策略产品经理必读系列—第二讲AA & AB Test最全介绍
一、综述AA 和 AB Test实验
实验机制其实一共是有两种的,AB Test和AA Test。
AB Test:
A为实验组,B为对照组。A对比B得出本次实验的效果结论。很多文章说AB Test只能是单一实验变量,其实AB Test也可以有多变量。
比如在推荐系统里分别优化了一版召回模型 + 排序模型。希望同时观察这两个模型叠加后的效果,那么实验组就会存在两个变量,对照组就为原先的召回+排序模型。当然这种情况比较少见,如果两个变量CD之间会相互产生影响,一般是第一个变量C先做AB Test实验,确定效果正向后,将实验全量后再对第二个变量D进行AB Test实验。两个变量叠加在一起很难去分别评估每个变量对实验效果造成的影响。
AA Test:
除了AB实验,其实还有AA实验。
AA实验就是实验组和对照组的实验配置完全一样,主要为了测试本次实验效果的波动性。在保证AA实验随机分流的情况下,理论上AA实验效果之间的差异应该是很小的,但如果实验效果差异很大,说明本次实验变量本身的效果波动就较大,原先AB 实验的效果也不够置信。
不过现实中我们很少做AA实验,当我们发现AB实验效果比较波动时一般的做法就是多观察一段时间,等待实验效果稳定。如果长时间试验效果还是很波动,就需要确定实验分流是否存在问题,正常一个变量只要不是随机产生结果,实验效果一定是稳定的,不管是稳定正向还是负向。
同时AB Test实验确定A实验效果正向后,我们会将A实验策略在线上推全,但仍然会在线上再保留一个对照组继续观察一段时间,比如推全的流量是95%,剩余5%再继续作为对照组持续观察一段时间,这种一般叫做“Hold Back”。因为AB Test实验阶段一般都是小流量实验,A组5%流量,B组5%流量。我们需要再观察一下在大流量的情况下A组的实验效果是否仍然和小流量实验时一致。
二、AB Test实验完整机制
下面我们详细地介绍AB Test实验的每一个步骤。
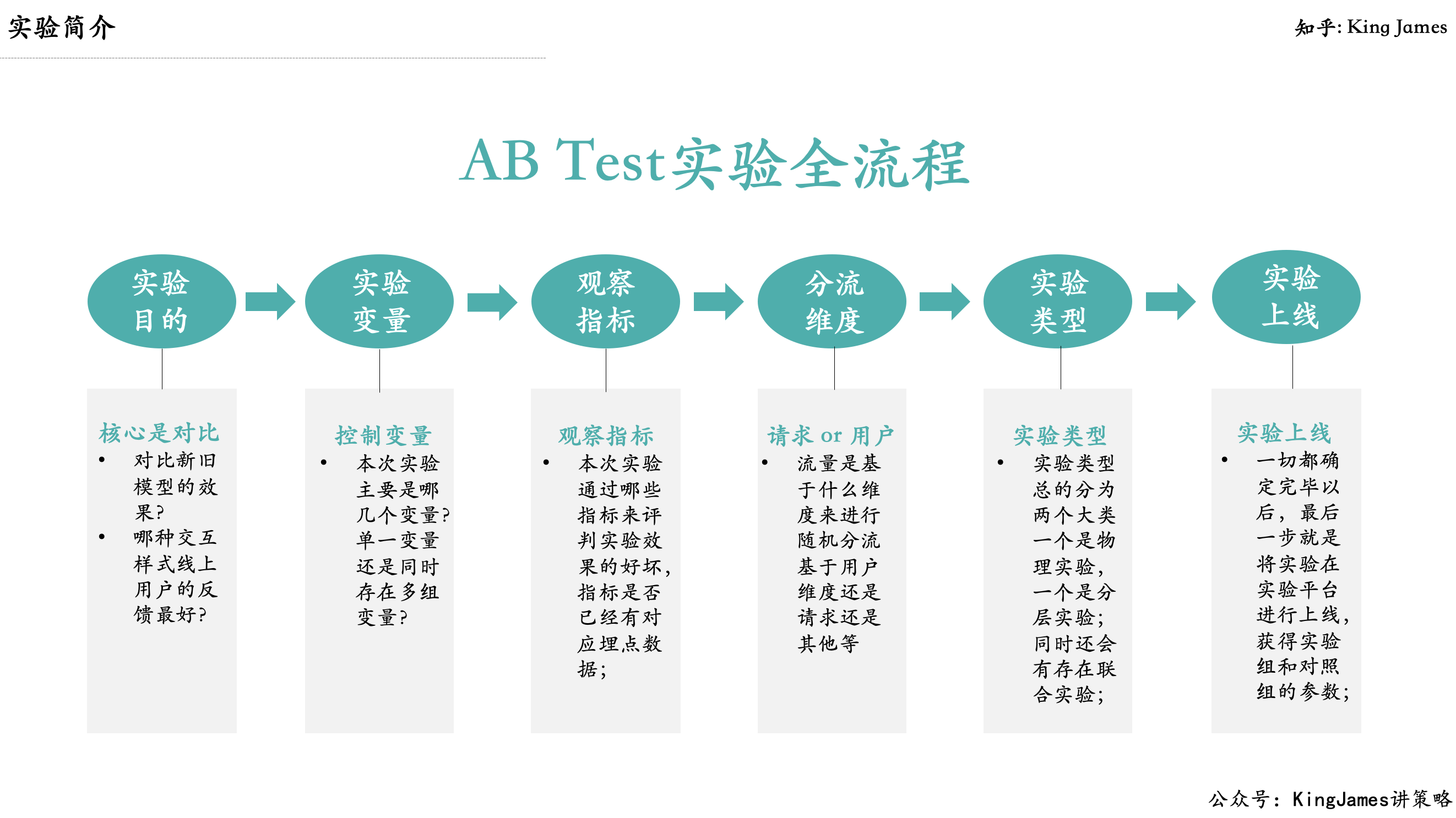
2.1 第一步确定实验目的
做实验一定有目的,我们本次做实验的目的是什么?是希望验证新模型的对于用户点击效果还是验证新交互样式的对于用户停留时长的效果?目的明确了才能决定后续的实验变量、观察指标、分流维度和实验类型以及如何综合评估实验的效果。
2.2 第二步确定实验变量
实验目的明确后也就确定了实验的变量,本次实验是希望只观察推荐系统里新召回模型的效果,那么实验组A就是新召回模型,实验组B就是老召回模型。元气森林推出了6款不同口味的新饮料,针对不同口味又有三款不同的容量,以及两款不同的包装样式,元气森林希望测试哪一款最受用户欢迎。
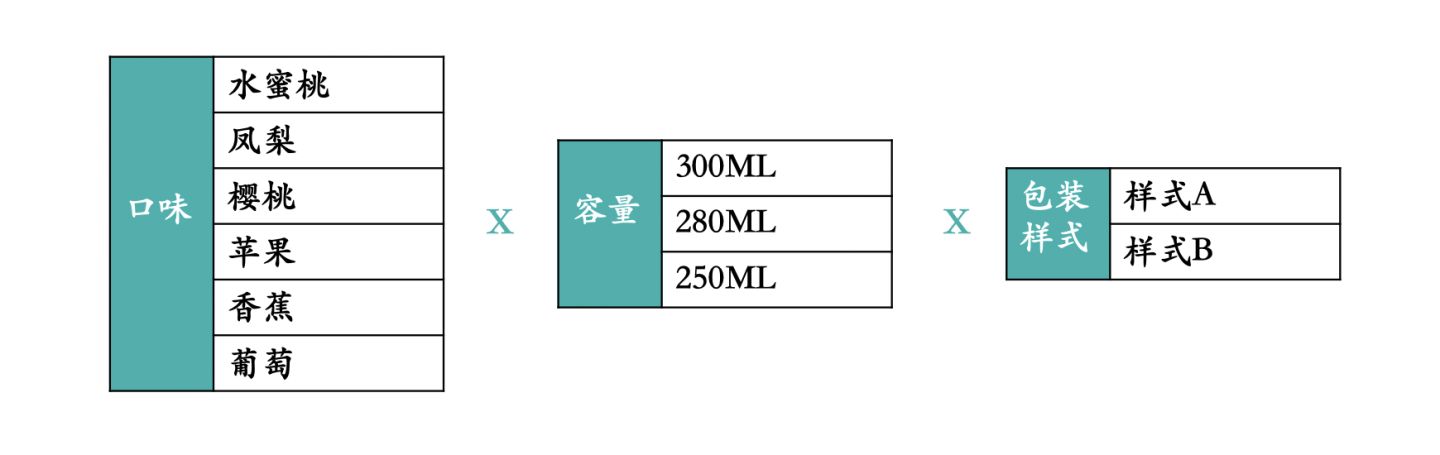
那么在这个实验中就会存在三个变量“口味”、“容量”和“包装样式”,最终就需要 6 * 3 * 2=36 组实验,不需要专门的对照组,每组既是实验组也是其他组的对照组。
2.3 第三步确定实验观察指标
实验目的和变量确定以后下一步就是明确通过哪些指标来衡量实验的效果。比如Part2.2里面测试推荐系统新召回模型的效果,该试验观察的指标主要是点击率CTR,但同时还需要去关注用户浏览深度和CVR的变化。所以在实验中我们会有一个核心的观察指标,但也会有很多其他辅助观察指标。
当这些指标之间效果出现反向时,比如新召回模型上线后实验组对比对照组CTR +3%,但浏览深度-0.3%,CVR-1.5%。这时就需要综合评估该模型的效果,一般需要算法拉上业务方综合评估,该推荐场域主要的KPI是CTR还是CVR,或者二者的占比是。最终决定该模型要不要推全量。同时实验观察指标确定以后也需要确保线上有对应的埋点,不然无法统计实验效果。
2.4 第四步确定分流维度
实验组和对照组的流量基于什么来进行随机分流,是基于用户维度还是请求维度。
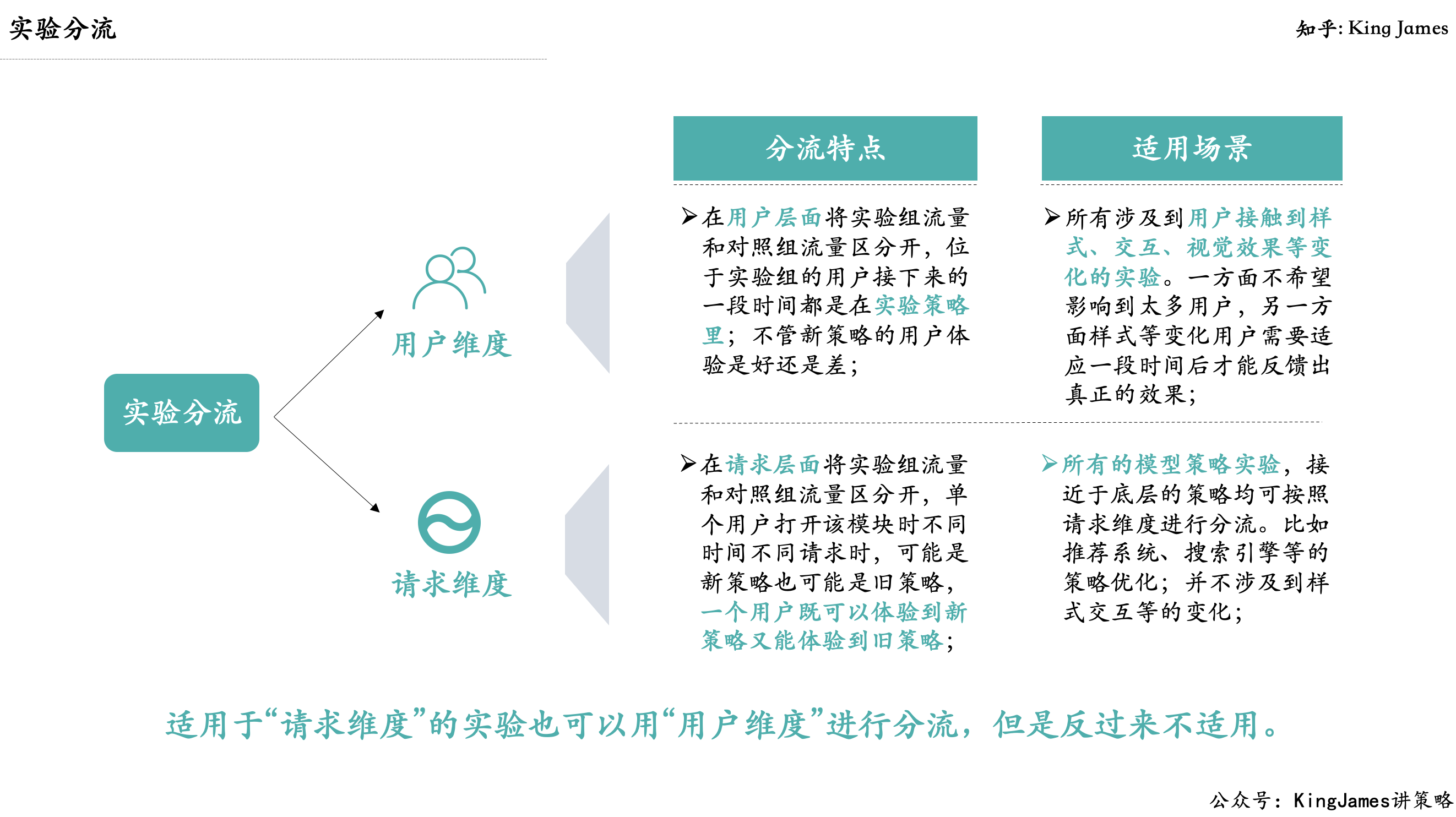
用户维度:
在用户层面将实验组流量和对照组流量区分开,位于实验组的用户接下来的一段时间都是在实验策略里;不管新策略的用户体验是好还是差;
请求维度:
在请求层面将实验组流量和对照组流量区分开,单个用户打开该模块时不同时间不同请求时,可能是新策略也可能是旧策略,一个用户既可以体验到新策略又能体验到旧策略;
两种分流维度决定适用的实验场景不一样:基于用户维度的适用于所有涉及到用户接触到样式、交互、视觉效果等变化的实验。一方面不希望影响到太多用户,另一方面样式等变化用户需要适应一段时间后才能反馈出真正的效果;基于请求维度的适用于所有的模型策略实验,接近于底层的策略均可按照请求维度进行分流。
比如推荐系统、搜索引擎等的策略优化;适用于“请求维度”的实验也可以用“用户维度”进行分流,但是反过来不适用。
这里面还有几个点需要注意:
基于用户维度分流实验中的异常ID:
当我们将X%的用户固定分到实验流量中,如果里面有某些用户ID行为异常活跃,这些异常ID对于实验策略的反馈可能会影响到整体实验效果的评估。
比如某些用户ID一天登陆APP上百次,点击推荐模块上千次,那么这些数据就将会影响到整体效果。当然这种用户ID一般是外部爬虫ID或者作弊ID,需要反作弊部门识别出来剔除掉。还有另外一种处理方式就是将效果进行平均化,计算公式如下图:
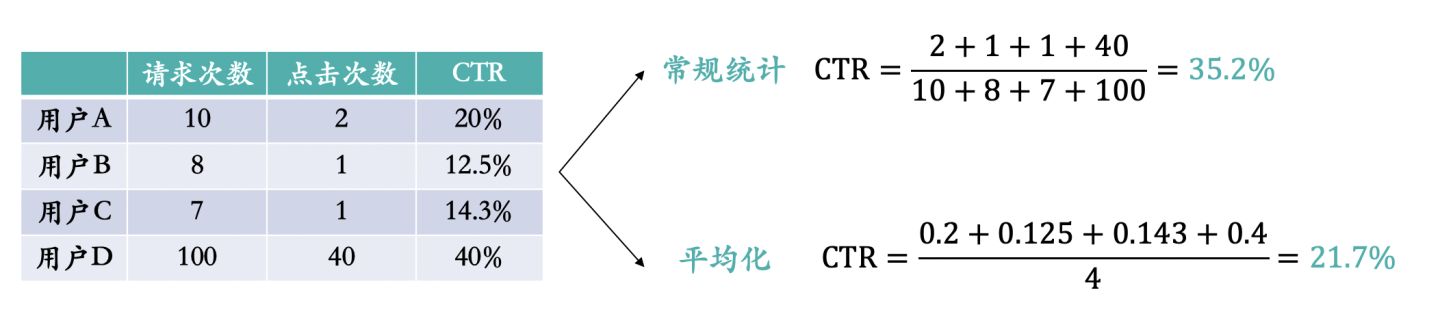
即使经过平均化我们仍然可以发现对于实验效果还是产生了一定影响,当然实验用户量庞大的情况下会对异常值更加稀释。不过这种异常ID最好的方式就是从实验结果中剔除掉。
实验组和对照组的流量比例:
本身实验组和对照组的流量不存在固定比例,或者什么比例是合适的。但是需要保证实验组和对照组的流量都是充分的,实验结果都是置信的。实验组10%流量,对照组1%流量都可以,只要1%流量实验阶段可以积累足够的数据即可。
Hash分桶:
上面一直介绍基于用户和请求维度来分流,那么一个用户或者请求到底是归到实验组里还是对照组里了。一般我们都是基于Hash算法,为每个用户(user-id)或每次请求(request-id)生成一个hash值,然后将位于指定范围的hash值分向一个桶。实验开始前确定哪些桶属于实验组,哪些属于对照组。
2.5 第五步确定实验类型
第五步也是最关键的一步也就是确定实验类型了,实验类型从大的方向来说分为两种:物理实验和分层实验。两种实验对应的是两种分流方式:互斥和正交。我们用下图来表示差异:
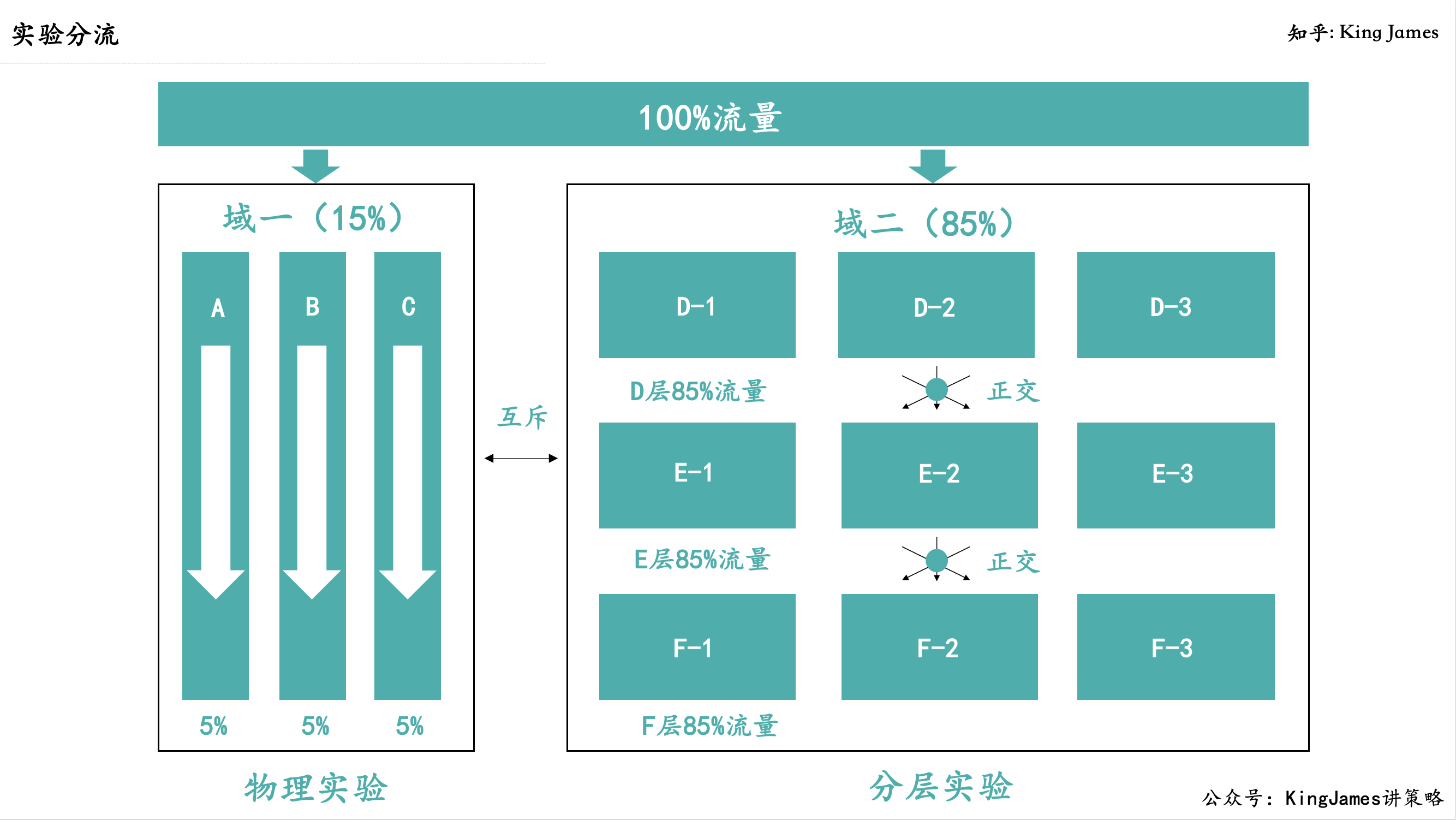
物理实验:
最开始做实验的方式都是物理实验的方式,当一部分被分到了实验A中以后,该部分流量就无法在被其他实验使用,如上图“域一”,实验之间的流量是互斥的,三组实验加起来的流量总和是15%。这种分流方式导致同时线上实验数很有限,如果每组实验5%流量,同时只能做20组实验。但是像淘宝字节这种大公司,同时线上几百上千个实验很正常,这种做实验的方式肯定不满足需求。
分层实验:
谷歌提出了一种新的实验分流方式(原文《Overlapping Experiment Infrastructure:More, Better, Faster Experimentation》):正交。每个独立实验为一层,层与层之间流量是正交的,一份流量穿越每层实验时,都会再次随机打散,如上图“域二”,上一层实验对下一层不会产生任何影响,因为流量被均匀随机打散了,每一层实验的流量都是85%。分层实验的个数理论上是无限的。
联合层实验:
分层实验理论上层与层之间需要将流量随机打散,但有些情况下我们希望将层与层之间的策略联动,比如上图D-1和E-1的策略联动,D-2和E-2的策略联动,D-3和E-3的策略联动,这个时候就需要将D-1实验标签和E-1实验标签关联起来,确保经过D-1的流量全部打到E-1的实验桶里面。
适用场景:
物理实验适用于任何场景,但此种实验方式实验数量上限有限,公司一般会切出部分域专门做物理实验,剩余流量做分层实验。有些场景只能做物理实验,不能和其他实验掺杂在一起,尤其是涉及到系统性能评估等的实验,需要排除一切外在影响确保实验不受任何干扰。分层实验可以同时做大量线上实验,适合那些业务之间彼此独立没有影响的场景,如果层与层之间的实验是有影响的,此种情况建议在同一层进行实验。
2.6 第六步上线实验&查看实验效果
实验上线:
当我们将实验所有准备工作都确定完以后,就是在实验平台上线实验了。实验平台会下发实验组和对照组的实验标签,后续根据该实验标签查看对应实验的效果;
实验观察时长:
正常情况下都需要观察3个工作日左右,尤其对于那种实验效果前期比较波动的需要观察更长的时间。但如果实验效果长期波动不稳定就需要确定实验的分流方式是否存在问题。
以上就是对AA & AB Test的全面介绍,欢迎大家沟通交流~
本文作者 @King James 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
