplexity做了大量的工作,目前可见的至少有这三个核心要素:
准确性 可靠性:
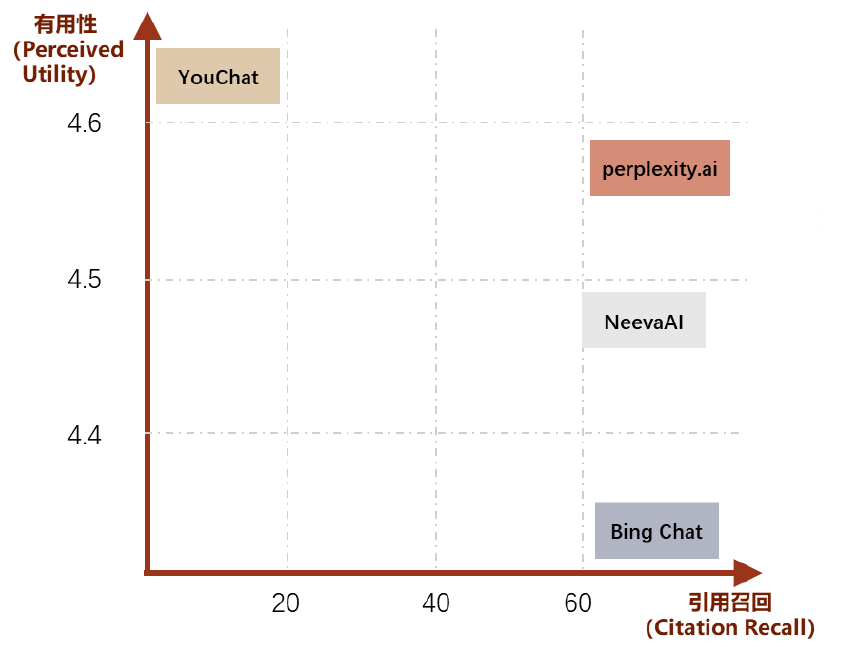
注:有用性(perceived utility):回复对用户查询来说是否是有用且有信息量的;2)引用召回(citation recall):指由其相关引文完全支持的、值得验证的句子的比例。中金公司研究部
从前文可以看到,Perplexity主要依赖引用的链接里的内容做整理,这样相当于大幅依赖RAG,极大的降低了LLM的幻觉问题。同时,Perplexity在召回和排序环节都对算法侧进行了创新,保证内容的有用性及引用的精确程度。
GPT4、Kimi Chat和百川这些都可联网,但你并不知道具体去哪里引用了内容,无法溯源,对于幻觉仍旧抱有疑虑。
NewBing只能在Edge上使用,尽管可以免费白嫖,但是速度确实很慢,也没有Copilot等,感觉在答案引擎这件事上,并没有做得更多的工作,产品形态和速度半年来没有什么改进。
速度:
今年10月4日,Perplexity推出了pplx-api,这个API是Perplexity自研的推理堆栈,使得Perplexity的生成速度快于GPT类通用模型。
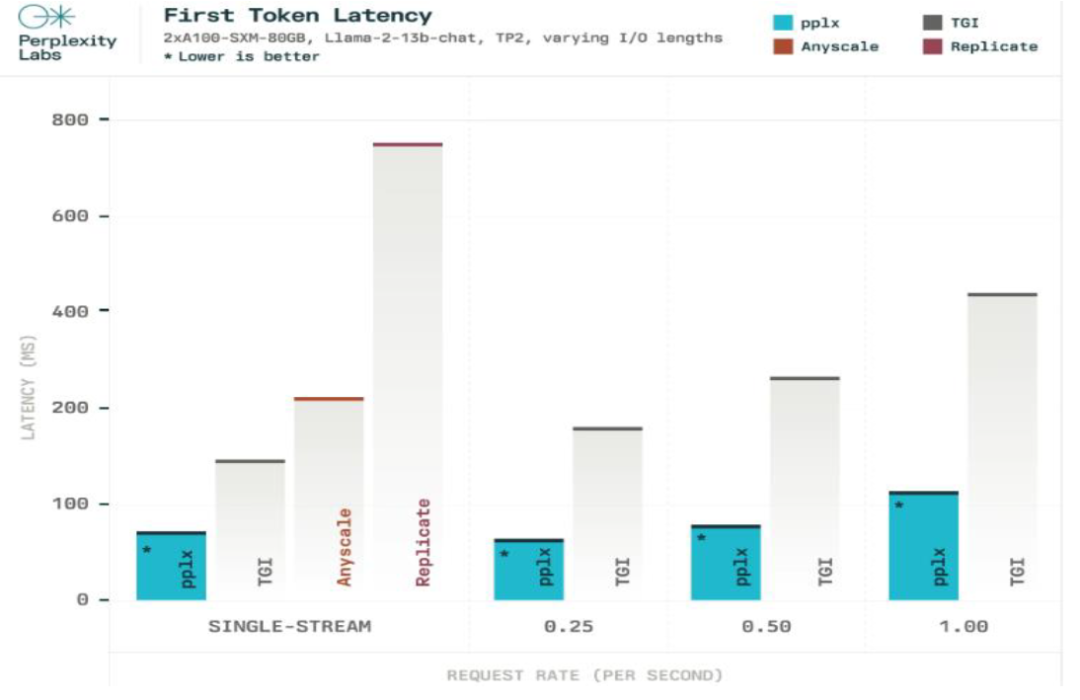
推理堆栈主要用在了最后对搜索结果的整合和推理部分。
也可以看到Perplexity一直在研究更好的架构和技术来提高整个产品的运转效率:

对于效率的追求,使得Perplexity的体验真的非常的快,几乎是答案秒出。
用户体验:
Super个人在使用中的体验是很丝滑的,写下问题 → 得到答 → 点击相关问题 → 继续快速获得答案 → 输入个性化的追问 → 进一步获得答案,并且所有的答案都在同一个页面内,可以快速的回看,不用来回切换页面。
这种迅捷体验远胜于 ChatGPT 和 NewBing。
再加上Copilot可以更好的实现交互,坦白讲和其他竞品在产品层面的体验差异还是有些遥遥领先的。
但罗马不是一日建成的,回看Perplexity的初始阶段,也能帮我们更好的理解它:
三、Perplexity的演变(重要)
Perplexity的ASK产品是在2022年12月7日上线的,但是公司的创立是2022年8月3日,是一开始就在筹备Perplexity Ask么?
我们这一节先来看一下Perplexity创办后的产品演变,下一节再去理解创始人。
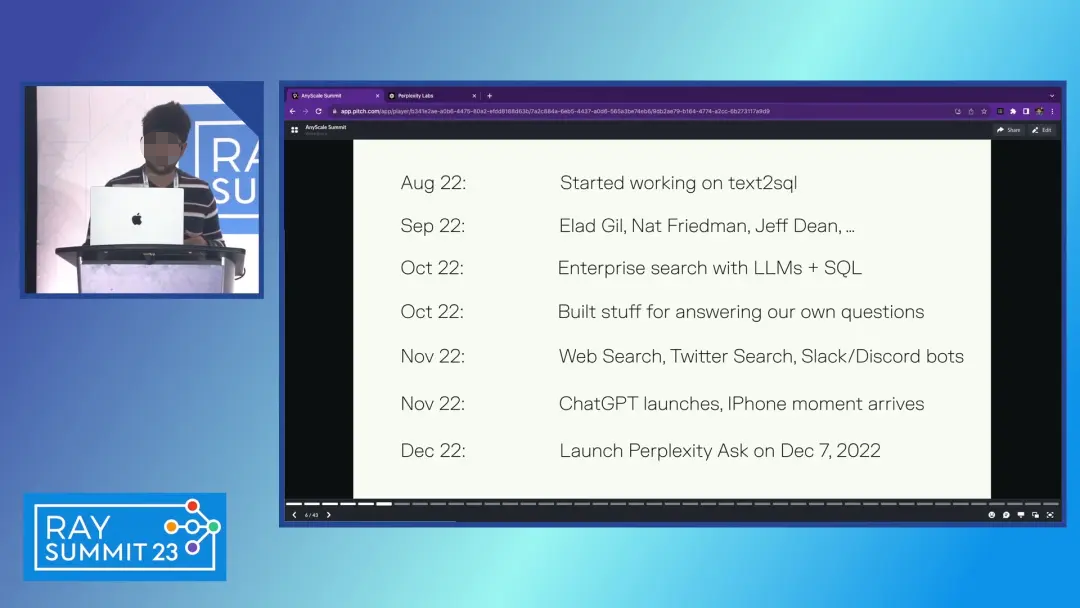
在一次分享上,Perplexity创始人Aravind放出了一张图,我们可以发现,最早做的产品是Text2SQL。
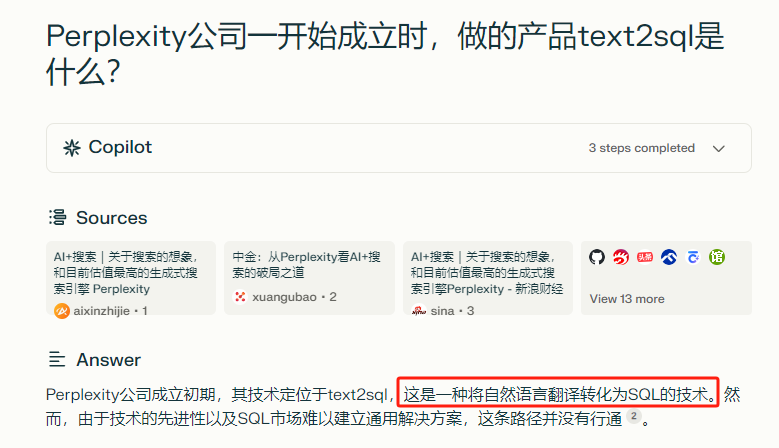
这个技术是针对企业市场的,美国有个很有意思的想象是,toB市场非常的好做,不光是容易获得ARR,而且创业公司做到一定程度后,也比较容易卖掉公司,或许因为这个,基于text2sql,Perplexity获得了Elad Gil, Nat Friedman, Jeff Dean的种子轮投资,这几位是谁呢?

在9月27日,为了方便内部,搭建了一个Slack机器人,作用是希望帮助团队get如何去撰写SQL模版,因为这个需求Google解决不了,问同事又非常的费时间。
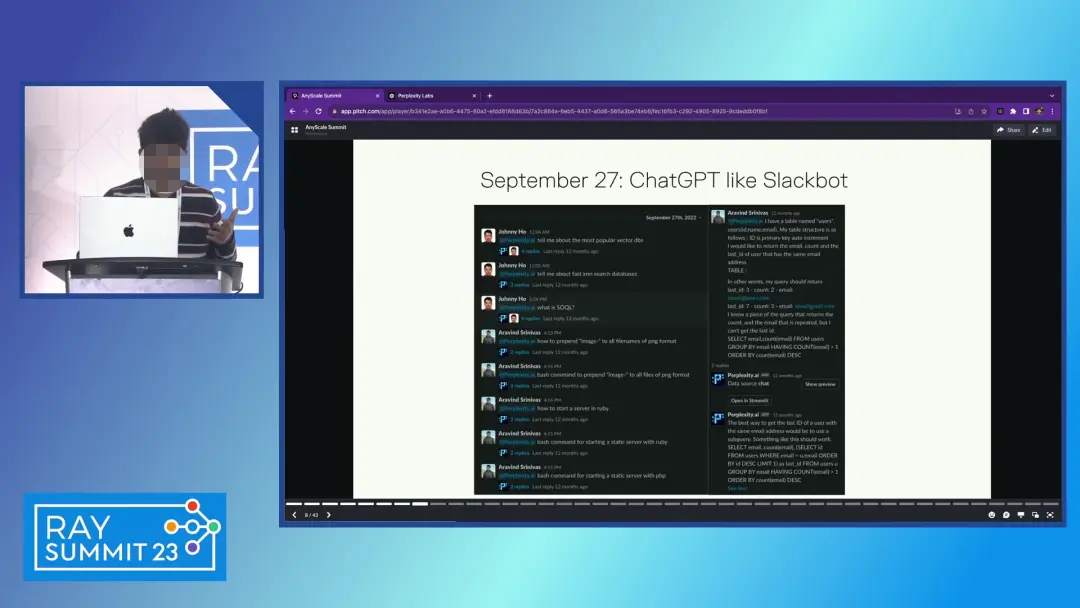
2022年10月16日,出现了一个特殊情况,要招人了!!!
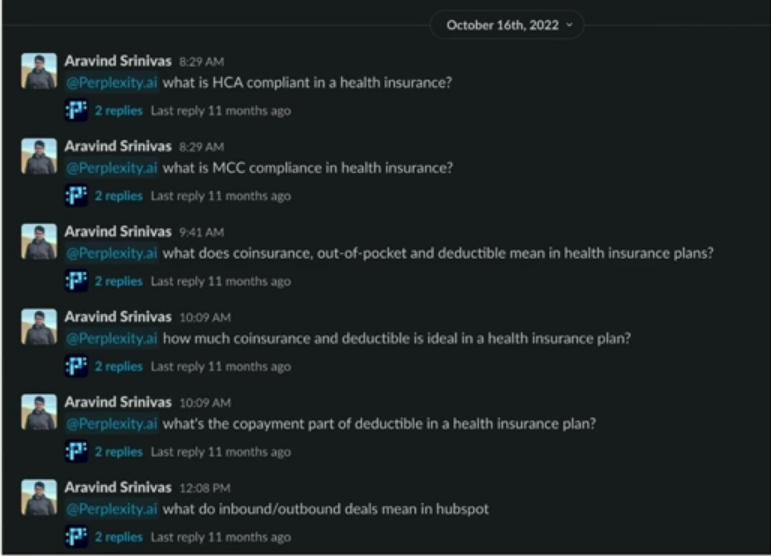
应聘者问:我要医疗保险!Aravind懵了,心想我没弄过啊,赶紧打开Slack去问,对比Google给出的结果,他也意识到了,自己的SlackBot联网后,或许能得到更好的答案。
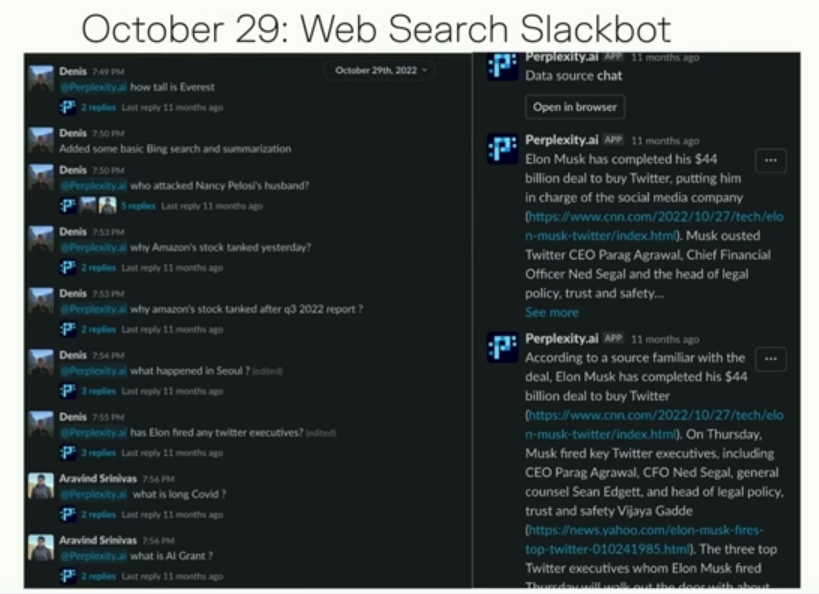
在10月29日,SlackBot可以联网去search了,增加了摘要功能,现在可以向Slackbot提问真实的问题了!比如上图就是马斯克接管推特时发生了什么,已经开始有现在答案引擎的雏形了。
然后,投资人Nat Friedman,也就是前Github CEO,说,你们咋不像Midjourney那样整一个Discord呢?这可比Slack牛逼多了,于是在11月6日,Perplexity做了一个Discord Search Bot:
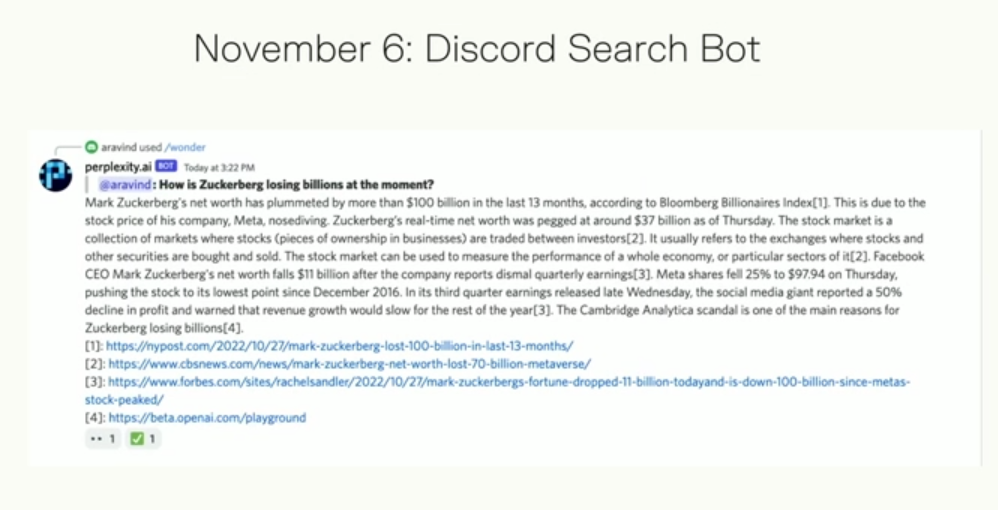
Discord就是一个公开域,这时就开始有用户尝试接入Perplexity的Discord Search Bot,反馈还都挺不错,甚至开始有人说,这比Google好啊!
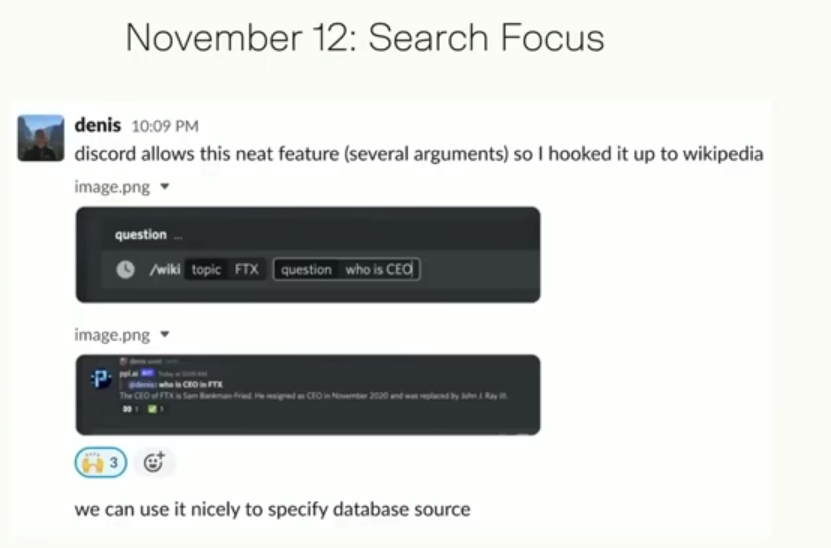
11月12日,增加了搜索聚焦Search Focus功能~
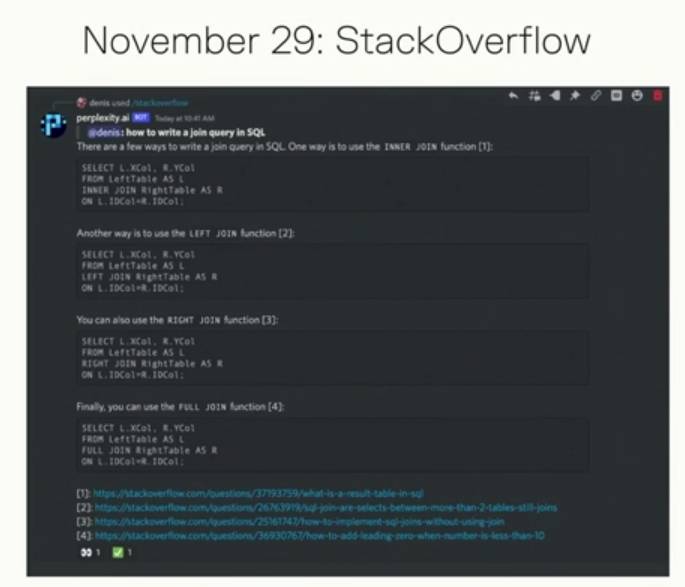
随后增加了维基百科的搜索支持,以及到了11月29日,Perplexity在Discord Bot上增加了支持搜索StackOverflow(全球最大的技术问答网站)。
注意此时,Perplexity的主营业务还是在处理企业的SQL方向呢,Discord的尝试更像是一个副业,不过Discord上的尝试反馈太好了,多巴胺开始分泌!
好巧不巧,次日,也就是11月30日,ChatGPT发布!现在几乎所有人都知道这是一个历史性的时刻,我们看看Perplexity在此之后做了哪些动作!
Aravind问了一个问题:或许,ChatGPT会取代掉所有的对话机器人?
那Perplexity还能做什么呢?对了,把实时知识和Chatbot整合到一起会怎样呢?(彼时 ChatGPT 还不支联网搜索) 尽管那会公司还没有会写前端的工程师,但在ChatGPT帮助下,居然真的做到了,于是:
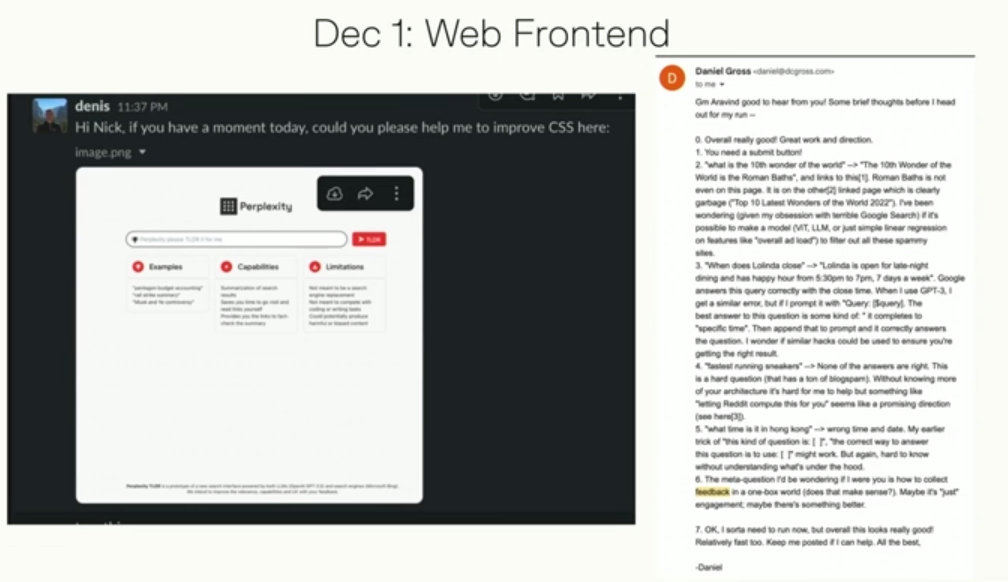
动作很快,12月1日,Perplexity的网页版本就上线了:
他们把网页版本发给了一个投资人,得到了非常好的反馈,这进一步的增强了Perplexity团队的信心!
于是,12月7日,网页端正式上线!获得了几百个用户,反馈普遍还是挺好的~
OK,说回来,Perplexity主要的产品和融资,都是来源于在SQL上做的开发,只不过之前更多是服务于企业,等等,我们再想想,似乎早期Perplexity做的工作很多是在大型关系型数据库上的哦,那有没有什么是公共数据库的SQL版本可以做的呢?
创始人们都是推特的重度用户,于是就想:
“How would it look like if we thought of Twitter itself as a relational database? ”
如果我们把推特本身看成是一个关系数据库呢?
它会是什么样的?社交图谱、推文、粉丝等等。
那就可以找出,我的推文有多少是某个粉丝喜欢的,或者谁是某个粉丝的粉丝但还不是我的粉丝的。。。
于是推出了一个基于Twitter的搜索库,还得到了推特创始人Jack Dorsey的转发点赞:
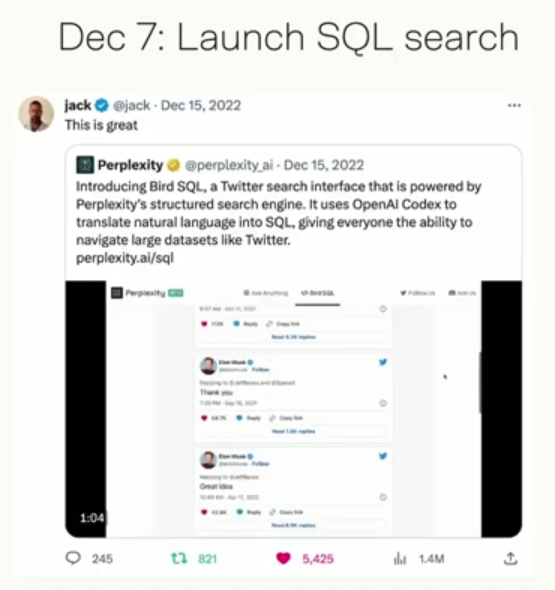
(上图可能是文字错误,应该是12月15日)
注意看文字:
It uses OpenAI Codex to translate natural language into SQL.
在这个产品形态里,Perplexity发现比起SQL搜索,常规的搜索用户量更大~
这里要解释下,常规搜索和SQL搜索的差异,对于理解Perplexity的产品演变很重要:
SQL搜索(对应BIRD-SQL)的核心功能是允许用户通过SQL查询语言在Twitter的大量推文数据中搜索特定的信息。用户可以定义复杂的查询条件,比如搜索特定关键词、用户、话题标签(hashtags)或者特定时间段内的推文。这使得研究人员和分析师能够从Twitter的海量数据中提取有价值的信息,比如分析公众对特定事件的反应、趋势分析、情感分析等,但它需要搜索提供方(此处为Twitter)支持才可以:
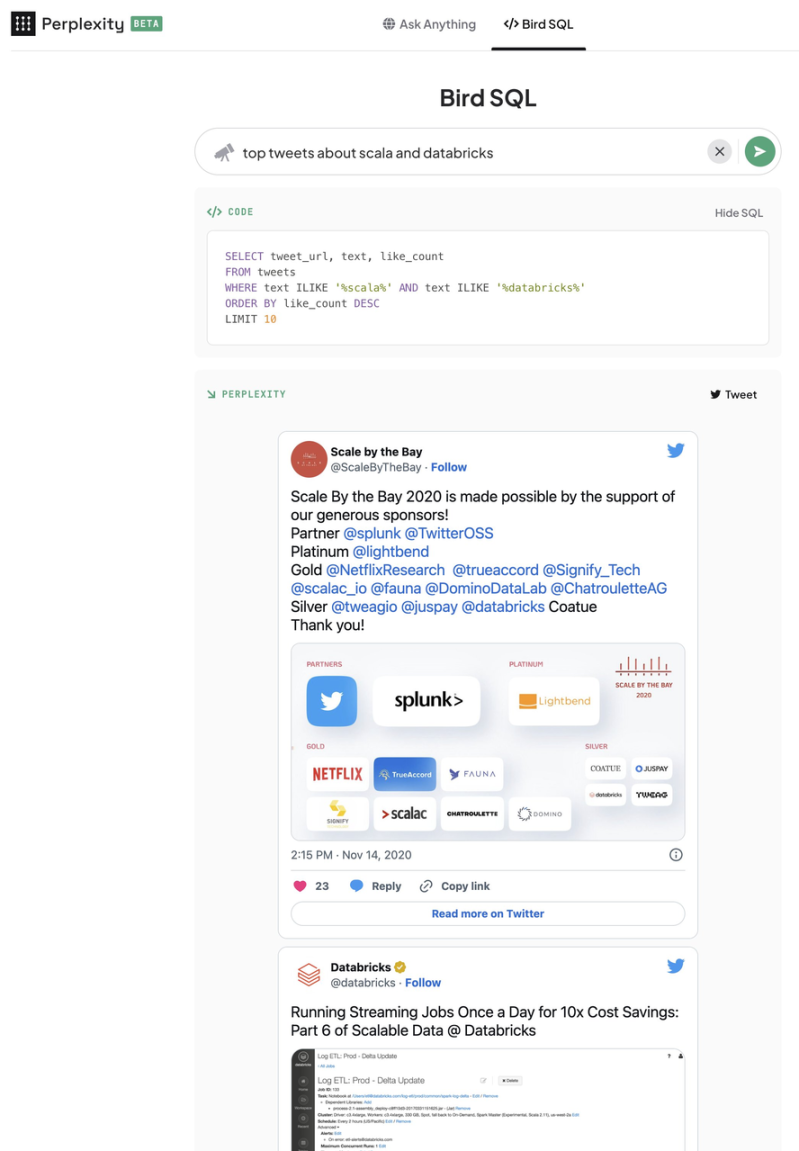
简单理解就是帮助用户用自然语言就能实现更加复杂的搜索技巧,能提高搜索信息的准确性,也因为推特在23年2月份下架了API,Bird SQL 也下线了。
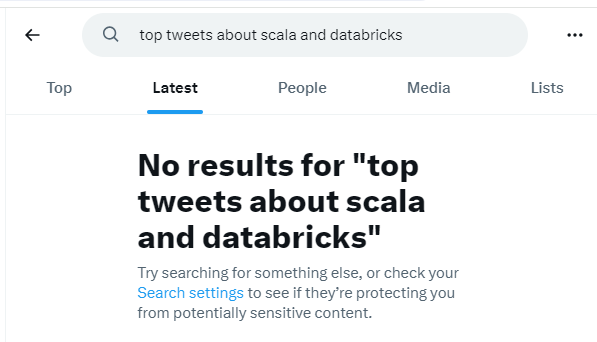
没有Bird SQL 类似的产品支持,所以我们现在再去搜索同样的Quory“top tweets about scala and databricks”,结果就是👆,这就是在推特中进行的常规搜索,在推特是很难获得精准的搜索结果的。
OK,说回来,在当时Bird-SQL火了后,Perplexity还在犹豫要不要结束SQL搜索的研究,马斯克出手了,把API接口价格调整的非常的高,并且此时Perplexity也发现用户非常喜欢用Bird SQL来做普通的搜索,这让Perplexity最终专注于去做答案引擎了:
再往后,就是经典的疯狂迭代逻辑:
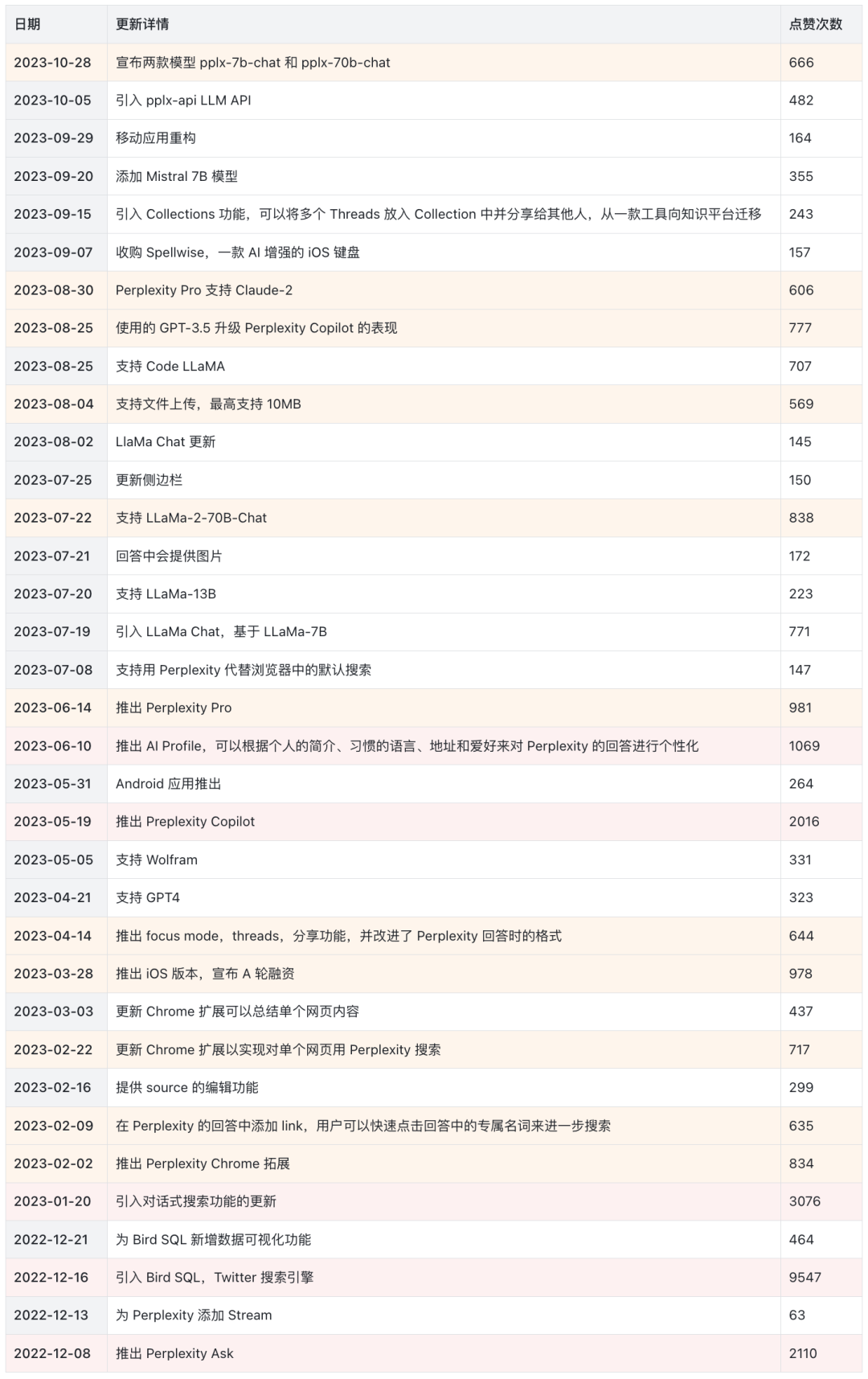
这张图要感谢SenseAI的文章~
四、创始人Aravind对产品的思考
OK,继续来深挖一下Aravind,来帮助我们更好的理解Perplexity.ai。
在之前的文章《AI 佛经:深度用户的胜利》里,Super描述了对于某一方向长期投入带来的产品突破受益点,这一点在Aravind身上也有反应~
这一章我们来进一步理解~先看一下别人整理好的概要:
CEO Aravind Srinivas 来自印度,博士期间才移民来到美国。Aravind 是 UCB 的 CS Phd,主攻方向是在计算机视觉和强化学习中融入 Transformer 模型。Phd 期间,他先后分别在 OpenAI、DeepMind 和 Google 做 Research Intern。毕业后,他加入 OpenAI 工作了一年,研究语言模型和扩散模型。22 年 8 月,离开 OpenAI 创立 Perplexity。
具体来说,Aravind是一个印度人,考上了印度理工学院,2015-2016年对深度学习做了很多研究,2017年考到了UC伯克利大学读博士,和OpenAI的联合创始人,ChatGPT的研究主管John Schulman在同一个实验室!
随后,在2019年去了Deepmind实习,白天工作,晚上就去那的图书馆看书,有几本书写的是谷歌如何工作的,其中拉里佩奇给Aravind的启发很大:
我被PageRank的演变过程所吸引,以及它是如何引领到一个能够创造像Transformers这样惊人进步的公司的。
这个印度小哥很积极,用Cold Email的方式联系上了Transformer的一作:Ashish Vaswani,获得了实习机会!

后面,在Perplexity的投资人名单上,也出现了这位大神:

但是实习期Aravind还是没有明确的创业想法,一直到2022年夏天,Jasper、Github Copilot这样的AI初创公司开始实现真正的收入,包括用户的热情与日俱增,Aravind意识到机会来了!
创立Perplexity后的尝试,我们在上一章节讲过了,一直到2022年12月7日网页版本的Perplexity上线,12月15日,上线了Bird-SQL,即推特SQL搜索功能,获得了很多用户的认可,然后在这次浪潮中Aravind观察到用户更加喜欢常规的搜索方式,叠加上马斯克提高了API的价格,逼得Aravind全面转向端到端的答案引擎。
这次尝试非常成功,有两点:
第一,获得了用户真实的使用行为,最终帮助Perplexity找到了正确的方向;
第二,拿到了一些著名大神的投资,比如Yann LeCun,Meta首席AI科学家,Andrej Karpathy,原特斯拉AI高级总监,现OpenAI副总裁,他们单纯就是看到了Perplexity的推特就投了。
在这之后,Perplexity开始走上正轨!
下面我整理了一些Aravind对于Perplexity产品的思考:
1)Paul Graham的YC创业产品方法论
- 从身边的朋友小范围开始传播→
- 做一些没有规模效应的事,比如和用户亲自交流→
- 构建MVP产品(比如Discord Search Bot,Bird-SQL)→
- 用真正的用户测试MVP(比如Bird-SQL最终帮其获得了洞察)→
- 向用户学习并迭代;
以上几个步骤,可以看到Perplexity完美的遵循了。
2)永远不应该做别人做过的同样的事
谷歌1998年上线,到现在已经20 年,定义了搜索,并构筑了护城河(在后面聊Perplexity护城河的时候我们会具体说)。
如果和谷歌做一样的事情,Perplexity没有任何机会,所以围绕着AI产生的变量,Perplexity寻找着新的方式。
- ChatGPT 没有实时搜索功能→
- 但又有强大的整合推理能力→
- 结合 LLM 和搜索→
- Perplexity 诞生。
这个方式就是答案引擎,《创新者的窘境》提到颠覆式创新的可怕之处在于,原有的大公司很难下定决心“杀死”自己,谷歌的商业价值太庞大了,建立在用户搜索时点击的广告上,答案引擎意味着这些广告不再有高曝光量。
所以这就是Perplexity的机会,Perplexity之所以疯狂的迭代,包括也在建立自己的索引库,就是害怕哪一天Google关闭了搜索API之后,对Perplexity业务的冲击,但一旦构建完毕,Perplexity很可能就不再惧怕谷歌了。
3)围绕构建优势持续不断的努力
谷歌的UI几乎没什么变化,但是背后的技术仍然在不断的提高。
Perplexity也在不断地提高几个要素,典型如:
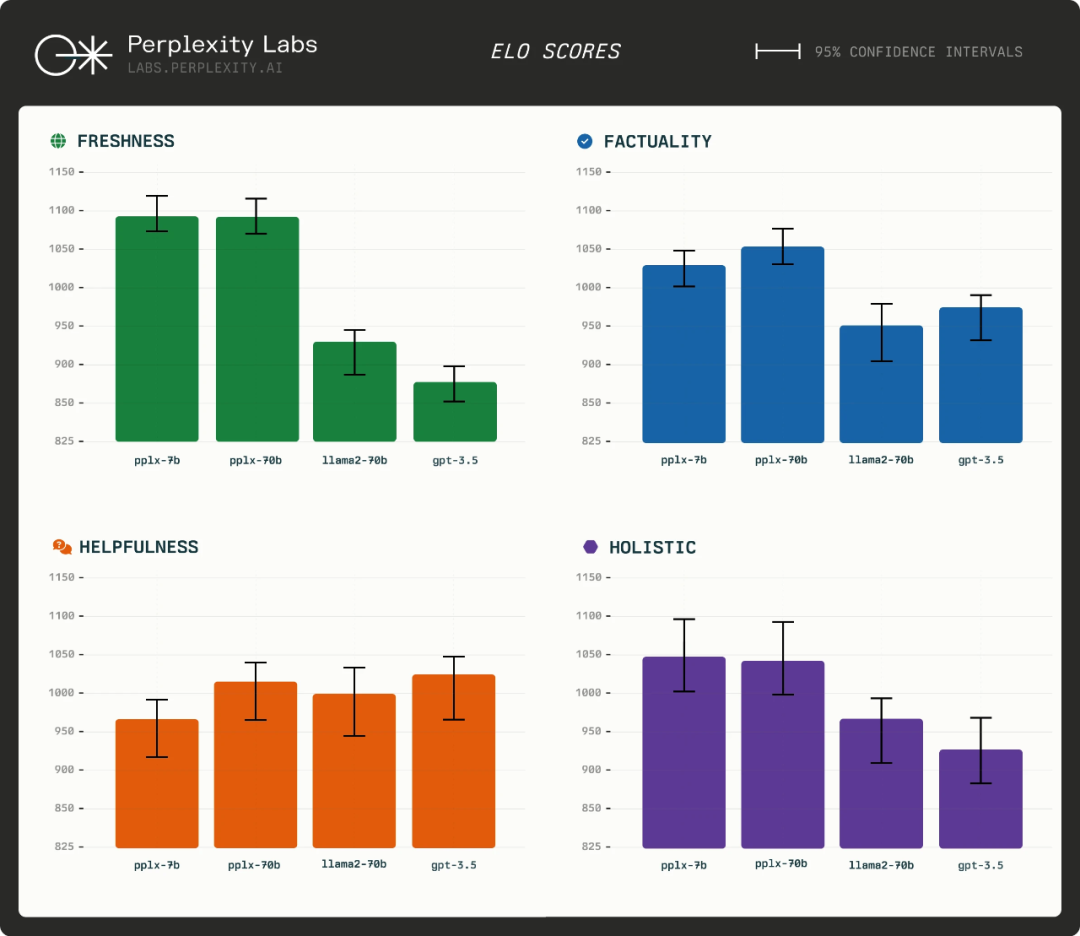
它们非常关注新鲜度、实时性、有效性几个用户感知上最关心的要点,并且不断的提高,上图就是Perplexity自研的pplx-70b-online的测试对比数据,发布于2023年11月29日。
再叠加上前面有个图显示了高频度的功能更新情况,我们可以看出Perplexity一直在高速的围绕用户需求做功能迭代。
4)站在用户角度思考问题
这似乎是老生常谈,但具体到每一个优化细节,你能否真的站在用户的习惯上思考呢?
Perplexity在生成答案时,会先显示搜索来源的链接,再生成答案:
为什么呢?回到用户使用习惯上来讲,在使用传统搜索引擎时,我们会很快的得到返回的搜索结果,Perplexity为了将搜索引擎和答案引擎结合起来,于是把Sources放在顶部,方便一些用户不想等待的时候可以先点击链接去看。
前面我们提到的Bird SQL,也是从用户出发,将用户习惯的自然语言,转化为结构化的SQL语句,然后对接到推特API里,拿到普通用户很难获得的数据!
我总是试图从用户的角度看问题,并尽可能多地与他们交谈。拉里·佩奇(Larry Page)在创办谷歌时有一个理念,即“用户永远不会错”。它简单而深刻。当人们抱怨某些事情对他们不起作用时,我会尽可能多地回复他们的私信。我尽最大努力将这种心态灌输到我们公司的每个人身上。不要责怪用户没有正确表达他们的问题,或者不知道有一个按钮可以分享一些东西。我们的工作是解决这些问题,使产品更直观。
5)一次只做一件事情
Perplexity快速基于用户迭代产品,聚焦解决关键问题,很值得学习。
我们做了很多决策,比如,如果我们支持自由交谈而不是只是一个生产力助手或研究助手,我们可能会得到更多的流量。但我们没有这样做,因为那样会导致产品分叉,让用户感到困惑,对于某种功能,他们可能会有很多用户,而对于另一种功能,他们可能会因为缺乏可靠性而感到沮丧。所以这对我们有很大帮助,让我们保持清晰、简单,一次只做一件事情。
接着我们来看看,Perplexity的用户都是谁呢?
五、Perplexity的用户都是谁,为何用它?
Perplexity的Discord服务器有4.4万名成员,其中有一个频道叫做
Post something about you and share how you found Perplexity
从这里,我查看了一些比较典型的介绍,从中我们可以了解它的用户群:
Hi, my name is Oscar, and I am a Software Engineer. I found Perplexity by looking into alternatives to the one that was the most popular (ChatGPT). And I was really surprised with how fast it is, and the accuracy of the results. I literally use it all day for everyday tasks
嗨,我叫奥斯卡,我是一名软件工程师。我是在寻找最受欢迎的那个(ChatGPT)的替代品时发现了Perplexity。我真的很惊讶于它的快速响应速度和结果的准确性。我几乎整天都在用它来处理日常任务。
M&A investment banker covering AI native companies. Been using Perplexity since late last year and loving it -Pro user ftw
嗨,我是一名覆盖人工智能原生公司的并购投资银行家。自从去年年底开始使用Perplexity以来,我就非常喜欢它——专业用户表示支持。
Hello everyone, I’m KP. I’m a software engineer. Been playing around with Chat-GPT from so long and recently got hooked with xAI because of the realtime capabilities. Found perplexity on hackernews and damn surprised by the realtime capabilities. First thing – cancelled my ChatGPT plus. Excited about the future of Perplexity
大家好,我是KP。我是一名软件工程师。我一直在玩Chat-GPT,最近因为实时能力而迷上了xAI。在Hacker News上发现了Perplexity,真的很惊讶于它的实时能力。第一件事——我取消了我的ChatGPT Plus。对困惑度的未来充满期待。
hey! I’m a second year university student who uses Perplexity for reaseach. As someone with ADHD and slow processing speed, perplexity is great for helping me find sources for obscure and complex information, amongst helping me exand creative pursuits
嘿!我是一名大二的大学生,我使用Perplexity来进行研究。作为一个有注意力缺陷多动障碍(ADHD)和处理速度较慢的人,Perplexity在帮助我找到关于晦涩和复杂信息的来源方面非常出色,同时也帮助我扩展了我的创造性追求。
hey folks, I’m sam and i’m a product manager. been playing around with different genAI tools and hoping to build some small apps on more niche verticals. super impressed by perplexity and how fast it’s become part of my day-to-day workflows. the ux is also kickass and so user-centric, awesome stuff
嘿,大家好,我是Sam,我是一名产品经理。我一直在尝试不同的生成人工智能工具,并希望在更小众的垂直领域构建一些小应用。我对Perplexity印象深刻,它如此迅速地成为我日常工作流程的一部分。用户体验(UX)也非常棒,非常以用户为中心,真是棒极了。
接着,我们来到另一个频道:
Post a link to what you’ve learned with Perplexity recently
这里会有很多用户分享自己在Perplexity搜索后的答案链接。

有产品经理来了解如何学习编程的~

有上传图片来识别截图来自哪个电影的!
有用来协助进行科学研究的!
有用来快速总结TGA2023亮点的~

英国移民新政策的摘要
科幻作家用来搜索一些事实性内容
用来学习Python
看下来不少是用来做研究的,也有很多是希望用Perplexity来快速获得答案。
从少量样本的用户反馈来看,发现有明确需求的用户群体居多,不少用户有技术背景,比较追求效率(快速获得答案),对于专业性有一定要求,以及会认为Perplexity可以替代其他如ChatGPT或者Google等产品。
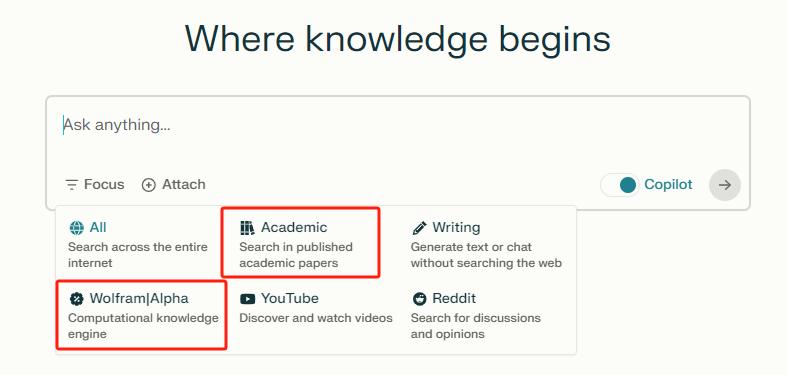
我们从Perplexity可选的Focus功能的分类也能看出一些端倪:Perplexity有部分用户确实是专业人士,希望更高效率的获得答案!
我们看了Perplexity,也可以看看一些竞品,典型如国内的:
六、国内竞品:天工AI搜索
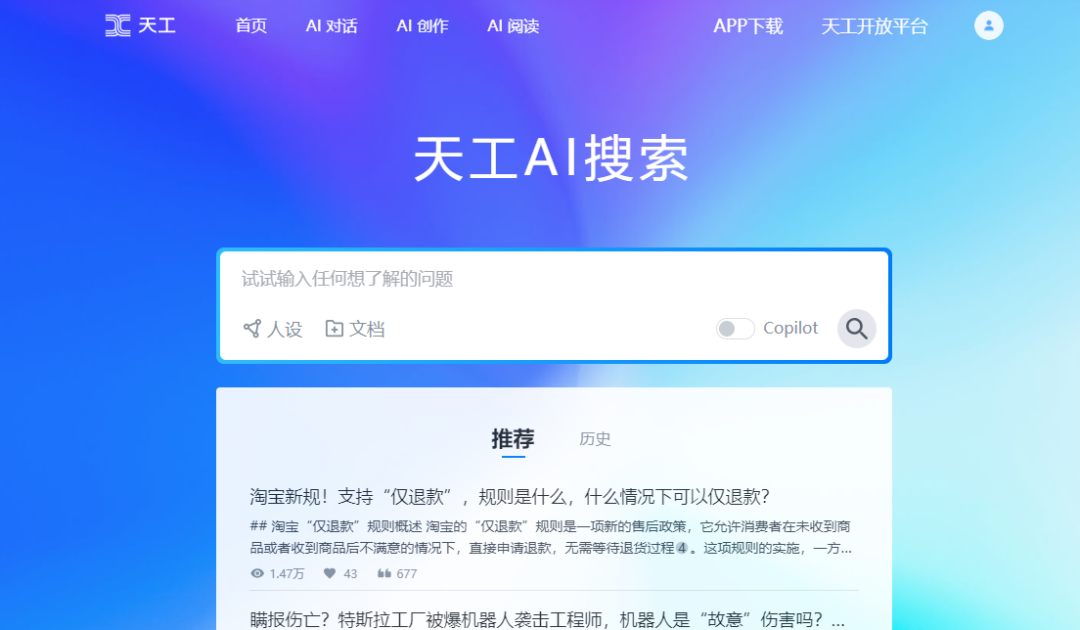
天工AI搜索在主产品上基本像素级致敬了Perplexity。
有人设(对应Perplexity的Profile):

有Copilot(类似Perplexity的Copilot):
也有推荐(对标Perplexity的Discover)

答案详情页也基本Copy:
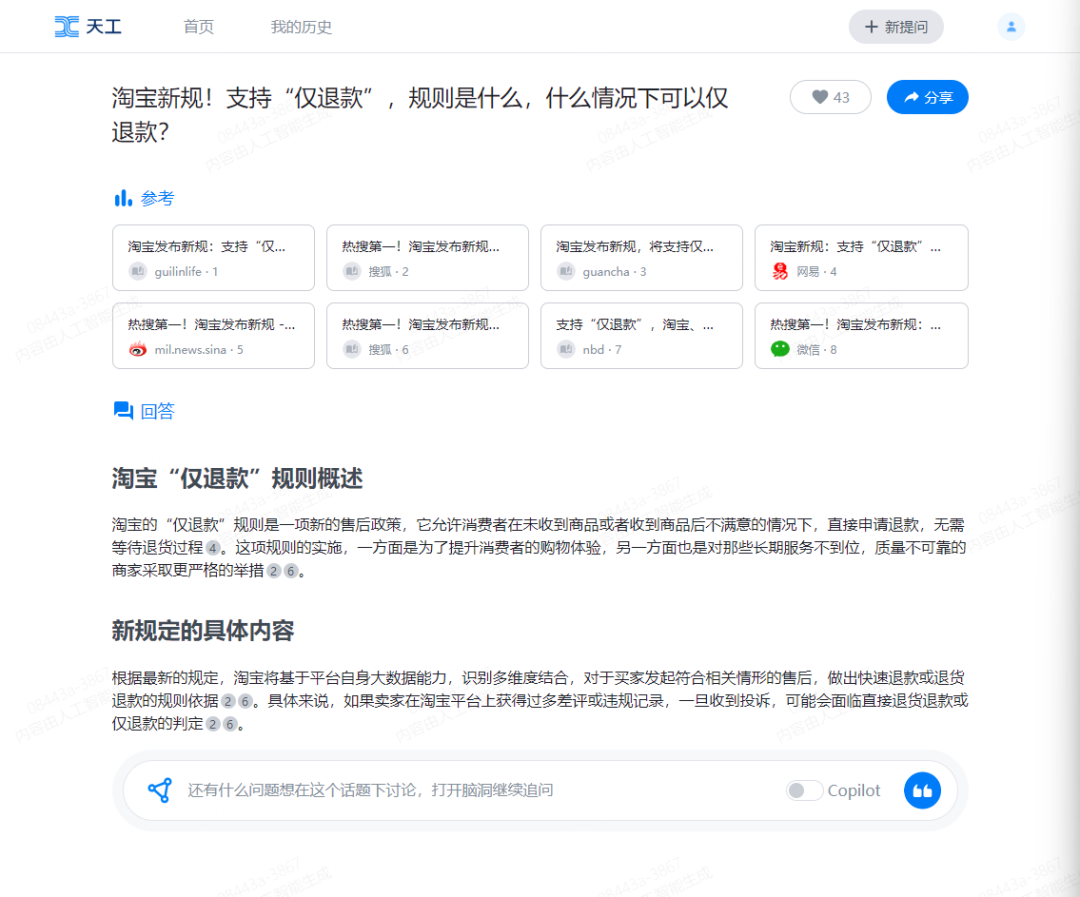
在产品上还叠加了一些其他入口,比如AI对话、AI创作,以及AI阅读。
我们重点说一下AI阅读这一个功能,因为这一功能可以帮我引导大家到我想聊的一些点上去,这个功能在移动App端展现的更加充分一些:
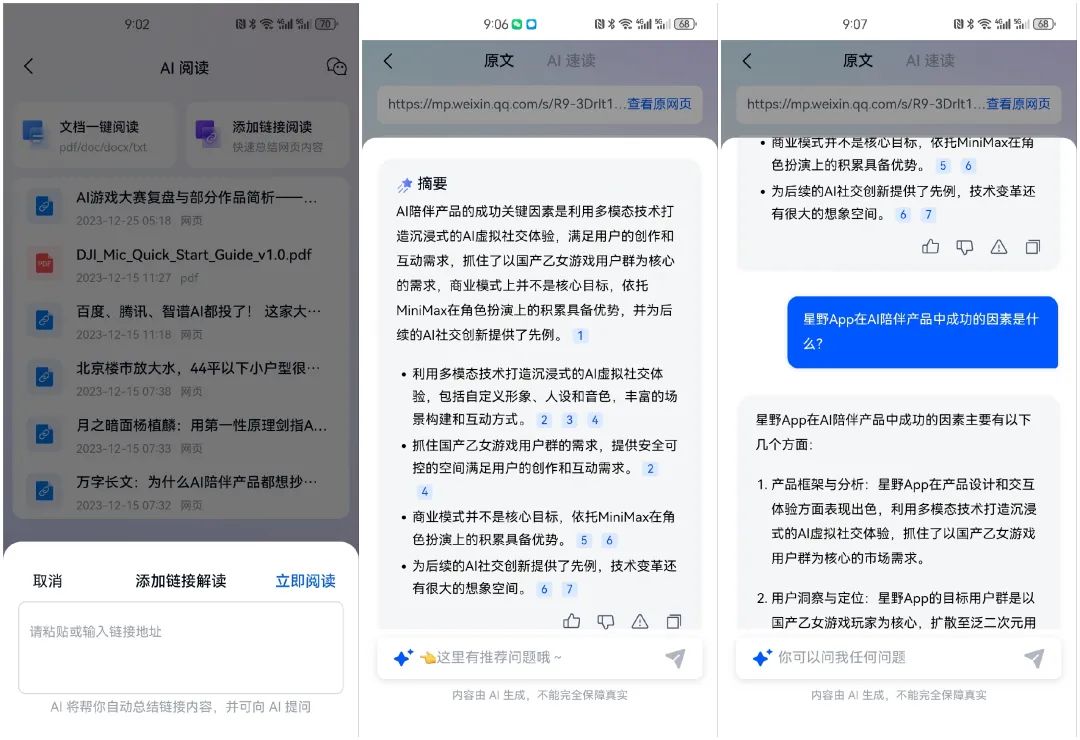
在App内需要复制链接地址,点击立即阅读后会生成文章摘要,可以基于文章向AI提问。
当然,目前的路径脱离了微信生态,天工也尝试引导用户扫码添加,但实际尝试后发现添加的是客服消息,在微信生态内仍然无法实现转发,只能复制链接:
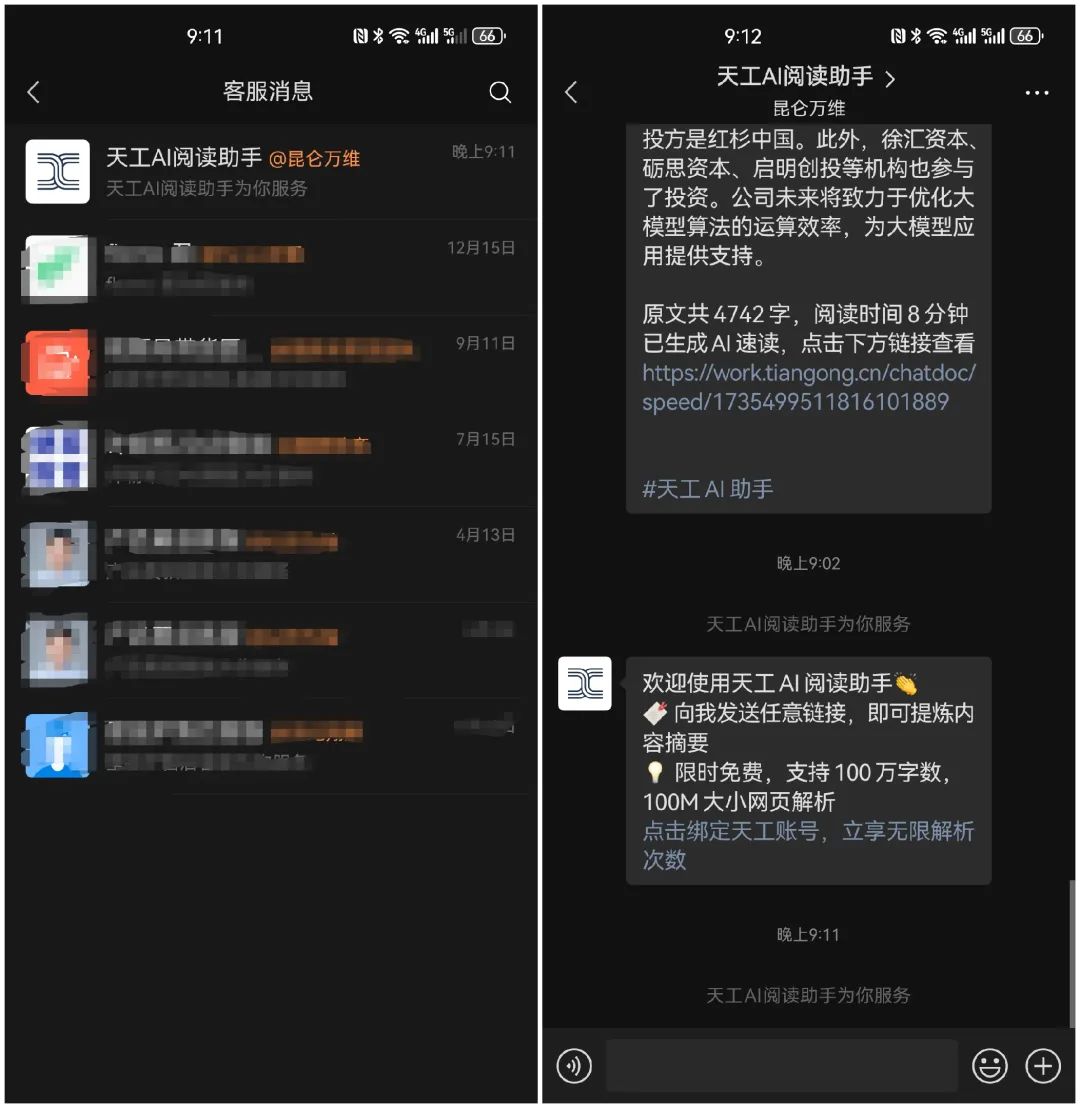
这个功能,既然天工想要免费的策略来获得用户,那在AI阅读以及微信端的布局就太浅了。
这里我建议有远见的大模型公司,应该尽快抓住微信生态的知识信息管理机会,快速通过裂变获得大量的用户,以及构建他们在自身产品层面的资产~
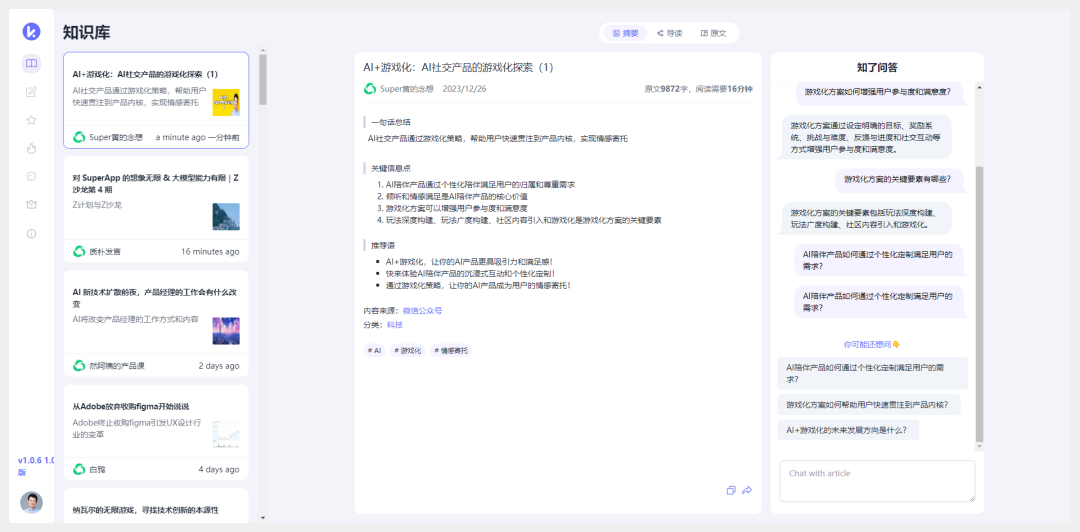
目前知了阅读就在朝这个目标努力:
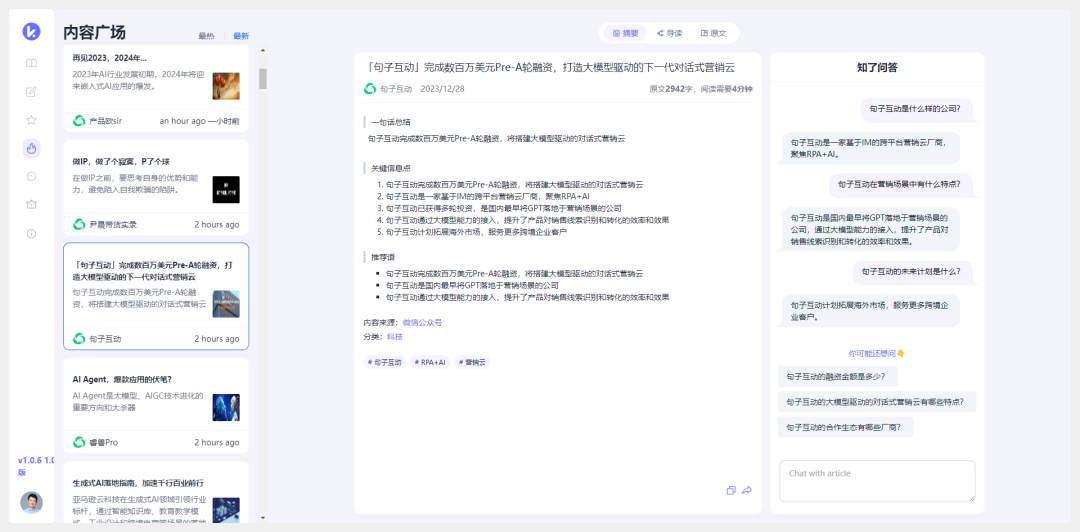
他们还做了内容广场,有些像一个优质内容分发:
类Perplexity产品完全可以作为摘要bot形态,作为企微账号存在,允许被拉入各微信群,获得大量的用户互动行为,进而导流到自有H5页面。
并且更进一步可以做内容订阅,设定固定时间推送摘要内容,帮助用户快速完成内容获取。
除此之外,也可以增加分类热点新闻榜,每个新闻点击后快速提供摘要信息,满足一部分用户的信息获取需求。
我们可以思考,Perplexity作为答案引擎,站在用户的角度,他们在什么场景下对什么答案有需求,我们可以去上游截取,用好的解决方式满足他们的需求,就可以获得大量的用户和数据,并争取让他们在产品上面留下资产,包括订阅、笔记、收藏等等。
所以,做Perplexity竞品单纯从技术和产品层面上是简单的,如何挖掘出发挥技术优势同时也是用户需求的好场景,才是我们在看竞品时应该多去琢磨的:)
下面我们接着回来看Perplexity:
七、两个方面理解它的下一步
Perplexity 目标是搜索引擎的下一代,答案引擎。从现有的路线来说,大体有两条路线会走。
第一个是技术持续进化。
第二个是寻找用户场景,将产品渗透到用户的日常生活中,从 weekly app,进一步变成 daily App。
我们对这两个点逐一展开:
1. 技术持续进化
从前面技术结构来看,目前Perplexity有两块是重点依赖于外部资源的,一个是LLM,一个是搜索引擎,这两块都会带来较大的成本以及竞争风险。
LLM层面,Perplexity最近已经推出了自己的两个全新Online LLM,包括之前已经发过的7b,和最新的70b
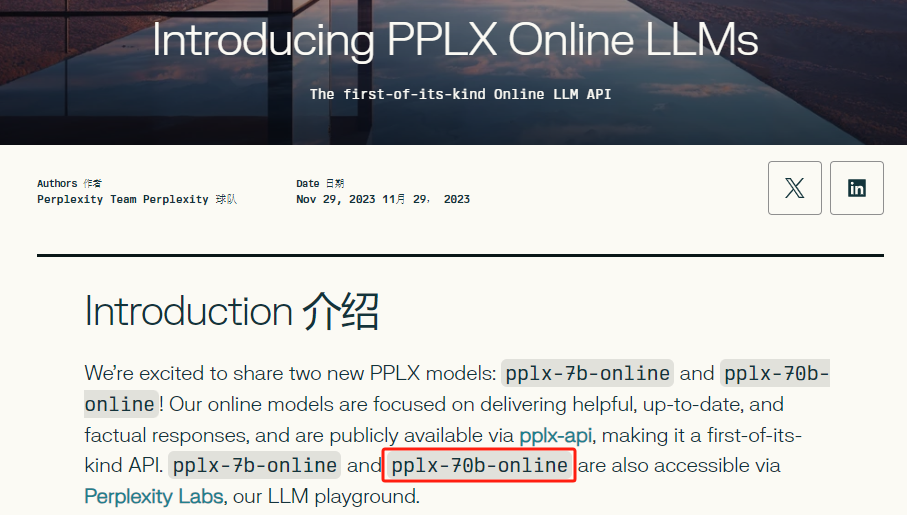
通过pplx-api,就可以访问这两个模型,价格嘛,自己看:
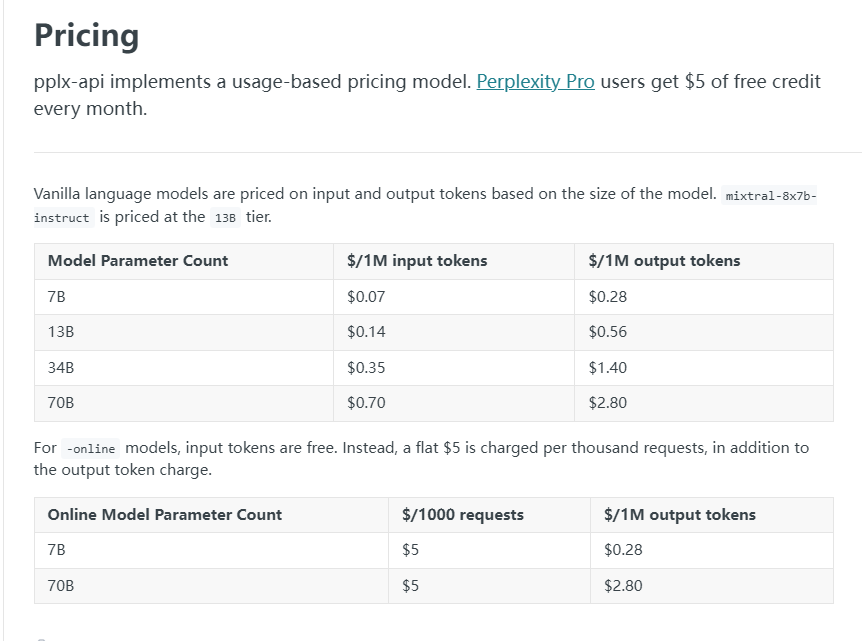
单纯看token消耗的费用,70b-online的费用要低于GPT3.5 Turbo的价格,但还有个API请求每千次5美刀的费用。
70b-online的模型,基于开源模型Mistral-7b和Llama2-70b而来,是一个完全自有的模型。
以及这个API是一个阳谋,调用它的客户多了,就能为Perplexity带来海量的数据:
We collect the following types of information:
API Usage Data: We collect information about your use of our API, such as the number of requests, the content of the requests, and the timestamps of the requests.
User Account Information: When you create an account with us, we collect your name, email address, and other relevant contact information.
我们会搜集使用API的所有信息,包括请求的内容!
请求的内容里,有一点很有趣,Perplexity就可以通过客户付费使用API,来获得更多的索引信息,从而构建自己更强大的索引库!
一旦有了强大的,经常更新的索引库,Google、Bing的护城河就被破坏了,Perplexity也就不用再为索引库的调用而付费了,整体的产品运转成本就会大幅下降。
所以,在技术层面,Perplexity,自建online-LLM一举两得,不光可以大幅减少对OpenAI、Claude的模型调用,还可以减少对Google、Bing的API调用,变成借鸡生蛋,靠着客户的API调用,自建庞大的索引库,以及填补成本。
包括,Online-LLM,对于答案的生成也可以不断优化质量,
Our search index is large, updated on a regular cadence, and uses sophisticated ranking algorithms to ensure high quality, non-SEOed sites are prioritized.
Our models are regularly fine-tuned to continually improve performance.
不光自建了庞大的索引库,并且根据自己的算法优化索引排序,还会定期对LLM进行微调来保证性能。
此时,Bing在今年5月份提高了搜索API的价格,甚至未来有可能对Perplexity关闭API调用,这些外部因素都不会再影响Perplexity,在此之前,Perplexity知道自己的七寸在对方手里,拼了命的迭代!
2. 寻找用户场景
其次是用户侧,有三点:
1)沿着Discover,帮助用户更好的发现信息
如何更好的发现信息,上一章节我们已经提到了一些可能性,包括了订阅、热门榜单等有助于更快将信息传递给用户的合理手段。
2)沿着Library,构建AI版本的维基百科
这一块未来有社区的可能性,前提是需要一定的运营能力,将PGC引入,甚至是学习维基百科的策略,用开放包容、知识共享、协作机制和社区文化等慢慢培育内容生态。
早期还是要建立一些高质量的内容聚合,并不断更新和对外传播,开始滚雪球。
3)沿着Copilot,更好的理解和直接处理信息
验证答案引擎这一要点,可以进一步思考,用户获得了答案之后,是否有一条支线会导向后续的动作,比如机票查询、电商物品搜索等等,Copilot当前只解决了从Query到答案之间的优化,下一步,可以往Agent发展,直接帮助用户快捷完成行为动作,减少用户的行为成本。
聊了很多产品层面的点,接着来聊聊它的商业模式:
八、商业模式
当前Perplexity主要依赖toC的订阅 toB的API调用两个。
10月份根据网络报道,Perplexit的ARR是300万美元,这对于一个初创公司来说并没有参考意义,个人认为对于用户新增和活跃来说,Perplexity更愿意放弃掉这笔ARR的部分来换取:
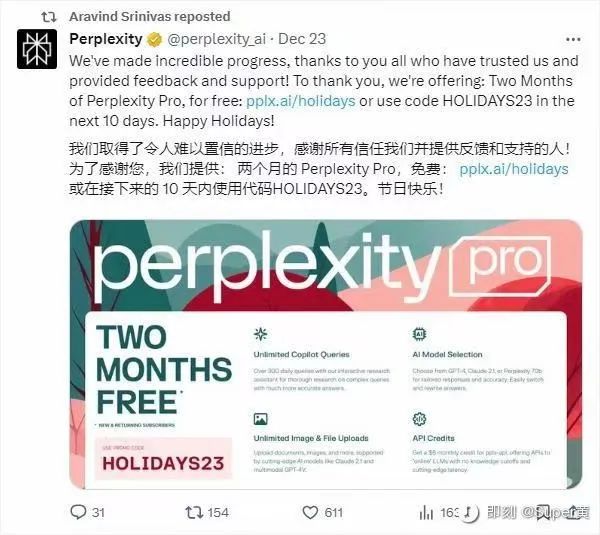
12月23日,Perplexity宣布提供Pro的2个月免费代码,据我观察,在此前Perplexity也搞过类似的促销,其实还是希望更多人能够更多去深度的使用,从而形成粘性,以及获得口碑。
toB的API,我们也说了是一举两得的明智之举。
更多的商业变现路径,包括了基于用户Profile更精准的广告投放,以及Agent完成的付费行为可能带来的佣金收入等。
但对于搜索这一马太效应极其明显的市场来说,获得更大的市场份额才是Perplexity当下的重点,通过LLM构建的答案引擎,天然的背离了Google养成的极大的三方共赢生态,也需要时间来构建自己AI时代的商业闭环。
总之,AI-Native更加讲究用户数据的价值,基于数据飞轮、更深度的用户使用情况、更个性化的深度服务,新的商业模式是完全有可能建立的,是阶段问题,我理解目前节点,Perplexity也并不急于构建,更多会去探索合理的模式,寻找到持续的高粘性场景,突破外部限制条件(依赖搜索巨头API)会更为重要!
那到底Perplexity有没有机会取代Google呢?
九、Perplexity能否取代Google?
在起初,创始人Aravind也怀疑自己,在一个Google时代做搜索,似乎不是好时候,现在一个冉冉升起的新星似乎让人们越来越清晰的看到了下一代Google的影子?
别着急,在文章一开头,我们也提到它的流量持续在上涨,但根据similarweb的数据,Perplexity的流量分布占比最大的是印度尼西亚,并且美国的流量在往下掉:
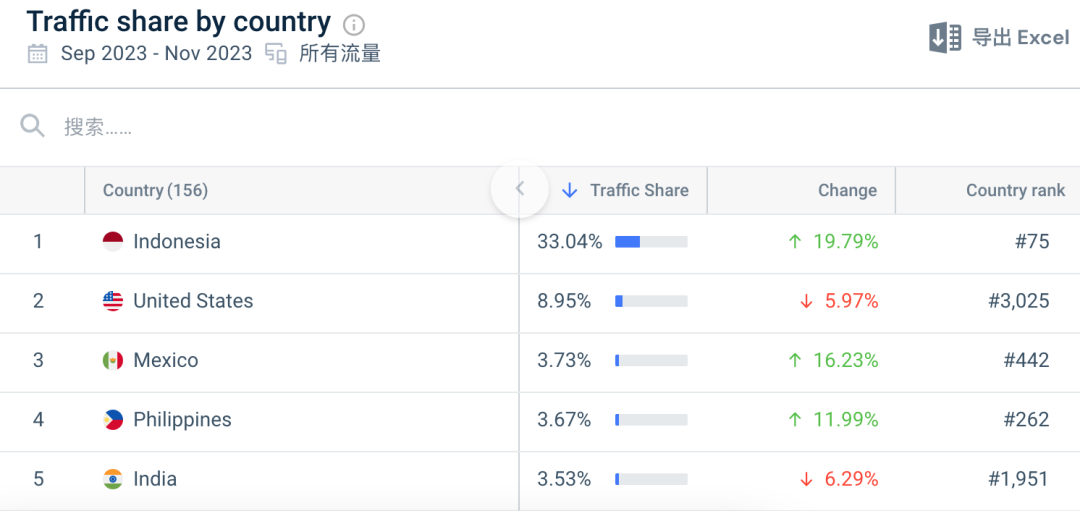
是的,清醒一点!Perplexity离取代Google还非常遥远,在新闻总结、内容摘要、知识相关的快速整合方面,Perplexity某些时候能做到十倍级的提高,但依然有很大的用户群体是无法覆盖的,这里有几点因素:
- 用户使用习惯,品牌信任,和老牌Google来比,Perplexity还需要长期的市场营销努力;
- 大部分人只能输入关键词无法输入长句子;
- 流量入口把持,如Google每年花上百亿美元购买苹果Safari浏览器的默认搜索引擎,还有安卓生态等;
- 技术成熟度,Perplexity还在持续进化,包括幻觉、答案生成质量还有待提高;
- 商业化,Perplexity还是需要建立可持续的商业模式才能长期发展。
我们会看到一些更垂直的搜索场景,比如Devv.ai,在科研领域是完全可以替代掉Google的,甚至可以整合进LDE内,加速放大研发效率,这样的细分市场反倒是无人质疑!
不过,也可能会有一些重大变量带给Perplexity新机会,典型如新的交互形式,特别是硬件(新设备形态),大家都看过AI Pin,在这类硬件产品里,不宜做过多的交互,Perplexity直给答案的逻辑就更加适合,因为可以大量减少交互量。
另外就是将Copilot升级为Agent带来的可能性,直接帮助用户解决最终的需求,比如从搜索机票,到直接帮助购买机票,这也是Perplexity的机会。
以及,我们也不能忘了下面这张图带给我们的启示:
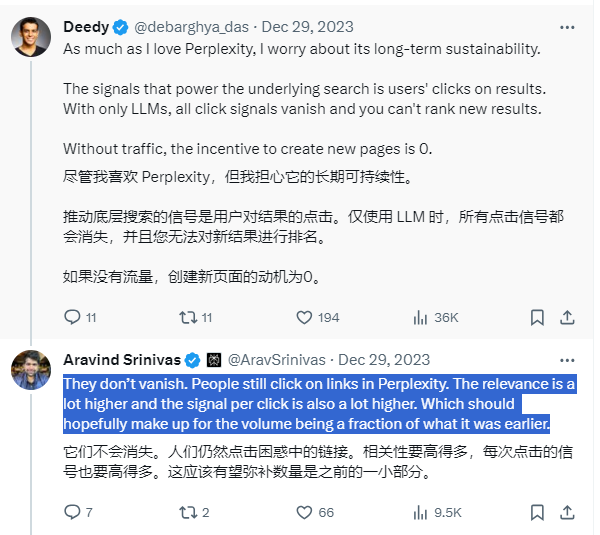
更远的未来,是大模型本身能力进一步提高,在语义理解和答案返回层面,能再一步提高,甚至说对于关键词输入也能给出10倍级的体验优化,到时就是Perplexity的机会,基于搜索像燃油车,LLM像新能源车,这种颠覆机会仍然存在。
说句真心话,挑战巨头太难了,说Perplexity失败是一个非常简单的行为,也是用当下的视角理解产品技术演进的结果。但正如那句古老的智慧所言:“悲观者永远正确,乐观者永远前行。” Perplexity或许在某些方面尚未成熟,但它正以乐观者的姿态不断探索和进步,寻求在搜索领域的新突破。在这个快速变化的时代,只有那些敢于梦想并勇于实践的创新者,才能抓住未来的机遇,引领行业的发展。
总结
Perplexity,在它身上我看到TPF和PMF结合的点:
TPF(技术产品匹配)在于:
RAG的引入解决了幻觉和实时性弱的bug 这样就能发挥LLM的语言理解及推理能力了。
PMF(产品市场匹配)在于:
人们搜索背后是希望更快获得想要的答案。
抽象一下Perplexity产品流程,我们可以找到更多的应用领域:
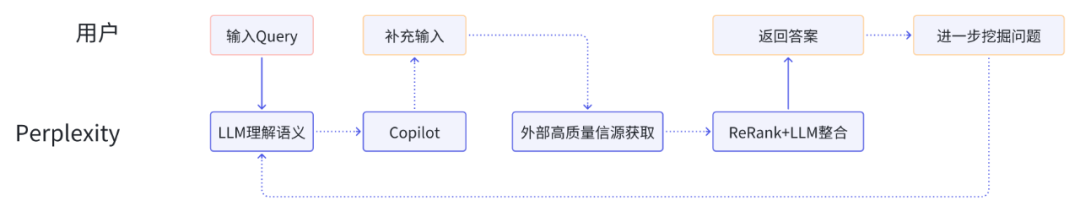
重要的是,从Perplexity身上找到更好的产品方法论,以及找到TPF和PMF的结合点,最后我们来个总结性的思考:
- Perplexity的“成功”在于它对用户需求的深刻理解和对技术趋势的敏锐把握。
- 它的商业模式和产品策略为我们提供了一个关于如何在AI时代创新的宝贵案例。
- Perplexity的挑战在于如何持续优化用户体验,同时建立起强大的品牌信任和市场地位。
- 对于其他AI产品开发者来说,Perplexity的发展历程是一个值得学习的蓝本,它展示了如何在竞争激烈的市场中找到自己的定位,并不断进化。
- 中国市场也迫切需要这样以答案为导向的新型搜索引擎,创业者可以抓住时机布局,同时结合中国国情和互联网生态设计产品和商业模式。
仔细分析完后,我们不仅对Perplexity有了更深入的了解,也为AI产品的未来发展方向提供了新的视角。我相信,这篇文章的价值远不止于此,它激发了我们对于AI技术如何更好地服务于人类社会的思考。
参考
AI 搜索|关于搜索的想象,和目前估值最高的生成式搜索引擎 Perplexity
Perplexity AI,比Google Bard和Bing Chat更靠谱的问答引擎
中金:从Perplexity看AI 搜索的破局之道
AI 时代错误的商业模式 – “好10倍” 且 “更便宜” 吗?
Introducing pplx-api
https://blog.perplexity.ai/blog/introducing-pplx-api
Creating the future of search and competing vs Google with Perplexity AI’s Aravind Srinivas | E1770
https://www.youtube.com/watch?v=7iU6K7NccXk
Gunning for Google with Perplexity CEO Aravind Srinivas https://www.youtube.com/watch?v=ix4_rdogcVI
Introducing PPLX Online LLMs https://blog.perplexity.ai/blog/introducing-pplx-online-llms
How Perplexity.ai Is Pioneering The Future Of Search https://www.forbes.com/sites/joannechen/2023/09/06/how-perplexityai-is-pioneering-the-future-of-search/?sh=7abebb01ad91
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
