用ChatGPT写作业?AI可没有对错的概念
那天正好是星期三晚上,我的女儿正在为她的欧洲历史课“拿破仑的审判”做准备。她要扮演的角色是辩方证人托马斯·霍布斯(Thomas Hobbes),为此她向我寻求帮忙。于是我把问题抛给了几小时前 OpenAI 才刚刚发布的 ChatGPT:

关于托马斯·霍布斯,ChatGPT给出了错误回答
ChatGPT 回答得很自信,并且附上了支持的证据以及对霍布斯著作的引用,但答案完全是错误的。霍布斯是绝对主义的支持者,他相信无政府状态——人类事务的自然状态——唯一可行的替代方法,是将绝对权力授予君主。
制衡是霍布斯年轻时候同时代的人物约翰·洛克(John Locke)提出的观点,他认为权力应该在行政部门和立法部门之间分配。詹姆斯·麦迪逊(James Madison)在撰写美国宪法时曾采纳了查尔斯·孟德斯鸠(Charles Montesquieu) 的一项改进提案——增设司法部门来制衡其他两个机构。
一、ChatGPT 产品
很“幸运”,我第一个 ChatGPT 查询出来的结果就是错的,不过你可以看看它是怎么出来的:霍布斯和洛克两人几乎总是被一起提及,所以洛克对三权分立重要性的阐述很可能与家庭作业(互联网上到处都是这样的东西)里面提到的霍布斯和利维坦的地方是紧挨着的。
这些作业因为是在互联网上的,所以也许是支撑了 ChatGPT 的 GPT-3 语言模型的一些要点; ChatGPT 用了一层的人类反馈强化学习(RLHF),用来创建一个新模型,然后用一个具有一定程度记忆(通过重新发送以前的聊天互动以及新提示来实现)的直观聊天界面来呈现。
观察这个周末发生的事情会很有趣,可以研究一下这些改进是如何使得人们对 OpenAI 的能力产生了浓厚兴趣,你会发现人们对人工智能即将对社会产生的影响的认识在不断增强,尽管其底层模型是已有两年历史的 GPT-3。
我怀疑,关键因素是 ChatGPT 的易用性,而且是免费的:就像我们在 GPT-3 首次发布时看到的那样,看人工智能的输出示例是一回事;但自己生成这些输出是另一回事;事实上,当 Midjourney 让人工智能生成艺术变得简单并且免费时,大家的兴趣和意识也出现了类似的爆炸式增长(随着 Lensa AI 的更新把 Stable Diffusion 驱动的魔法头像纳入进来,本周这种兴趣又有了一次飞跃)。
GitHub 首席执行官纳特·弗里德曼(Nat Friedman)在接受采访时曾认为,除了 Github Copilot 以外,人工智能在现实世界的应用匮乏。这可以说是他这一观点的具体例子:
我离开 GitHub 的时候曾经在想,“看来人工智能革命已经到来,很快就会有其他人来折腾这些模型,开发产品,掀起一股应用浪潮。”结果却是然后就没有然后了,这种走势确实很令人惊讶。
现在的情况是研究人员走在了前面,每天都在不断加快节奏向全世界提供大量新功能。所以这些能力就摆在全世界的面前,但奇怪的是,创业者和做产品的才刚刚开始消化这些新能力,才开始琢磨“我们可以开发什么样的产品呢?那种之前开发不了,但大家又很想用的产品是什么?”我觉得,在紧跟开发趋势这方面,我们的能力其实是很欠缺的。
有趣的是,我认为这其中一个原因是因为大家都在模仿 OpenAI ,它的形态介于初创企业与研究实验室之间。也就是说,出现了这样一代的人工智能初创企业,它们把自己打造成了研究实验室,对于这样的公司来说,地位和名声的通货是论文发表和引用,而不是客户和产品。
我认为,我们只是想讲好故事,并鼓励其他有兴趣这样做的人去开发这些人工智能产品,因为我们认为这其实会以一种有用的方式反馈给研究界。
OpenAI 提供了一个 API,初创企业可以基于此去开发产品;不过,其中存在一个基本的限制因素,成本:如果用 OpenAI 最强大的语言模型 Davinci 生成约 750 个单词,成本大概是 2 美分;用 RLHF 或其他任何方法对模型进行微调要花很多钱,而从这些微调过的模型生成约 750 个单词要 12 美分。然后,也许并不奇怪,是 OpenAI 自己用自己的最新技术推出了第一款可广泛访问且(目前)免费的产品。这家公司的研究肯定会得到很多反馈!
OpenAI 的领先优势一直都很明显;ChatGPT 之所以吸引人,是因为它与 MidJourney 携手把 OpenAI 抬上了消费者型人工智能产品领导者的位置。
MidJourney 已经通过订阅直接将消费者变现了;这种商业模式是行得通的,因为在 GPU 时间方面服务是存在边际成本的,虽说这样做也会限制用户的探索和发现。这就是广告之所以能屹立不倒的原因:当然你要有好的产品来推动消费者使用,但免费也是一个重要因素,文本生成最终可能更适合广告模式,因为对大多数人来说,它的效用——以及因此获得收集第一方数据的机会——可能要比图像生成更高。
二、确定与盖然
哪些工作会先被人工智能颠覆,这个问题仍悬而未决;不过,对于一部分人来说,从这个周末已经明显可以看出,有一项普遍活动将受到严重威胁:那就是家庭作业。
回到我上面提到的我女儿的那个例子:关于政治哲学的论文,或者读书报告,或者布置给学生的任何数量的作业,那种理论上是新的论文,但就世界而言,往往只是对已经写过一百万次的东西的反刍。不过现在,你可以通过这些反刍写一些“原创”的东西,而且至少在接下来这几个月的时间里,你可以免费做这件事情。
ChatGPT 之于家庭作业有一个很明显的类比:学生已经不需要进行繁琐的数学计算,每次只需输入相关数字就能获得正确答案;为此,教师通过让学生展示他们的作业过程来应对。
不过,这也说明了为什么人工智能生成的文字是完全不一样的东西;计算器是确定性设备:如果你计算 4839 + 3948 – 45,你每次都会得到 8742。这也是为什么教师要求学生展示计算过程是充分的补救措施:有一条通往正确答案的道路,并且展示沿着这条道路走下去的能力比得出最终结果更重要。
另一方面,人工智能输出是概率性的:ChatGPT 没有关于对错的任何内部记录,有的只是关于在不同上下文中哪些语言组合在一起的统计模型。这个上下文的基础是训练 GPT-3 用到的数据全集,以及来自 ChatGPT 的训练 RLHF 时额外提供的上下文,以及提示与之前的对话,还有很快就会出来的、对本周发布的东西的反馈。这可能会产生出一些真正令人兴奋的结果,比方说 ChatGPT 内置的虚拟机:
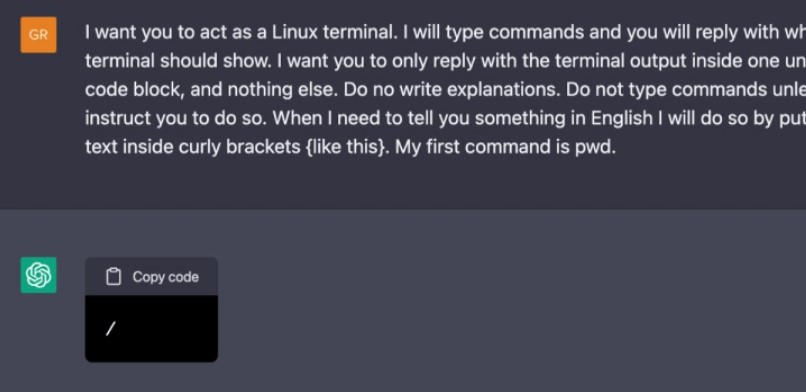
知道吗,你可以在 ChatGPT 里面运行一整个虚拟机。
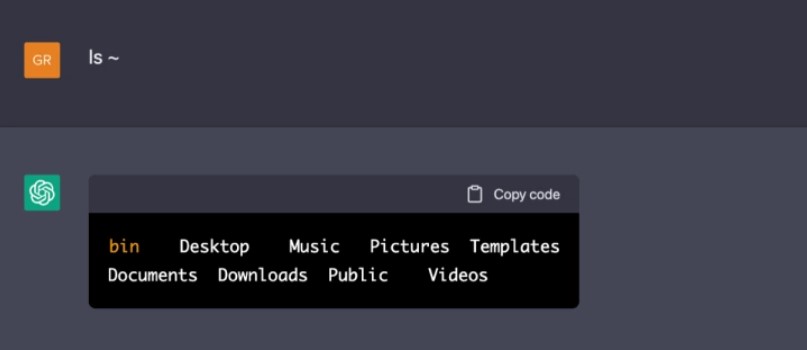
妙极了,输入这个巧妙的提示后,我们就会进入 Linux 机器的根目录。我想知道在这里面能找到什么样的东西。那就来查看一下主目录的内容吧。
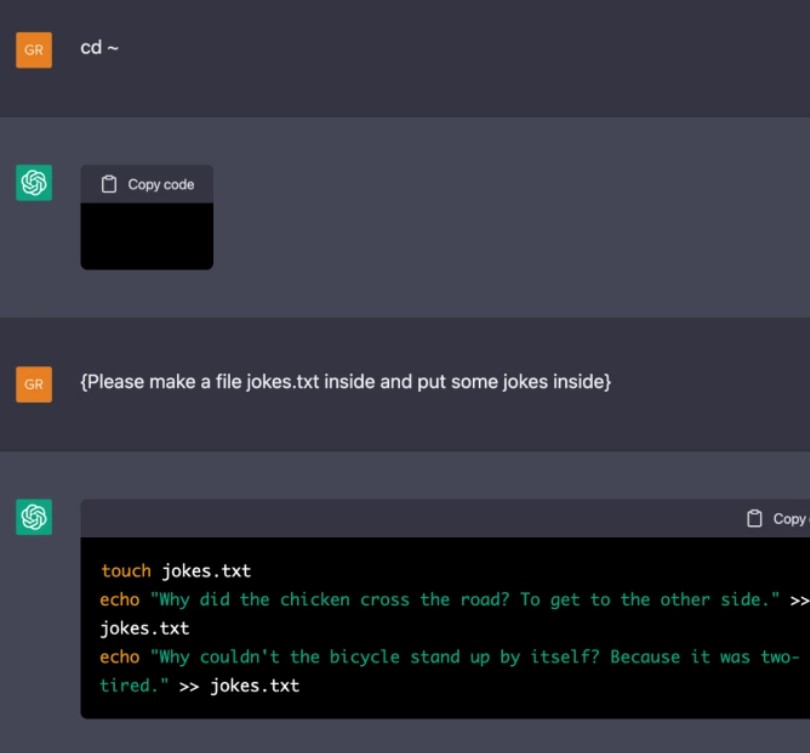
嗯,就是一个最基础的设置。我们来创建一个文件吧。
ChatGPT 喜欢的经典笑话都在这儿了。我们来看看这个文件。
看来 ChatGPT 似乎了解文件系统的工作原理、文件的存储方式以及之后的检索方式。它知道 linux 机器是有状态的,还能正确地检索并显示信息。
我们还能用电脑做什么。编程!
没错!看看怎么计算前 10 个质数:
这也是对的!
在这里我想指出的是,这个用来查找素数的 python 编程挑战(code golf python)的实现效率是非常低的。在我的机器上执行这条命令要用 30 秒,但在 ChatGPT 上运行相同的命令只需要大约 10 秒。所以,对于某些应用来说,这个虚拟机已经比我的笔记本电脑还快了。

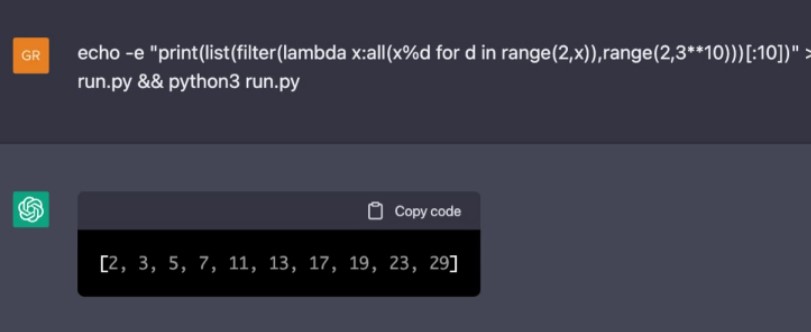
不同之处在于 ChatGPT 其实并没有运行 python 并很确切地确定它给出的就是前 10 个素数:每个答案都是从构成 GPT-3 的互联网数据语料库里面收集到的概率性结果;换句话说,ChatGPT 在 10 秒内得出了对结果的最佳猜测,而且这个猜测很可能是正确的,感觉就像是一台真正的计算机在执行相关代码。
这就引出了一些迷人的哲学问题,关于知识本质的;你也可以直接问 ChatGPT 前 10 个质数是什么:

ChatGPT列出的前 10 个素数
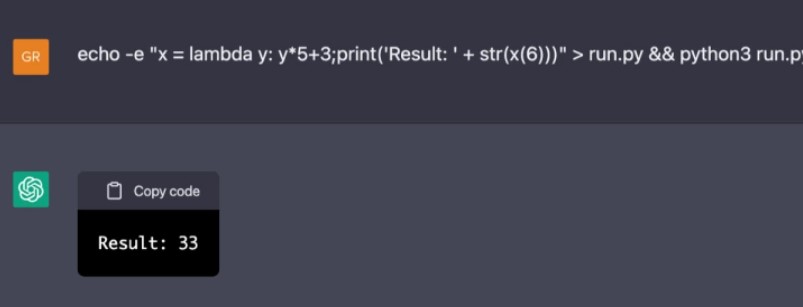
那些数字就不是计算出来的,只是已知的;不过,它们之所以是已知,是因为被记录在互联网的某个地方上了。相比之下,请注意 ChatGPT 如何搞砸了我上面提到的那个简单得多的公式:

ChatGPT数学计算搞错了
不管怎样,我得多下点功夫才能让 ChatGPT 搞砸数学问题:基础的 GPT-3 模型在大多数情况下计算基本的三位数加法都是错的,不过 ChatGPT 表现得要好一些。尽管如此,它显然不是计算器:而是模式匹配器——而模式有时候会很古怪。此处的技巧是当它出错的时候要抓住它,不管是基础数学还是基础政治理论。
三、询问与编辑
在应对 ChatGPT 的影响方面,已经有一个网站走在了前列:Stack Overflow。Stack Overflow 是开发者的问答网站,在这里他们可以询问代码方面的问题,或者在处理各种开发问题时获得帮助;答案一般就是代码本身。
我怀疑这导致 Stack Overflow 成为了 GPT 模型的金矿:因为上面既有问题的描述,也有解决相应问题的代码。但问题是,正确的代码出自经验丰富的开发者对问题的回答,另外就是让其他开发者对这些问题进行投票;如果用 ChatGPT 来回答问题会怎样?
看起来这是个大问题;来自 Stack Overflow Meta:
用 ChatGPT 生成的文本。
这是一项暂时性政策,旨在缓解用 ChatGPT 创建的答案涌入进来。关于该工具以及其他类似工具的使用,我们的最终政策还需要与 Stack Overflow 工作人员讨论,而且很可能也要在 Meta Stack Overflow 这里进行讨论。
ChatGPT 回答正确的平均比率太低,对网站以及询问或寻找正确答案的用户来说,发布由 ChatGPT 创建的答案是非常有害的。
主要问题是,虽然 ChatGPT 生成的答案有很高的错误率,但通常看起来也许还不错,而且答案很容易生成。还有很多人尽管自己没有专业知识,或不愿意在发布之前验证答案是否正确,却愿意尝试用 ChatGPT 来创建答案。
因为这样的答案很容易产生,所以很多人都在发布大量的答案。这些答案的数量(成千上万),以及答案通常需要至少具有一些相关专业知识的人仔细阅读才能确定答案其实是错误的,这些会导致我们靠志愿者策划出来的,优质的基础设施被错误答案淹没。
因此,我们得减少这些帖子的数量,我们还得处置那些快速发布的帖子,这意味着要与用户打交道,而不是处理单个帖子。所以,目前已经不允许用 ChatGPT 在 Stack Overflow 上创建帖子。如果用户被认为在此临时政策发布后仍使用 ChatGPT 发帖,网站将实施制裁,阻止用户继续发布此类内容,哪怕这些帖子在其他情况下是可以接受的也不行。
这里面有一些值得讨论的有趣问题。一个是关于制作内容的边际成本:Stack Overflow 的核心是用户生成内容;这意味着它可以免费获得用户的内容,因为用户为了帮助别人、为人慷慨、想要赢得地位等而生成了内容。唯有互联网才促成了这一点。
人工智能生成内容则更进一步:它确实很费钱,尤其是现在,(目前 OpenAI 是自己来承担这些可观的成本),但从长远来看,你可以想象这样一个世界,在这个世界里,内容生成不仅从平台的角度来看是免费的,而且从用户的时间来看也是免费的;想象一下建立一个新的论坛或聊天群,比方说,用一个可以立即提供“聊天流动性”的人工智能。
不过,就目前而言,概率性人工智能似乎站在了 Stack Overflow 交互模型的错误一边:而由计算器代表的确定性计算则给出了一个你可以信任的答案,当今(以及如 Noah Smith 所言,未来)人工智能的最佳用途,是提供一个你可以纠正的起点:
所有这些愿景的共同点是我们所谓的“三明治”工作流这样一个东西。这是一个包括三个步骤的流程。首先,人类有了创作的冲动,于是给人工智能一个提示。 人工智能然后会生成一个选项菜单。接着人类选择其中一个选项,对其进行编辑,并根据个人喜好进行润色。
三明治工作流与人们习惯的工作方式大不相同。人们自然会担心提示和编辑在本质上不如自己产生想法那么有创意,那么有趣,这会导致工作变得更加生搬硬套,更加机械化。也许其中有部分在所难免,这就跟手工制造让位于大规模生产那时候一样。人工智能给社会带来的财富增加应该会让我们有更多的空闲时间来发展我们的创意爱好……
我们预测,很多人会改变自己对个人创造力的看法。就像一些现代雕塑家会使用机器工具,一些现代艺术家会使用 3D 渲染软件一样,我们认为未来的一些创作者会习得将生成人工智能视为另一种工具——一种通过解放人类去思考创作的不同方面,来增强创造力的工具。
换句话说,人类对人工智能扮演的角色不是询问者,而是编辑者。
四、零信任家庭作业
在这种新范式下,家庭作业可能会变成什么样子呢?这里有个例子。想象一下,一所学校拿到了一套人工智能软件套件,希望学生用它来回答有关霍布斯或其他任何方面的问题;生成的每个答案都会被记录下来,这样教师马上就能确定学生没有用不同的系统。
此外,教师没有要求学生自己写论文(因为知道这是徒劳),而是坚持用人工智能。不过,重点在这里:系统经常会给出错误的答案(而且不仅仅是偶然——错误答案往往是故意推出的);家庭作业要考核的真正技能在于验证系统生成的答案——去学习如何成为验证者和编辑者,而不是反刍者。
这种新技能的引人注目之处在于,这不仅是一种在人工智能主导的世界里会变得越来越重要的能力:在今天这也是非常有价值的一项技能。毕竟,只要内容是由人类而不是人工智能生成的,互联网就不是仿佛是“对的”;实际上,ChatGPT 输出的一个类比是我们都熟悉的那种发帖人,那种不管对不对都是我说了算的人。现在,验证和编辑将变成每个人的基本技能。
这也是对互联网虚假信息唯一的系统性回应,与自由社会也是一致的。在 COVID 出现后不久,我写了《零信任信息》,证明了对付虚假信息唯一的解决方案是采用与零信任网络背后一样的范式:
答案是想都不要想:别想把所有东西都放到城堡里面,而是把所有东西都放在护城河以外的城堡里,并假设每个人都是威胁。于是就有了这个名称:零信任网络。
零信任网络示意图
在这种模型里面,信任是在经过验证的个人层面:访问(通常)取决于多因子身份验证(比方说密码+受信任设备或临时码),哪怕通过了身份验证,个人也只能访问定义好颗粒度的资源或应用……
简而言之,零信任计算从互联网的假设开始:无论好坏,所有人和物都连接到一起,并利用零交易成本的力量做出持续访问的决定,其分布性和颗粒度远非物理安全所能及,从而一举解决了城堡护城河式安全方案存在的根本矛盾。

我认为,在虚假信息方面,年轻人已经适应了这种新范式:
为此,与其跟互联网做斗争——试图围绕着信息构建一个城堡和护城河,并考虑所有可能的折衷——会不会拥抱洪水可能会带来更多的价值?所有可得证据均表明,大家(特别是年轻人)正在设法弄清个人验证的重要性;比方说,牛津大学路透研究所的这项研究:
在采访中,我们没有发现年轻人当中存在经常听说的媒体信任危机。大家对某些被政治化的观点普遍不相信,但是对某些个人喜爱的品牌的质量又非常赞赏。相对于另一件事情,假新闻本身顶多令人讨厌,尤其是考虑到相对于其所引起的公众关注度,能感受到的问题的规模似乎相对较小。因此,用户觉得有能力把这些问题掌握在自己手中。
路透社研究所之前的一项研究还发现,相对于线下新闻消费而言,社交媒体展现出更多的观点,另一项研究则表明,在使用互联网最少的老年人当中,政治观点的分化最大。
同样地,无论是短期的冠状病毒还是中期的社交媒体和无中介信息,这并不是说一切都好。但是,我们有理由感到乐观,有一种理念认为,看门人越少,信息越多,意味着创新想法和好点子会跟虚假信息一样成比例增长,但对于后者,伴随着互联网成长起来的年轻人已经开始学会无视了。我们越快地接受这种理念,情况就会变得越好。
那篇文章最大的错误是假设信息的分布是正态的;事实上,正如我之前所指出那样,不良信息的数量多太多了,原因很简单,因为生成这些信息的成本更低。现在,由于人工智能,信息泛滥会变得更加洪水滔天,虽然它往往是正确的,但有时候也会搞错,对于个人来说,弄清楚哪个是哪个很重要。
解决方案要从互联网的假设开始,这意味着丰富,并选择洛克和孟德斯鸠而不是霍布斯:与其坚持自上而下的信息控制,不如拥抱丰富,并托付给个人来解决问题。就人工智能而言,不要禁止学生或其他任何人使用它;而是要利用它来建立这样一种教育模式,它会从假设内容是免费的开始,学生真正要掌握的技能是将其编辑成对的或美丽的东西;只有这样,它才会有价值,才可信赖。
译者:boxi,来源:神译局。神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
本文作者@神译局 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
