网络数据分析和可视化
1 项目描述
以豆瓣电影上提供的电影数据为例,完整地展示网络数据从获取、处理到分析、可视化这一过程,纯当练手,也为感兴趣的小伙伴提供相关的技术介绍。项目代码托管在Github上,可视化网站请访问这里。

豆瓣电影数据可视化.png
2 数据获取
用python写爬虫,Scrapy和urllib2都是比较好的选择,由于我对功能的要求比较简单,故选择后者即可。
在豆瓣电影上通过Chrome开发工具找到数据请求API,接下来就可以写代码爬一些电影数据了,我使用的是这两个API:
- http://movie.douban.com/j/search_tags?type=movie
- http://movie.douban.com/j/search_subjects?type=movie&tag=爱情&page_limit=20&page_start=0
第一个API是获取所有电影的分类即tag,第二个是请求某个tag下偏移为page_start的page_limit条电影数据,包括电影的标题、url、评分等信息。
有了电影的url,再次爬取该页面对应的html内容, 然后用Beautiful Soup解析出想要的字段就好了。最终一共获取了4587条电影记录,每条记录包含以下15个字段:电影ID、标题、链接、缩略图、评分、导演、编剧、演员、分类、上映国家、语言、上映时间、时长、别名和简介。
3 数据清洗
这一步主要是为了提高数据质量和配合后续的工作,对获取的数据进行一些清洗和预处理工作。比如将字段里多余的空白去掉、将上映时间仅保留年份、将时长处理为以分钟为单位的整数等,下图是同一条电影数据在清洗前后的对比。

数据清洗样例.png
4 数据分析
最基本的分析包括一些统计量的计算,说白了就是固定或以某一个字段分类,对另一个字段进行求和或求平均。我的主要分析字段是电影数量和平均评分,看它们和电影分类、语言、上映国家、上映时间、时长等其他字段之间有何关联。
5 数据可视化
俗话说,“一图胜千言”,所以数据分析的结果以可视化网站的形式给出。我用Flask搭建了一个简单的网站,用Echarts绘制了一些简单的图标来展示分析的结果,可视化网站请访问这里。
网站包含三个子菜单:统计、评分、搜索。“统计”展示了和电影数量相关的分析结果,“评分”展示了和电影评分相关的分析结果,“搜索”则提供了一个简单的基于关键词匹配的搜索功能。它们看起来大概是这个样子:
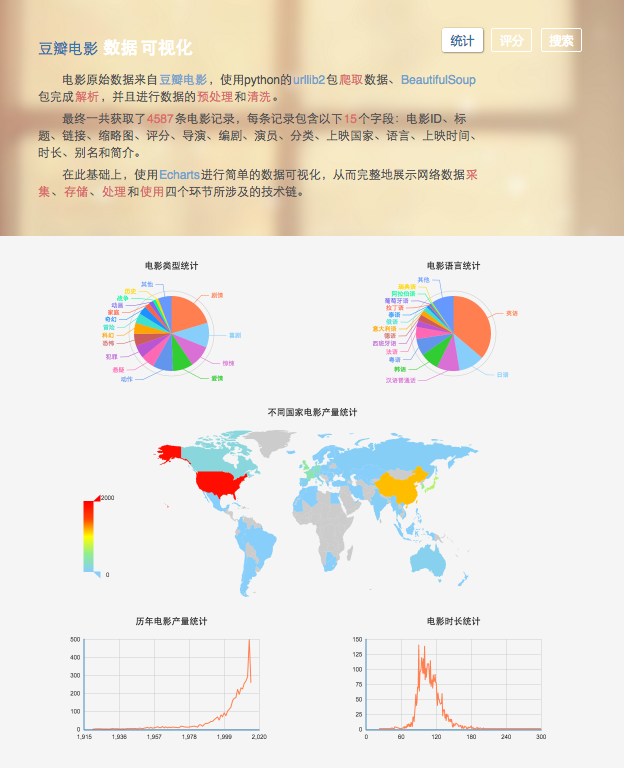
统计页面.png

评分页面.png

搜索页面.png
6 总结
这次开发任务主要出于个人兴趣,顺便抛砖引玉地和大家介绍一些基本的方法和技术。网络上可以获取的数据不计其数,只要脑洞开得够大,在数据源、分析技术、可视化方法上进一步提升,就一定可以创造出更有意义和价值的成果。
文/伦大锤
关键字:大数据, 字段
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
