再说Sora原理:让复杂变简单
继上一次分享的《能看懂的Sora原理》讨论Sora如何生成视频的原理之后,让我们再进一步集中探索一下空间时间补丁(Spacetime Patches)这一概念。因为这一概念对于理解Sora如何处理复杂视觉内容至关重要。
空间时间补丁可以简单理解为将视频或图片内容分解为一系列小块或“补丁”,每个小块都包含了部分时间空间信息。这种方法的灵感来源于处理静态图像的技术,其中图像被分成小块以便于更有效地处理。在视频处理的背景下,这一概念被拓展到了时间维度,不仅包含空间(即图像的部分区域),还包括时间(即这些区域随时间的变化)。
为了理解空间时间补丁是如何工作的,我们可以借用一个简单的日常生活中的比喻:想象一下,你在观看一部电影。如果我们将这部电影切割成一帧帧的静态画面,每帧画面进一步切割成更小的区域(即“补丁”),那么每个小区域都会包含一部分画面的信息。随着时间的推移,这些小区域中的信息会随着物体的移动或场景的变化而变化,从而在时间维度上添加了动态信息。
在Sora中,这样的“空间时间补丁”使得模型可以更细致地处理视频内容的每一个小片段,同时考虑它们随时间的变化。
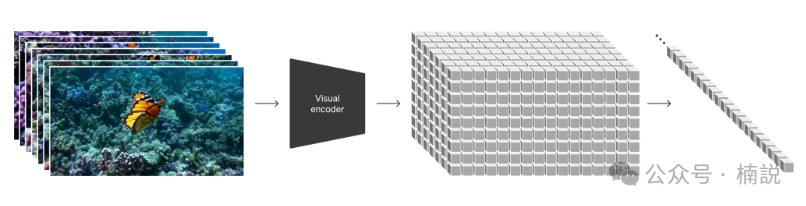
具体到Sora处理视觉内容的过程中,空间时间补丁首先通过视频压缩网络生成。这一网络负责将原始视频数据压缩成更低维度的表示形式,即一个由许多小块组成的密集网络。这些小块即为我们所说的“补丁”,每个补丁都携带了一部分视频的空间和时间信息。
一旦生成了这些空间时间补丁,Sora就可以开始它们的转换过程了。通过预先训练好的转换器(Transformer模型),Sora能够识别每个补丁的内容,并根据给定的文本提示进行相应的修改。例如,如果文本提示是“雪地中的狗狗奔跑”,Sora将找到与“雪地”和“奔跑的狗狗”相关的补丁,并相应调整它们,以生成与文本提示匹配的视频内容。
之所以Sora可以将“雪地”和“奔跑的狗狗”放在一起,是因为Sora是一个基于语言模型范式的视频模型。但是要理解为什么语言模型范式在视频生成任务上也能这么有效,我们先打个比方来说一下语言模型为什么能成功生成语言:
语言模型基于一种叫做“token”的概念来抽象[多模态]的语言(语言,数学,代码。。。)并通过“预测” token 来生成段落。
打个比方:
“你吃” 是一个 “Token”
那么你猜下一个Token更应该是以下哪个?
“了吗”、 “足浴店”、 “变形金刚” 。。。
很显然, 答案是 “了吗”.
所以你明白了吗?就像是你手机输入法的那个“自动补全” 功能, 只不过 token不是具体的词汇, 是一种隐空间表达的语言段落, 训练的数据量和方式也更高级。
这其实就是语言模型范式最简单的原理,根据上一个Token,推测下一个Token,然后不断往下去“扯犊子”并最终形成一个篇章的行为模式。
再回到Sora这个基于语言模型的视频生成模型,当他收到对应文字提示时,他就会自动抓取跟文字提示有关系的哪些“补丁”然后再将这些补丁从时间和控件维度上进行拼接,最终形成你想要的视频。
这种基于空间时间补丁的处理方式有几个显著优势。首先,它允许Sora以非常精细的层次操作视频内容,因为它可以独立处理视频中的每一小块信息。其次,这种方法极大地提高了处理视频的灵活性,使得Sora能够生成具有复杂动态的高质量视频,而这对于传统视频生成技术来说是一个巨大的挑战。
此外,通过对这些补丁进行有效管理和转换,Sora能够在保证视频内容连贯性的同时,创造出丰富多样的视觉效果,满足用户的各种需求。
随着对Sora视频生成过程的进一步探讨,我们可以看到,空间时间补丁在这一过程中扮演了极其重要的角色。它们不仅是Sora处理和理解复杂视觉内容的基石,也是使得Sora能够高效生成高质量视频的关键因素之一。接下来,我们将更深入地探讨视频压缩网络及其与空间时间潜在补丁之间的关系,以及它们在视频生成过程中的作用。
一、视频压缩网络
想象一下,你正要将成一个十分复杂的乐高积木分类整理并重新拼组。你的目标是,用尽可能少的盒子装下所有部件,同时确保能快速找到所需之部件。在这个过程中,你可能会将每个小部件装入小盒子中,然后将这些小盒子放入更大的箱子里。这样,你就用更少、更有组织的空间存储了同样多的部件。
视频压缩网络正是遵循这一原理。它将一段视频的内容“分类和组织”成一个更加紧凑、高效的形式(即降维)。这样,Sora就能在处理时更高效,同时仍保留足够的信息来重建原始视频。
二、空间时间潜在补丁提取
接下来,如果你想要细致地记下每个盒子里装了什么,可能会为每个盒子编写一张清单。这样,当你需要找回某个积木部件时,只需查看对应的清单,就能快速定位它在哪个盒子里。
在Sora中,类似的“清单”就是空间时间潜在补丁。通过视频压缩网络处理后,Sora会将视频分解成一个个小块,这些小块含有视频中一小部分的空间和时间信息,就好像是对视频内容的详细“清单”。这让Sora在之后的步骤中能针对性地处理视频的每一部分。
三、Transformer模型抓取空间时间补丁
最后,想象一下。某一日你将这幅乐高积木进行拼装复原,你仔细阅读了拼装说明,你先将乐高积木分成若干模块。然后,你根据各模块对应的说明拼装出积木的一部分。最终,你再将各模块的部分进行合并,形成一幅完整积木。
在Sora的视频生成过程中,Transformer模型正扮演着类似你一样的角色。它接收空间时间潜在补丁(即视频内容的“拼部件”)和文本提示(即“说明”),然后决定如何将这些片段转换或组合以生成最终的视频,从而完成可高积木的拼装和组合。这一过程既有时间维度,又有空间维度,每一个乐高部件都相当于一个空间时间补丁。最终生成一个完整的视频。
通过上述这三个关键步骤的协同工作,Sora能够将文本提示转化为具有丰富细节和动态效果的视频内容。不仅如此,这一过程还极大地提升了视频内容生成的灵活性和创造力,使Sora成为一个强大的视频创作工具。
最后让我再一起欣赏下Sora生成的视频:
Sora能够生成展现动态摄像机运动的视频,这意味着它不仅能捕捉到平面图像中的动作,还能以3D的视角呈现物体和人物的运动。以下是模拟无人机对在山涧中的人进行追踪拍摄的画面。展现了Sora对三维空间理解的深度,使得生成的视频在视觉上更加真实和生动。

一直旋转的山
在生成长视频时,保持视频中的人物、物体和场景的一致性是一项挑战。Sora展示了在这方面的卓越能力,能够在视频的多个镜头中准确保持角色的外观和属性。例如下方的视频画面,当人物穿行而过,能保持狗的样貌和姿势保持一致,体现了Sora在维持长期一致性上的强大能力。

总是张望的狗
Sora真的就如同人类认知这个世界的方式去理解一切事物,它也会有一些反物理常识的问题出现,比如下方这个视频,被子没有破碎,里面的水就已经洒出来了,这是因为对于复杂的物理互动,如玻璃破碎的精细过程,或是涉及精确力学运动的场景,Sora有时无法准确再现。这主要是因为Sora目前的训练数据中缺乏足够的实例来让模型学习这些复杂的物理现象。

总的来说,Sora在视频生成和模拟真实世界互动方面的表现虽然已经很出色,但仍然存在诸多挑战。不过我们有理由相信,未来Sora能够在保持创新的同时,克服当前面临的局限性,展现出更加强大和广泛的应用潜力。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
