数据分析流程这么长,产品经理如何一人搞定?
我2002年入行,那个时候还没有“产品经理”这个词,我的主要工作是为业务部门跑数据并且制作报表,就是传说中“跑数据”、“做报表”的那个苦逼数据仓库工程师。
2007年之前我一直在为制造型 企业 建数据仓库,直到去了美国的之后,才开始进入到互联网,服务过两家公司,Linkedin 4年和 eBay 3年多。天天和产品经理、数据分析师在一起,帮助他们准备需要的数据、分析产品和用户,最后把分析的结果做到产品里面去。走上了数据采集 - 处理 - 清洗 - 展现 - 分析 - 数据产品的道路。
一个互联网公司要做好 Growth,就要做好产品体验。想要做好产品体验,产品经理第一需要的就是数据分析支持,有了数据才能开始Growth Hacker…此处省去10000字关于 Growth Hacker。
1.产品经理关注的是用户体验
对于产品经理而言,他们关心的是什么呢?产品经理对网站或者是 APP 的 UI 、UX 是最熟悉的,因为他们参与了其中的设计:用户应该怎么交互,有哪些交互上面不方便的地方,每一级菜单用户交互的流程,交互上的死角和边界;然后是设计,UI 是不是够简洁,美观,吸引人?哪些链接需要加强用户关注度,哪些链接需要减低用户的关注度。总而言之,都是为了用户体验,好的用户体验才能带来用户活跃,提高增长。
比如网页端( APP 端同理):
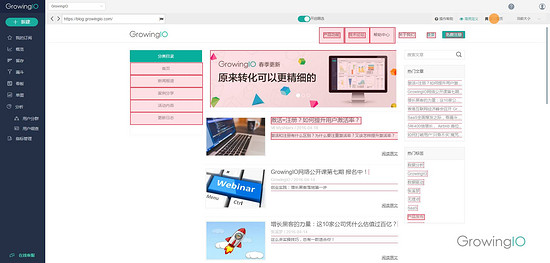
在GrowingIO圈选以查看相关数据
2.分析师的报表为产品经理提供数据支持
一个合格的 数据分析 师要能够制作可视化的报表,能够用不同的图形表达分析的结果。比如下面的可视化报表:
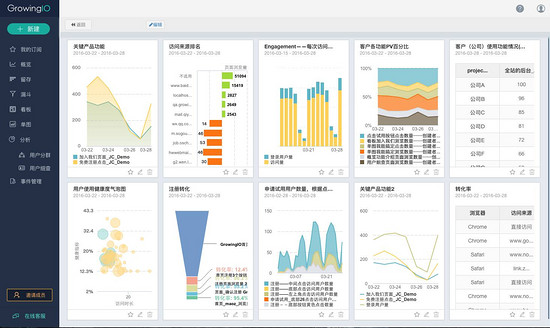
GrowingIO一目了然的数据看板
分析师构建报表的数据从哪里来呢?在数据库。
数据库里面有成百上千种表,一个合格的数据分析师首要的是知道数据在哪里?存在哪些表里面:
“哪里有页面浏览的表,哪里有搜索的表,哪里有广告的展现,点击的表,哪里有手机用户事件的表,哪里有用户属性的表,这些表每个字段对应了哪些维度和指标,哪里有宏观的已经计算好的指标,哪里有微观的详细的用户事件,还有很多过滤条件等等。”
对于一个刚入职的分析师,即使是有专人带的情况下,也是需要一定的时间才能成长的,不然很可能提供了错误的数据,导致了错误的决策。
如下图是数据分析师们熟悉的数据库结构,可以帮助他们迅速的找到表的定义和字段的定义:
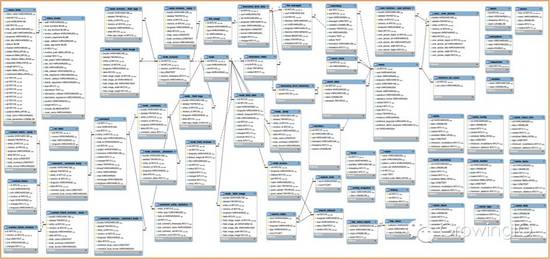
数据工程师设计并构建了上面的数据库模型,同时他们也要负责源源不断的把数据插入到这些数据库的表中,这些数据可以存在数据库里面,也可以存在 Hadoop 的数据集群中。
3.依赖专职数据工程师的繁琐流程
可是数据库里面存了所有我们能够支持数据分析师的数据吗? 当分析师在数据库里面找不到数据的时候,就需要数据工程师需要从各种地方重新调取(此处省略关于实时数据流,Hadoop 集群,ETL,数据聚合等等关于技术的10000字)。
总之如果要得到没有事先收集的用户行为事件数据,就要在前端的代码里面埋事件代码,也就是在用户事件产生的源头埋点,才能在服务端得到相应的日志数据。
在技术上 Linkedin 为互联网日志做出了贡献,开源了 Kafka。什么是 kafka?就是可以非常实时的接受客户端发过来的实时事件数据并生成日志数据,然后发送到后端服务器上。比如腾讯,今日头条,新浪等等互联网公司都用 Kafka 收集日志的。
日志是这个样子的:
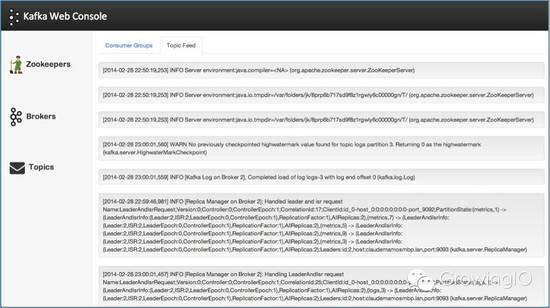
以上的这些都是数据,不同的人看到的角度是不同的。如下图:

从工程的角度出发,数据处理的顺序是这样的:
第一步:先埋点
第二步:收集日志
第三步:建立数据库
第四步:分析数据
第五步:得出产品经理要的分析结果
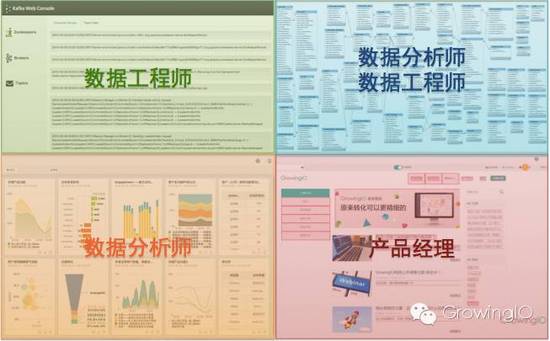
4.产品经理借助数据分析工具可独立完成
看起来这个链条很长,但是GrowingIO可以把它缩短,如何缩短?在一开始就从产品经理的角度来看这个问题。
从产品经理的角度出发,数据处理的顺序是这样的:
第一步:产品经理直接圈选,看数据结果。
在保存了用户事件之后,还可以自由的创造看板。如下图
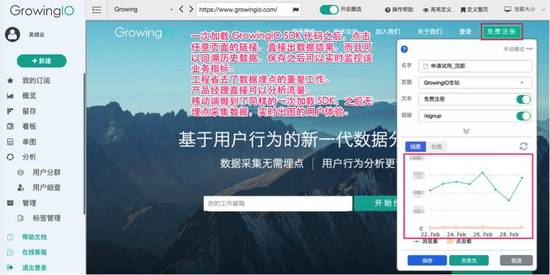
产品经理和数据分析师可以在很短的时间能创建出看板,从事件的定义到产生分析结果,只要短短几秒钟,而且还追溯了过去7天的历史数据。
不仅仅如此,GrowingIO 还提供用户分群、用户细查、事件留存和数据下载等高级功能。
我们现在通过云端软件服务形式,制作了一个简单容易上手的系统,可以让初创公司快速地,低成本地获得只有大公司才玩得起的实时 大数据分析 系统。
本文作者:吴继业,GrowingIO联合创始人,前LinkedIn分析工程技术总监。
关键字:产品经理, 数据
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
