如何解决那些影响系统使用的意外因素
最近做一个项目遇到未知的风险问题,本文主要复盘介绍问题出现到解决的过程,提醒大家一定要重视项目中遇到的每个问题。
一、项目问题回顾
7月初,我主导的一款0-1的项目达到上线标准,上线第一天运行正常,第二天业务反馈了一个项目预料之外的问题:新建供应商选择地址时,系统中所显示的为“广东省-广州市-从化市”,但是最新真实的信息为“广东省-广州市-从化区”。
1. 第一个问题
初始我没太在意这个问题,以为是基础数据那边字段写错了,和技术沟通把数据库的名字改为“从化区”吧,技术表示可以。
下午,技术找我说,无法直接修改名称。因为“从化市”和“从化区”的行政代码不同,如果要修改,就要把行政代码一起改掉,但是其他系统极有可能已经使用了这个基础数据,我们对数据发生改变会影响现有系统的使用。
出于好奇,我去百度查了一下,因为“从化市”撤市建区了,所以名字和行政代码都发生了改变,
综合考虑之下,我们沟通了一个方案,把旧的数据设置一个状态为“禁用”,新的有效数据为“启用”,如下图:

2. 第二个问题
因为之前没有关注过这些基础数据,我跟技术进行了一些深度的交流,如下:
我:你们这些基础数据是从哪里来的?
技术:从国家统计局上面爬下来的。
我:这个没有接口获取吗?
技术:没有,大家都是从这上面获取下来的。
我:这些数据我们公司多久更新一次呀。
技术:爬下来就没更新过了。
我:那岂不是很多数据都没有更新?不仅仅是这个“从化区”的问题?
技术:可能吧。
我:先别改数据,我先去调研排查一下。
于是我又百度了最近几年中国省市区变化的情况,并且打开国家统计局网站,找到了一份最新的省市区街道的信息,与现有系统的数据做对比,果然发现,现在我们使用的数据最近几年都没有更新。
这不是单个数据的问题,整套数据都要进行一份最全的更新,我紧急召开会议,与技术同事沟通商定了一个方案,技术从国家统计局网站上更新一份最新的数据,与现有数据库的数据做对比,做增量更新,并把历史数据在新数据中不存在的标记为“禁用”。
数据更新之后,我抽查一部分数据做了对比,已经和现有数据一致了,我单纯以为这个事情已经解决了。
3. 第三个问题
没过多久,业务给我反馈,广东东莞无法选择“区/县”,我的第一想法是可能技术拉取数据缺失了。
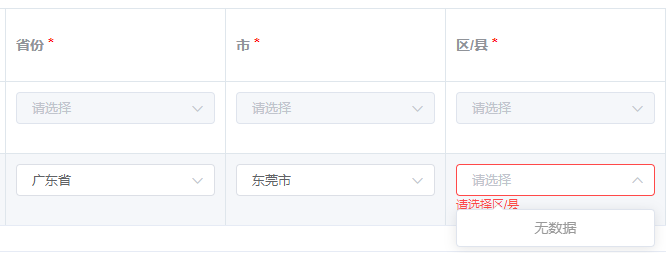
技术排查的结果是国家统计局上面,东莞没有“区/县”。What?没有“区/县”……
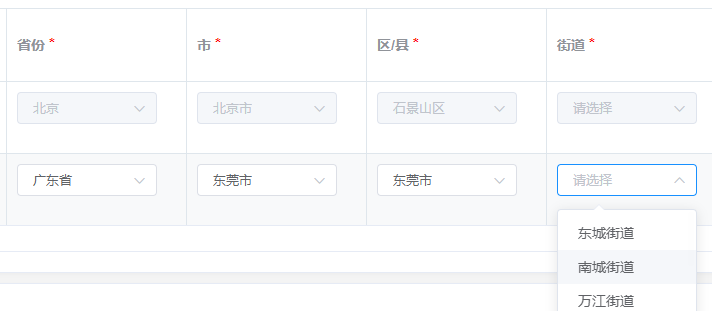
我又打开了万能的百度,搜索结果如图:

我只能说:长见识了,我还专门去淘宝,京东等软件测试了“东莞市”怎么选择,发现这四个地区只需要选三级,其他地区可以选到四级。
根据我们的业务场景,我们确定了一个方案,在“区/县”一级写入一个与市相同的数据,这样就可以顺利选到四级街道地址。
地址问题从发现到真正解决耗时5个工作日,影响了业务方正常作业。
二、反思问题
本次问题的出现,似乎我们各方都没有责任。但影响了使用,我们仍然要反思中间的问题:
- 遇到问题初期把问题想的过于简单化;
- 没有深入去了解问题发生的原因,导致问题没有彻底解决;
- 对未知风险,缺乏风险应对措施。
三、总结
在项目规划阶段,要考虑未知风险;
任何问题的出现都要进行重视;
问题解决之后认真复盘,防止问题重复出现;
望与君共勉,欢迎评论骚扰~
本文作者 @elvin 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
