AI应用实例分析——文本纠错
前面跟大家分享了AI开放平台的相关内容,之后想围绕AI应用实例这块跟大家分享交流,这节主要讲述跟NLP相关的一个应用实例——“文本纠错”。
一、背景
虽然这几年短视频在内容传播方面发展得很火,但是文稿仍然占据重要地位。而文稿传播最重要的一点就是信息的准确性,尤其是一些有知名度的正式平台更是会在文稿发送前进行校对修正。
传统的人工校对工作量是非常大的,一篇5000字的文稿完成校对差不多需要1-2个小时,对于校稿人员来说既耗时又枯燥。有一家内容平台就提出,希望我们通过AI能力提供快速校对工具,主要针对中文文稿,帮助校稿人员和编辑人员减少内容错误。
为了满足该需求,我们基于NLP技术提供了文本纠错服务。
二、关键技术
文本纠错中用到的技术的前世今生在这不过多介绍了,目前文本纠错的主流方向还是使用机器学习的方式来完成,其中需要用到的核心技术主要包括语言知识学习、上下文理解和知识计算。
- 语言知识学习:可以理解为是对语言规则等先验知识的学习,通过学习词法、句法等规则进行语言模型构建,例如中英文的主谓宾结构就是不一样的。
- 上下文理解:是指分析错误点上下文语境和语义,从纠错候选中选择最合适的。尤其是中文,相同的词汇在不同语境中往往表达不同的含义。
- 知识计算:知识计算主要包括关联知识计算和文本理解,关联知识主要是通过对全局知识的统计来实现纠错,可以是局部不完整语句的补充。文本理解是通过统计理解全局句子内容,解决低频领域知识的泛化问题。
三、产品设计
1. 应用场景
(1)用户场景:审稿或者编辑人员输入中文文字信息,系统自动纠错,并给出修改建议,审稿人员对错误快速修订。
(2)应用边界:
- 支持用词错误检测,针对音近、形近的错字和别字进行纠正
- 支持句子级错误检测,主要是针对句子中出现的多字、少字等错误,相对难度校大。
- 支持场景类错误纠正,这类错误需要具备一些特定领域的知识才能识别纠错,所以尽量支持。
2. 产品定位
- 产品定位:为应用工具型产品,实现中文文本自动纠错功能。
- 用户定位:满足两类B端用户,第一类针对具备自主的文稿编辑工具,提供API服务,与现有系统进行改造融合;第二类是针对缺少文稿编辑工具的用户,提供web页面功能。
3. 产品业务流程
产品核心业务流程主要是产品端和算法端的交互,具体业务流程如下:
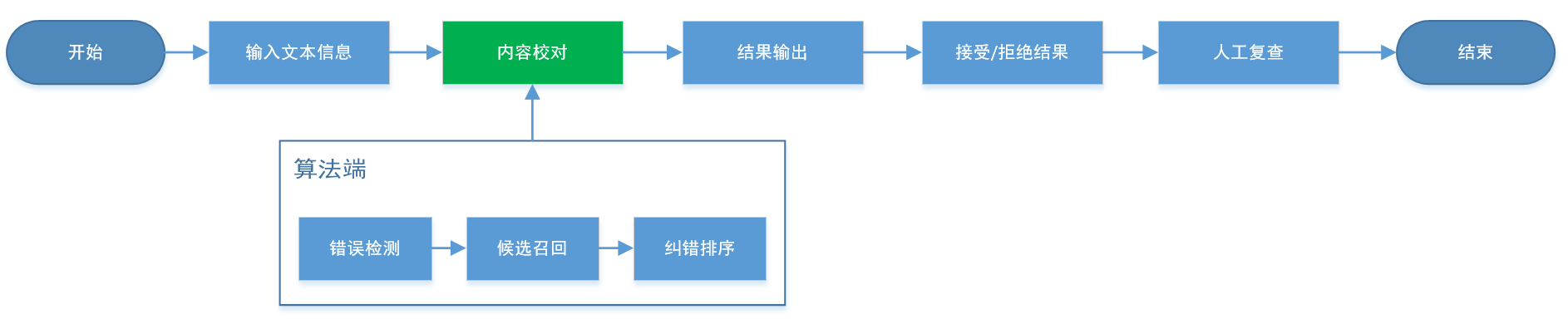
4. 产品功能设计
(1)页面功能设计
页面核心功能主要包括如下:支持内容上传、内容审查、结果确认和内容下载。

主要页面设计如下:
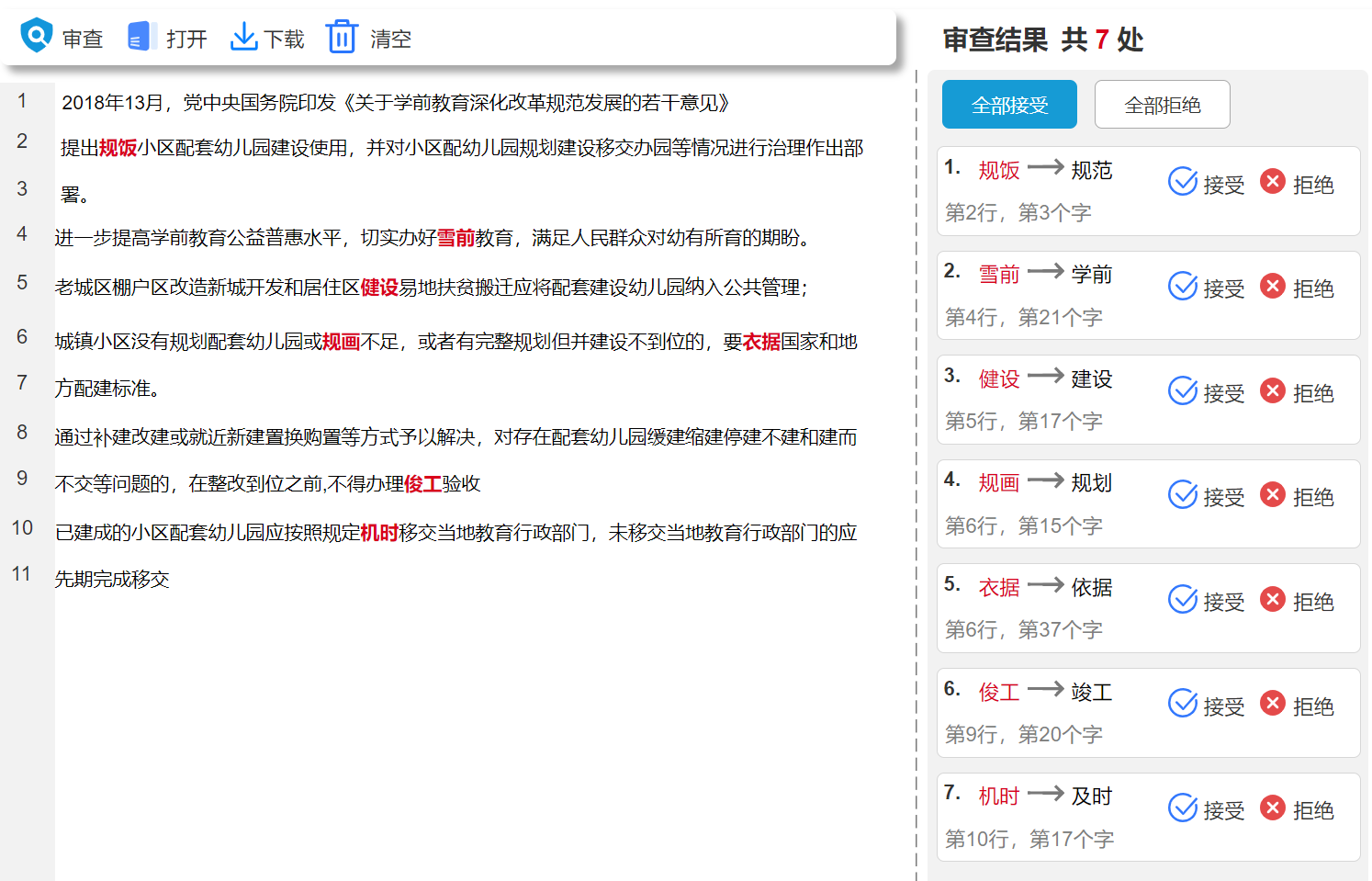
(2)API接口设计
包括内容纠错请求接口和结果回调接,分别用于内容审查纠错和结果返回,以下描述主要的输入和输出参数:
- 输入:接口鉴权、文本内容、文本编码格式等。
- 输出:文本分析结果,包括源文本、纠错文本、文本位置,置信度。
5. 评估指标
产品上线前,需要对产品的性能进行评估,主要包括三个指标:误报率、召回率和处理时间。
- 误报率:代表正确的句子被改错的比率,等于正确句子被纠错的个数/正确句子的个数。
- 召回率:代表错误的句子被全部纠正的比率,等于含有错误的句子被改正的数量/所有含错误的句子数量。
- 处理性能:代表处理多少个字符的耗时,单位是千字耗时,s/千字符。
四、结论
文本纠错是NLP非常基础的场景应用,但是实际业务价值却是很大的。在具体业务场景应用方面不仅可以用在在媒体编辑、电子病历等输入文本纠错,还可以应用于语音搜索、客服问答等业务。
本文作者@Eric_d
题图来自 Unsplash,基于CC0协议
作者
Eric_d。关注AI、大数据等领域,擅长需求分析、产品流程和架构设计等,日常喜欢徒步。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
