[原]解密Airbnb数据流编程神器:Caravel 颠覆许多大数据分析平台的开源工具
概述
我非常认同前百度数据工程师、现神策分析创始人桑老师最近谈到的数据分析三重境界:
统计计数
多维分析
机器学习
数据分析的统计计数和多维分析,我们通常称之为数据探索式分析,这个步骤旨在了解数据的特性,有助于我们进一步挖掘数据的价值。而基于我们对数据的理解,再引入机器学习的算法对数据做出预测就变得水到渠成了。
现实世界里,大部分的公司更多时间其实没有这个精力去搭建复杂的数据分析平台,面对快速变化的业务需求,很多数据工程师都把自己的青春埋葬在SQL里了。(其实我也是埋葬在SQL里的)
这几年,所谓的无埋点技术、自助式分析等等概念开始兴起,得益于数据领域的快速发展,国内外也涌现了大量基于数据分析平台的start-ups,而随着技术的发展,许多创业公司也是抱团取暖组成一个更大的团体。
考虑到国内数据安全性的问题,即使我们使用大厂比如百度的网站分析服务也很难保证数据安全性,私有化部署才是很多企业级解决方案的王道。
随着 Caravel 被Airbnb的数据科学部门开源了,我看到的是有许多数据分析平台的创业公司或许要转变方向了,自助式分析将不再依赖于各大厂商!
什么是Caravel
Caravel的中文翻译是快船,而Caravel其实是一个自助式数据分析工具,它的主要目标是简化我们的数据探索分析操作,它的强大之处在于整个过程一气呵成,几乎不用片刻的等待。
Caravel 的特性
Caravel通过让用户创建并且分享仪表盘的方式为数据分析人员提供一个快速的数据可视化功能。[br]在你用这种丰富的数据可视化方案来分析你的数据的同时,Caravel还可以兼顾数据格式的拓展性、数据模型的高粒度保证、快速的复杂规则查询、兼容主流鉴权模式(数据库、OpenID、LDAP、OAuth或者基于Flask AppBuilder的REMOTE_USER)[br]通过一个定义字段、下拉聚合规则的简单的语法层操作就让我们可以将数据源在U上丰富地呈现。Caravel还深度整合了Druid以保证我们在操作超大、实时数据的分片和切分都能行云流水。

数据库支持
Caravel 是基于 Druid.io 设计的,但是又支持横向到像 SQLAlchemy 这样的常见Python ORM框架上面。
那Druid又是什么呢?
Druid 是一个基于分布式的快速列式存储,也是一个为BI设计的开源数据存储查询工具。Druid提供了一种实时数据低延迟的插入、灵活的数据探索和快速数据聚合。现有的Druid已经可以支持扩展到TB级别的事件和PB级的数据了,Druid是BI应用的最佳搭档。
想必,你已经受够了Hive那个龟速查询,迫不及待想体验一下这种酣畅淋漓的快感了吧!
实战
既然,要行云流水,没有Docker是不行的,想要了解一下Docker可以参考之前的文章:海纳百川 有容乃大:SparkR与Docker的机器学习实战
这里我默认你已经具备了使用Daocloud加速Docker的知识。
本地跑Docker
下载镜像:
dao pull kochalex/caravel
跑容器
docker run -p 8088:8088 -d kochalex/caravel
查询一下你的docekr ip
docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
default - virtualbox Running tcp://192.168.99.100:2376 v1.9.1
dev - virtualbox Saved Unknown
这里可以看到我的默认Docker的IP是192.168.99.100
所以需要在浏览器中访问 192.168.99.100:8088
这样我们又是三行代码搞定了一个大数据分析神器。
需要注意到,这个 Caravel 容器里的默认鉴权配置是:
username: admin
password: caravel_admin
在线Demo
下面我提供了Caravel的一个在线Demo:
http://52.33.104.157:8088/login/
下面是仪表盘的交互式分析页面:

我们可以导出JSON、CSV文件、直接得到SQL语句甚至分享页面链接。
下面是全球人口的一个分析仪表盘,感觉再改动一下就可以做信息图了,大数据分析也不在话下。
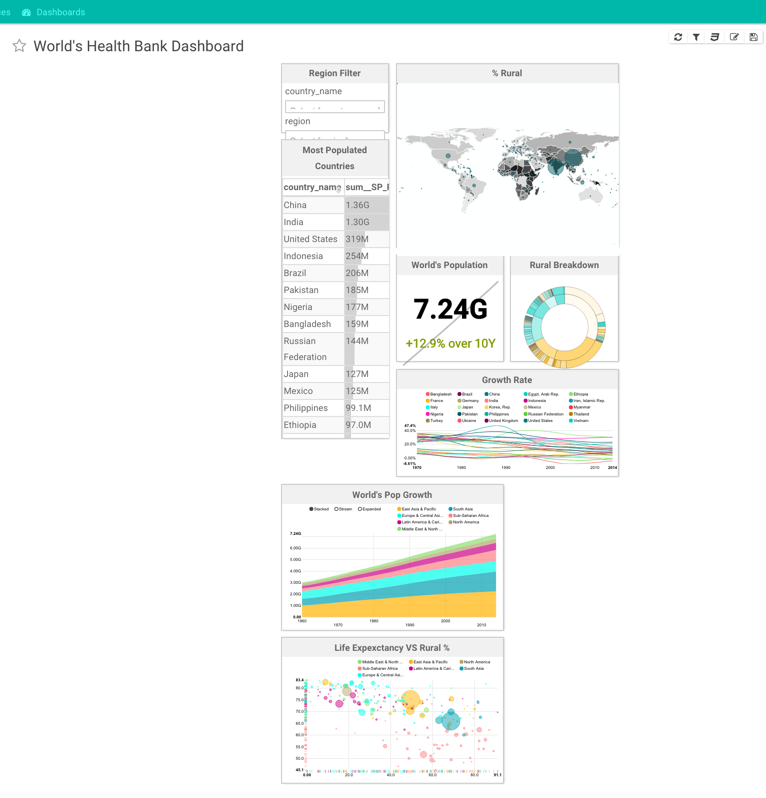
下面是我最喜欢的sankey chart:[br]
架构
看到如此惊艳的数据产品,想必你也很想自己动手做一个吧!让我们一起看看整体的架构。
后端
整个项目的后端是基于Python的,用到了Flask、Pandas、SqlAlchemy。
Flask AppBuilder(鉴权、CRUD、规则)
Pandas(分析)
SqlAlchemy(数据库ORM)
此外,也关注到Caravel的缓存机制值得我们学习:
采用memcache和Redis作为缓存
级联超时配置
UI具有时效性控制
允许强制刷新
前端
自然前端是JS的天下,用到了npm、react、webpack,这意味着你可以在手机也可以流畅使用。
d3 (数据可视化)
nvd3.org(可重用图表)
局限性
Caravel的可视化,目前只支持每次可视化一张表,对于多表join的情况还无能为力
依赖于数据库的快速响应,如果数据库本身太慢Caravel也没什么办法
语义层的封装还需要完善,因为druid原生只支持部分sql。
参考资料
Caravel GitHub地址
推荐镜像 kochalex/caravel
知乎:presto、druid、sparkSQL、kylin的对比分析,如性能、架构等,有什么异同?
推荐产品
- 神策分析:数据分析平台的私有化部署方案
神策目前提供私有化的数据分析平台解决方案,根据桑老师的说法,现在考虑到安全性的问题,还没有做到Docker部署,只能远程部署(大概半个小时),这里有一丝淡淡的遗憾。
作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者 Harry Zhu 的 FinanceR专栏:https://segmentfault.com/blog/harryprince,如果涉及源代码请注明GitHub地址:https://github.com/harryprince。微信号: harryzhustudio[br]商业使用请联系作者。
关键字:etl, Python, caravel, 数据
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
