怎么抓住网络中关键节点
最近在思考团队扩张及项目数量增加的情况下,如何持续保障团队高效产出的问题,很自然的想到了组件化这个话题。重翻了前段时间iOS开发圈关于组件化的讨论,这里做下梳理和自己的思考。
组件化的驱动力
在开始讨论组件化技术方案之前,可以先思考下驱动项目组件化背后的原动力。我们假设这样一个场景,公司有 A,B,C三个项目在appstore运作,三个项目分别由Team A,Team B,Team C开发维护,每个Team由五名工程师组成,其中一名担任小组长,三个Team之上再配备一位Leader,一位架构师。这时,公司决定开辟新的业务领域,成立项目D,并新招了5名工程师来开发。架构师和Leader此时首要工作是选定技术方案,让项目D能又快又稳的启动,同时要规避新工程师磨合期可能引入的副作用。如果之前有过组件化的设计,项目D可以重用之前A,B,C的部分组件,比如【用户登录】,【内存管理】,【日志打点系统】,【个人Profile模块】等等,新成员也可以在已有的codebase基础之上快速上手。如果没有做过组件化的处理,那么要从A,B,C中抽离出诸如【用户登录】的独立模块,会相当的痛苦,高度耦合的代码盘根错节,重用起来费时费力,对团队的人力是浪费,更影响整体的项目进度。我们的目标是重用高度抽象的代码单元。
组件的定义
首先需要对组件进行定义,叫组件也好,模块也罢,我们姑且认为我们讨论的范畴是【独立的业务或者功能单位】。至于这个单位的粒度大小,需要工程师自己把握。当我们写一个类的时候,我们会谨记 高内聚,低耦合 的原则去设计这个类,当涉及多个类之间交互的时候,我们也会运用 SOLID 原则,或者已有的设计模式去优化设计,但在实现完整的业务模块的时候,我们很容易忘记对这个模块去做设计上的思考,粒度越大,越难做出精细稳定的设计,我暂且把这个粒度认为是组件的粒度。 组件是由一个或多个类构成,能完整描述一个业务场景,并能被其他业务场景复用的功能单位 。组件就像是PC时代个人组装电脑时购买的一个个部件,比如内存,硬盘,CPU,显示器等,拿出其中任何一个部件都能被其他的PC所使用。
所以组件可以是个广义上的概念,并不一定是页面跳转,还可以是其他不具备UI属性的服务提供者,比如日志服务,VOIP服务,内存管理服务等等。说白了我们目标是站在更高的维度去封装功能单元。对这些功能单元进行进一步的分类,才能在具体的业务场景下做更合理的设计。按我个人经验可以将组件分为以下几类:
- 带UI属性的独立业务模块。
- 不具备UI属性的独立业务模块。
- 不具备业务场景的功能模块。
第一类是Limboy,Casa讨论较多的组件,这些组件有很具体的业务场景。比如一个App的主页模块,从Server获取列表,并通过controller展示。这类模块一般有个入口Controller,可以通过Push或Present的方式作为入口接入。电商类App的大部分场景都可以归于这一类,Controller作为页面的基本单位和Web Page有很高的相似度,我想这也是为什么蘑菇街会采取URL注册的实现方式,用URL来标记本地的每一个Controller,不仅方便本地的跳转,还能支持Server下发跳转指令,对运营团队来说再合适不过。从理论上来说,组件化和URL本身并没有什么联系,URL只是接入组件的方式之一,这种接入方式还存在一定局限性,比如无法传递像UIImage这类非primitive数据。这种局限性在电商app业务环境下,会带来多少副作用值得商榷,按我的经验,在完整独立的业务模块间传递复杂对象的场景并不多,即使有也可以通过memory cache或者disk cache来做中转。我没记错的话,之前天猫无线客户端不同业务模块间跳转也是通过URL的方式来实现的,有个类似Router的中间类来出来URL的解析及跳转,并没有Mediator去对组件做进一步的封装。以URL注册方式来接入组件,在副作用小,业务运营方便的背景下,蘑菇街的选择或许并不能算作‘’错误的方向“。
第二类业务模块不具备UI场景,但却和具体的业务相关。比如日志上报模块,app可能需要统计用户注册模块每个Controller进入的路径,便于分析每一步用户的流失率。这类业务模块如果要用URL去表达和接入会显得非常变扭。试想下通过如下的代码调用启用日志:
[MGJRouter sharedInstance] openURL:@"mgj://log/start" withParams:@{}];
这也是蘑菇街以URL方案来实现组件化不合理的地方,按Casa的分法,组件被调用分为远程和本地,这种日志服务的调用是本地类型的调用,用URL来标这类记本地服务颇有些绕远路的感觉。
第三类模块和具体的业务场景无关,比如Database模块,提供数据的读写服务,包含多线程的处理。比如Network模块,提供和Server数据交互的方式,包含并发数控制,网络优化等处理。比如图片处理类,提供异步绘制圆角头像。这些模块可以被任意模块使用,但不和任何业务相关。这种组件属于我们app的基础服务提供者,更像是一个个SDK,或是toolkit。我不知道蘑菇街是怎么处理这类组件接入的,很明显URL的接入方式并不适合。我们通过Pods使用的很多著名第三方库都属于这一类,像FMDB,SDWebImage等。
接下来我们再看看各家方案对上面三种组件的接入能力及优缺点。
蘑菇街的URL方案
首先从上面的分析可以看出,这种方案在针对第一类组件是并没有什么大问题,只是不太适合第二类和第三类组件。
URL方案在启动的时候有个模块初始化的过程,初始化的时候注册模块自己提供的各种服务:
[MGJRouter registerURLPattern:@"mgj://detail?id=:id" toHandler:^(NSDictionary routerParameters) {
NSNumber id = routerParameters[@"id"];
// create view controller with id
// push view controller
}];
组件的使用方使用的时候通过传入具体的URL Pattern来完成调用:
[MGJRouter openURL:@"mgj://detail?id=404"]
Bang针对这种方式提出了三个问题:
- 需要有个地方列出各个组件里有什么 URL 接口可供调用。蘑菇街做了个后台专门管理。
- 每个组件都需要初始化,内存里需要保存一份表,组件多了会有内存问题。
- 参数的格式不明确,是个灵活的 dictionary,也需要有个地方可以查参数格式。
第一个问题是最明显的问题,组件的使用方必须通过查阅web文档之后,再手写string来完成调用。这种组件调用方式确实会有一定的效率问题。
第二个问题所说的表和内存问题我没理解具体是指哪一块。我算了下Router当中的额外内存开销,一个用来存储Mapping的NSMutableDictionary,iOS App当中使用Dictionary的场景会很多,Dictionary带来的内存开销主要看其所强引用的key和value。二是以URLPattern为Key的各种string,这个估计是大头,但Casa的方案里将Action以String的方式hardcode,也会导致这些String常住内存,其本质是将原本处于Text区的函数符号换成了位于Data区的string,此消彼长,这部分内存消耗也在正常范围之内,最后是handler block,这部分开销也属于常规使用,和一次函数调用并没有本质区别,看上去内存消耗总量并没有特别增长,或许还有其他我没考虑到的部分。
第三个问题其实和第一个问题是类似的,需要查阅文档来hardcode参数名称。
在我看来这种URL注册的方式本质是 以string来替换原本的函数声明 ,string可以避免头文件引用,实现了编译上的解耦,但付出的代价是没有接口和参数声明,给组件使用方的效率带来了影响。
MGJRouter其实也是充当了Mediator的角色,只不过是大部分时候是在组件和组件使用方之间传递数据。Router如果自己解析URL,也可以加入中间逻辑来判断组件是否存在等。
Casa的Mediator方案
Casa在提出Mediator方案之前,首先指出了蘑菇街方案混淆本地调用和远程调用的问题。这点很有意义,将组件化的使用场景描述的更明确。
Casa提出了Mediator方案,他的方案当中Mediator承接了大部分的组件接入代码,可以用如下图示:
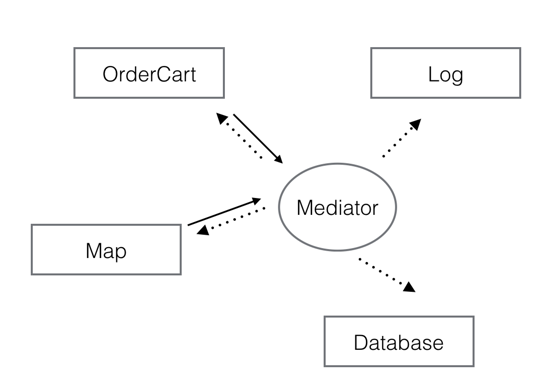
图中虚线箭头表示Casa所提出的”通过runtime发现服务的过程“,Bang也认为虚线箭头部分实现了解耦,不需要import头文件,可以通过runtime来完成组件的接入。
这里我对”发现服务“这个概念存有疑惑,我所了解的wsdl可以用来发现web sevice所提供的具体服务,你需要发送一个web请求来获取wsdl文件,这可以称作是”发现服务“的过程。但是使用OC的runtime机制以String来完成函数调用是”使用服务“的一种方式,你还是需要组件方提供额外文档来描述具体有哪些服务,不然从何处去”发现“这些String呢?所以私以为runtime并不能发现服务,只是换了一种方式去调用服务,把原来的[object sendMessage]换成了[object performSelector:@””]。当然runtime的方式看起来没有耦合。
这里我们再来探讨下耦合的概念,我们可以从多种维度去理解耦合,import头文件算一种耦合,因为头文件缺失会导致编译出错。业务耦合是另一种维度的耦合,我不认为业务的耦合可以被消除多少,你需要使用的组件服务因为业务需要一个都不能少,你可以选择不同的调用方式,但调用本身是一定存在的,我在上图中用虚线箭头表示了这种业务耦合,它无法被消除,可以从语法上,从代码技巧上去”弱化“,但这种”弱化“也有其代价。
这种代价和蘑菇街URL注册方式是同一种代价,以String来替换原先的函数和参数声明,配合runtime来完成组件调用。这种方式同样会加大接入的难度,我们来看下Casa Demo的工程结构:

Mediator对组件的使用方提供了Category来暴露所支持的服务,对使用方来说看上去很清晰。但Mediator其实也是由组件使用方来维护的,我们看看Mediator当中的代码。CTMediator+CTMediatorModuleAActions.m当中完成一个服务接入的代码如下:
//CTMediator+CTMediatorModuleAActions.m
NSString const kCTMediatorTargetA = @"A";
NSString const kCTMediatorActionNativFetchDetailViewController = @"nativeFetchDetailViewController";
- (UIViewController )CTMediator_viewControllerForDetail
{
UIViewController viewController = [self performTarget:kCTMediatorTargetA action:kCTMediatorActionNativFetchDetailViewController
params:@{@"key":@"value"}];
if ([viewController isKindOfClass:[UIViewController class]]) {
// view controller 交付出去之后,可以由外界选择是push还是present
return viewController;
} else {
// 这里处理异常场景,具体如何处理取决于产品
return [[UIViewController alloc] init];
}
}
Target,Action,Params全是用String去描述的,这里会有个问题:
如果组件使用团队在杭州,组件开发团队位于北京,如何去获取这些String?
如果是通过web文档的方式,那么使用方需要依照文档将Target,Action,每个Param全部手敲一遍,一个都不能出错,传入param value的时候要看清楚对方是需要long还是NSNumber,因为没有类型检查,只能靠肉眼。如果没有文档,使用方需要自己查看组件的头文件,再把头文件当中暴露的接口翻译成String。这个方式看起来效率并不高且易出错。
DemoModule下有两个问题。
第一是target在解析组件param的时候需要再次的hardcode:
- (UIViewController )Action_nativeFetchDetailViewController:(NSDictionary )params
{
// 因为action是从属于ModuleA的,所以action直接可以使用ModuleA里的所有声明
DemoModuleADetailViewController *viewController = [[DemoModuleADetailViewController alloc] init];
viewController.valueLabel.text = params[@"key"];
return viewController;
}
同一个@”key“同时出现在了组件方和组件调用方,我不知道该如何去高效的协调这种hardcode,或许还是只能依赖web文档,但查文档对于程序员编写代码来说是个低效的过程。
第二个问题是参数是以Dictionary传入的,我不知道有多少开发SDK或者组件的团队会选择以Dictionary的方式定义”函数入参“。使用Dictionary很符合Casa” 去Model化“ 的风格,我对于Casa所提的”去Model化“始终存疑,我仔细读过其博客关于“去model化”的解释,也拜读了Martin Fowler反对Anemic Domain Model的文章,Martin Fowler并没有反对使用model,而是提倡让model去承担更多的domain logic,就我个人写代码体验而言,使用model来描述数据比dictionary更清晰直观,这里使用显示的函数入参声明也更直观。第三方库在提供接口的时候也鲜少有以Dictionary作为入参的。
从上面两个问题可以看出,Mediator的方式并没有减少组件使用方的接入工作,反而因为要降低耦合,使用runtime,在hardcode String上引入了额外的人力消耗。
Protocol+Version方案
Bang在梳理各种方案的时候画了两张很有意思的图:
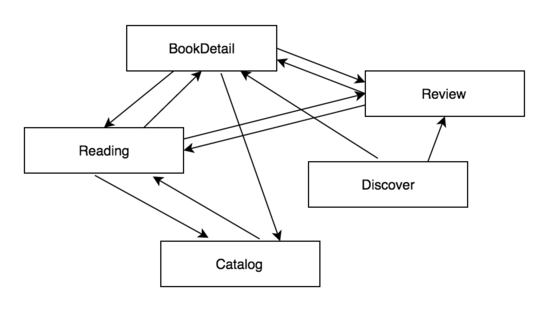
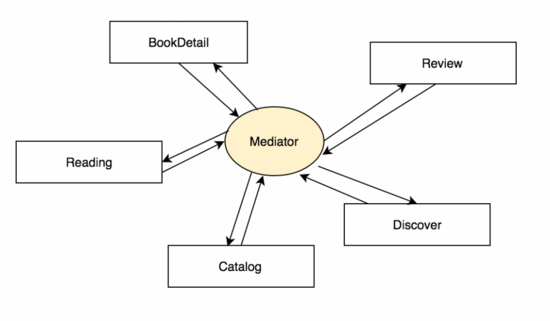
第一张图看上去杂乱无章,互相耦合。第二张图通过Mediator将结构变得清晰很多。
这两张图其实表达了一个业界经典的问题: Distributed Design Vs Centralized Design
第一张图看上去是一坨,但它却是典型的Distributed Design。第二种图更符合人脑的”审美“,Centralized在结构上更容易被大脑梳理清楚。具体到工程场景,孰优孰劣还真不一定。
不知道大家有没有了解过IP协议的路由寻址算法,这也是 Distributed Design Vs Centralized Design 的一个经典场景。如果采用Centralized Design,我们可以用一个cache空间无限大,packet处理能力没有瓶颈的中央路由器来”瞬时“的算出两个路由器之间的最短路径,但显然并不存在这样的路由器。现实是每个路由器所能缓存的周边路由器信息相当有限,packet处理能力也十分有限,结果是每个路由器只能在自己所认知的范围内算最短路径,但这就是今天的互联网所使用的设计,Distributed Design。
Centralized设计在Node增加的情形下会增加中央节点的负担。Mediator就是这个中央节点,工作量并没有减少,未来的风险不可预知。
我个人在组件化上还是倾向于Distributed Design。各个组件”自扫门前雪“,以”高内聚,低耦合“为己任,用规范的protocol声明,加上严格的版本控制来提供组件服务。姑且称之为Protocol+Version方案。
关键字:ios, 产品经理
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
