电商搜索系统精讲系列三步曲2
编辑导读:在电商软件中搜索一款产品,页面中会出现很多相关产品的展示。这些页面是如何展示呢?为什么会这样展示?本文作者以电商产品为例,对其页面排序系统进行分析,希望对你有帮助。
01 排序的场景模型
上篇文章我们针对一个电商搜索系统的业务以及召回分析器和模型的分析,比如当用户在淘宝APP搜索框中输入搜索关键词“2021年新款花式促销女士连衣裙”,搜索系统会通过分析器和各种模型来理解用户的搜索意图,进而达到召回商品的目的(这块的原型将在“电商搜索系统精讲系列三步曲”的下篇会push给大家);
那么思考一个问题,用户搜索“2021年新款花式促销女士连衣裙”之后,页面怎么展示,为什么会这么展示?依据是什么,如下图?

这个就是我们今天要去讲的内容,往下看:
在分析这块的内容之前,同样,我依然举现实生活中的场景模型:
某公司产品总监A需要招聘具有丰富教育中台行业经验的产品经理,在BOSS直聘的岗位描述JD(Job Description)增加了要具备教育中台行业的经验的招聘要求,于是有以下求职者去面试:
应聘者B:有教育行业经验,但无中台产品建设经验;
应聘者C:有教育行业经验,但工作年限比较短,不够丰富;
应聘者D:有中台产品建设经验,但无教育行业经验;
应聘者E:有丰富的教育中台行业经验,但是之前做的是解决方案,并非产品经理岗;
那么现在,假设你作为该公司的产品总监,你该怎么选?先不要看下面,先思考;
答案其实也很简单,你一定是挑选一个适合该岗位要求的吧,那么什么才叫适合,评判的依据是什么?你作为产品总监究竟怎么对这四个求职者进行评估?
现在有些大公司采购了线上招聘系统,人力资源HR和产品总监把对这四位求职者的面试结论以文字的方式直接录入到这个招聘系统,系统就会给出一个建议分,这个建议分值提供给产品总监和HR人员进行决策评估和参考,当然没有这个线上招聘系统也没关系,最土的办法就是下面这种,用手填写面试评估表,用手打分,只不过这种方式的打分更多带有主观色彩。
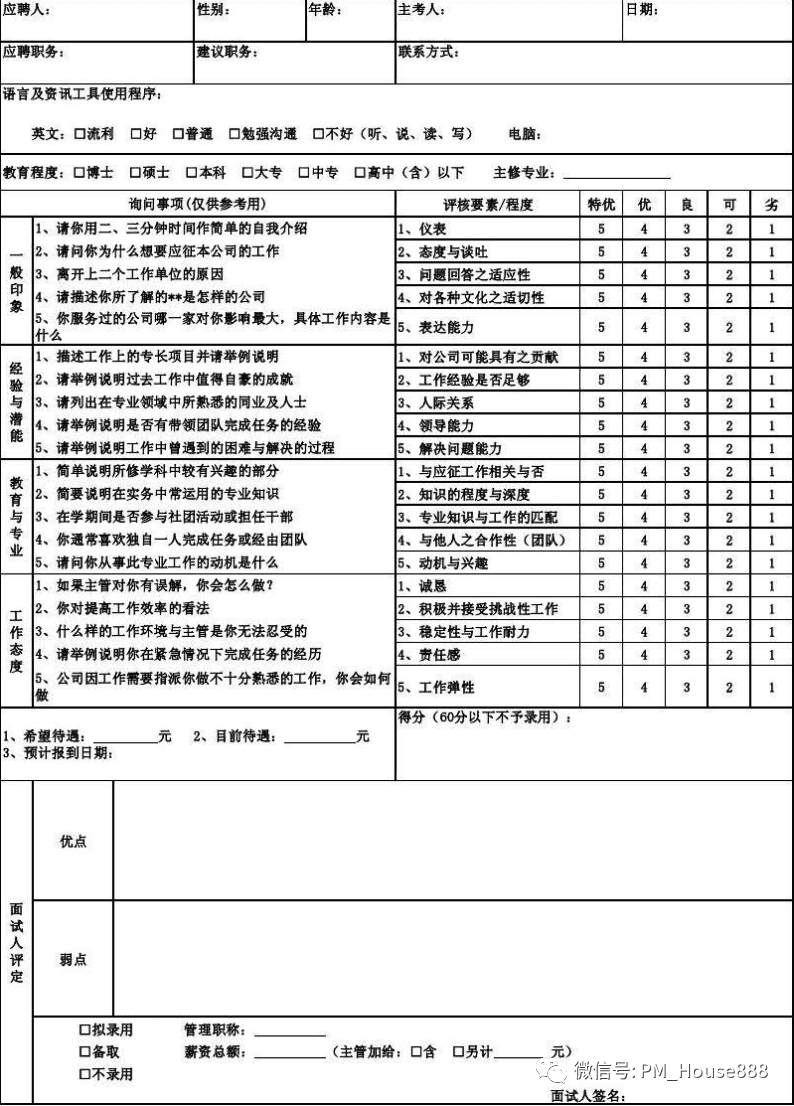
所以最后的结论就是对每个求职者进行打分,然后通过打分来对B、C、D、E四名求职者进行排序,排序第一、第二、第三及第四,最后择优录用;
好,上面说的是招聘的工作,想一想,我们每年高考录取是不是也是这种方式来进行择优录取,同样的场景模型,我们尝试搬迁到线上,应用在召回商品的排序上,接着看:
那么问题来了,同样的场景模型搬迁到线上,就会涉及到对召回的商品打分怎么打的问题,这个是核心,人类有大脑可以用于主观判断,但电脑没有眼睛没有感官系统,没法等同于人类那样去思考,所以我们需要做的就是给他输入一系列的打分规则,电脑就能打分,就能对召回的商品进行排序,从而实现我们的目标,接下来我们看排序的策略;
02 排序策略
大家回想之前浙江卫视的中国好声音节目,那些在电视荧幕上看到的唱歌选手也一定是提前开始海选,然后逐层选拔通过才会参加电视上的唱歌比赛吧,如果没有海选这个环节呢,每个人只要报名都可以直接在电视上唱那么一曲,那岂不是要把浙江卫视那些工作人员累死,所以选手是通过海选,逐层比赛,一关一关的通过,最后挑选出表现优秀的前100名参与电视上的唱歌比赛;
我们采用同样的套路,召回的商品(因为这个量级也是非常巨大的)先海选,再去精选,业内很多人称海选为粗选,所以召回的商品先要进行粗选,通过粗选把可能满足用户意图并且是相对优质的商品(比如有一万个)全部筛选出来,再去优化(一万个召回的商品精选排序)这个选择的结果,最后把选出来的前1000(只是假设)个商品进行排序展示给用户;
搜索引擎本身对于检索性能要求比较高,所以需要采用上面说的两个阶段排序过程:粗排和精排。粗排就是上面说的海选,从检索结果中快速找到优质的商品,取出TOP N个结果再按照精排进行打分,最终返回最优的结果给用户。所以一般在搜索系统中,粗排对性能影响比较大,精排对最终排序效果影响比较大,因此,粗排要求尽量简单有效,只提取数据库表中的关键因子(字段)即可,关键的问题在于打分怎么打,下面将给大家介绍常见的打分策略:
我们首先引入一个新的概念—-表达式计算法
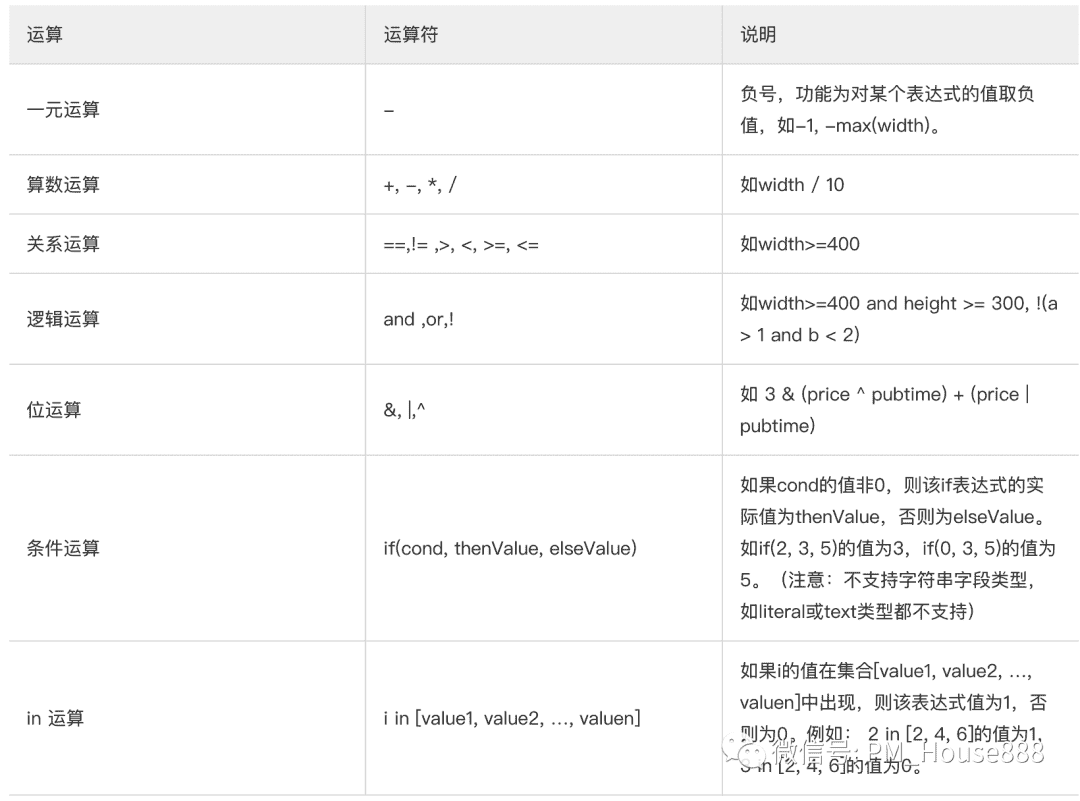
所谓表达式计算法:通俗的讲,就是通过不同的计算公式来运算每个被召回的产品和用户意图的相关度,这个相关度某种意义上讲就是打的分数,业内普遍称这个过程为相关算分,一般常见的计算公式比如基本运算(算术运算、关系运算、逻辑运算、位运算、条件运算)、数学函数和排序特征(feature)等。
基本运算:
数学函数:
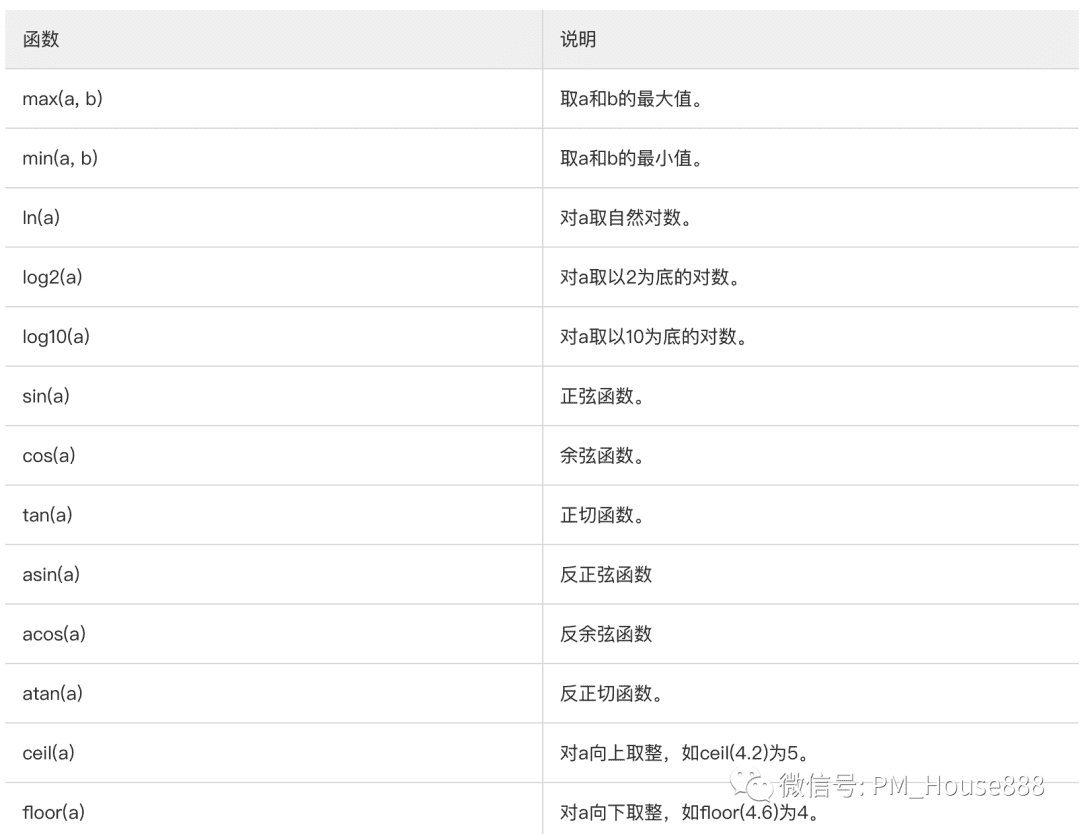
以上两个函数比较简单,高等数学里面都有的内容,这里不再细说,下面来看下上面提到的粗排常用的几个函数(以下为天猫搜索为例):
关键词相似文本分Text similarity()函数:用于计算用户输入的关键词文本与召回的商品相关度,值越大,则相关度越高;
召回商品距离现在的时间GoodsTime()函数:用于计算召回的商品距离现在的时间,一般取值为(0,1)之间,一般值越大,表商品距离现在时间越近,越容易被展示在用户的界面;
类目预测函数CategoryPredic():用于计算用户输入的关键词与商品类目的相关度,关于类目预测这里需要仔细说明下:
所谓类目预测,指的是通过计算机的算法去预测搜索的关键词与商品
类目的相关程度,我们举个例子,当用户在淘宝APP搜索框中输入关键词“苹果”,则类目预测会计算商品所属类目与输入的苹果这个关键词的相关度,类目与关键词的相关度越高,商品就获得了越高的排序得分,也就是上文说到的相关算分值就越高,从而这个商品就会排在越前面,借助下面这两张图,就更好理解了:
第一张图:搜索的关键字是“苹果”,既有手机类的商品也有食物类的商品,左图就是典型的没有使用类目预测模型来打分,所以把食物类的苹果也召回并且优先排序在前面,右图是使用后类目预测模型后的打分排序效果;
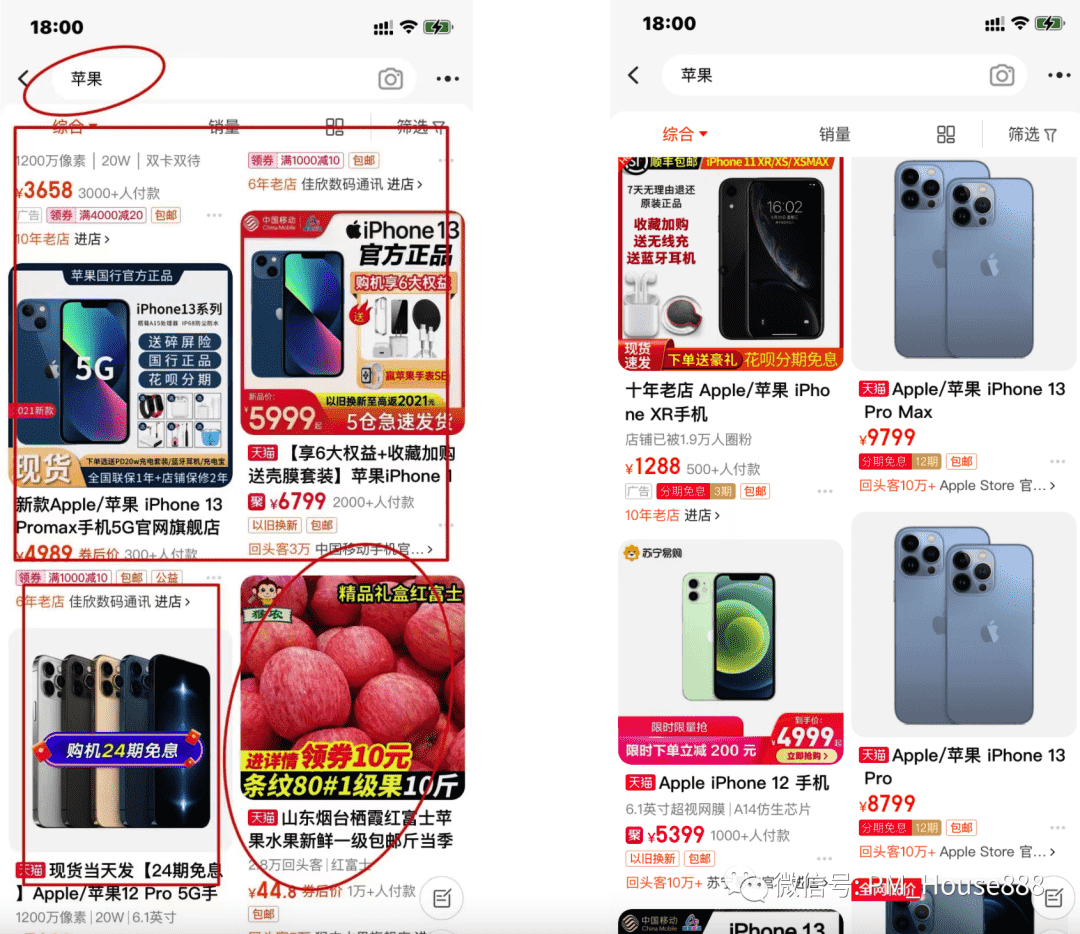
用户输入“苹果”,查询到一批商品,这些商品中有一部分的商品类目是“手机类”,另一部分的商品类目是“食物类”,根据计算机大数据对全量用户的搜索历史行为分析得出,搜索“苹果”的人里面,点击“手机类”类目商品的人要比点击“食物类”类目商品的人多得多,则类目预测就会给出这样的预测结果:“手机类”类目与“苹果”的相关度要比“食物类”类目与“苹果”的相关度高,所以在计算每个商品的相关算分时,“手机类”类目商品的算分值就会比“食物类”类目的商品算分值高,因此“手机类”类目的商品会排在更前面,这样就提高了搜索的业务价值;
所以我们在做产品原型设计的时候也要考虑搜索的关键词与商品类目的相关程度,需要在原型的设计里面增加类目预测的模型的设计;
再来回过头看,我前面讲的,排序首选要进行海选也就是粗排,再针对粗排后的商品结果进行精排,粗排已经讲了,精排怎么排?
同样是要通过函数去计算搜索的关键词与商品的相关度,常见的函数有:
文本相关度函数:
text_relevance: 关键词在字段上的商品匹配度
field_match_ratio:获取某字段上与查询词匹配的分词词组个数与该字段总词组个数的比值
query_match_ratio:获取查询词中(在某个字段上)命中词组个数与总词组个数的比值
fieldterm_proximity: 用来表示关键词分词词组在字段上的紧密程度
field_length:获取某个字段上的分词词组个数
query_term_count: 返回查询词分词后词组个数
query_term_match_count:获取查询词中(在某个字段上)命中文档的词组个数
field_term_match_count:获取文档中某个字段与查询词匹配的词组个数
query_min_slide_window:查询词在某个字段上命中的分词词组个数与该词组在字段上最小窗口的比值
地理位置相关性:
distance: 获取两个点之间的球面距离。一般用于LBS的距离计算。
gauss_decay,使用高斯函数,根据数值和给定的起始点之间的距离,计算其衰减程度
linear_decay,使用线性函数,根据数值和给定的起始点之间的距离,计算其衰减程度
exp_decay,使用指数函数,根据数值和给定的起始点之间的距离,计算其衰减程度
时效性:
timeliness: 时效分,用于衡量商品的新旧程度,单位为秒
timeliness_ms: 时效分,用于衡量商品的新旧程度,单位为毫秒
算法相关性:
category_score:类目预测函数,返回参数中指定的类目字段与类目预测query的类目匹配分
popularity:人气分,用于衡量物品的受欢迎程度
功能性:
tag_match: 用于对查询语句和商品做标签匹配,使用匹配结果对商品进行算分加权
first_phase_score:获取粗排表达式最终计算分值
kvpairs_value: 获取查询串中kvpairs子句中指定字段的值
normalize:归一化函数,根据不同的算分将数值归一化至[0, 1]
in/notin : 判断字段值是否(不)在指定列表中
以上函数大家不用去研究细节,看看函数的中文解释就好,帮助理解和消化,知道精排的算分怎么统计、哪些维度去统计即可,如果依然不理解的,可以跟我一起交流;
说到现在大家一定很好奇,为什么用户最关心的商品热度没有提到,不着急不着急,接下来,我们就要针对搜索热度比较高的商品一般怎么排序,引入一个新的概念—–人气模型;
上面说的类目预测模型是要实时去计算,而人气模型可以在离线的时候进行计算,一般也叫离线计算模型,这种模型也是淘宝和天猫搜索最基础的排序算法模型。
人气模型会计算量化出每个商品的静态质量以及受欢迎的程度的值,这个值称之为商品人气分,最开始人气模型是来自淘宝的搜索业务,但其实这个模型对于其他的搜索场景也有很强的通用性,在非商品搜索场景中通过人气模型也可以计算出被索引的商品的受欢迎程度,比如某个论坛,可以通过人气模型排序搜索比较多的帖子,把这些帖子内容优先展示给用户;
那么对于一个商品而言,这个人气模型究竟怎么计算,毕竟系统的目标是通过这个模型来计算商品的热度,进而打分排序,你说对吧;
一般情况下,人气模型从四个维度去计算分值,具体如下:
第一个维度:实体维度;
比如:商品、品牌、商家、类目等。
第二个维度:时间维度;
比如:1天、3天、7天、14天、30天等。
第三个维度:行为维度;
比如:曝光、点击、收藏、加购、购买、评论、点赞等。
第四个维度:统计维度;
比如:数量、人数、频率、点击率、转化率等。
每个特征从以上4个维度中各取一到两个进行组合,再从历史数据中统计该组合特征最终的特征值:
比如:
商品(实体)最近1天(时间)的曝光(行为)量(统计指标);
商品所在店铺(实体)最近30天(时间)的销量(行为类型+统计维度)等等。
由以上方法产生的结果数量级,等同于去计算4个维度的笛卡尔积,再对笛卡尔积的算分高低进行排序;
好了,说到现在关于召回的商品排序所采用的算法目前我所了解的就这么多,当然能力有限,有些搜索的细节依然需要进一步去摸索;
03 召回与排序总结

我们来对上一篇文章和今天讲的内容简单的做个总结,当用户在淘宝APP搜索框中输入“2021年新款花式促销女士连衣裙”时,搜索引擎系统首先要去理解用户的意图,理解的方式就是上篇文章提到的分析器,通过对语义的理解、命名实体识别、拼写纠错、停止词模型等手段去理解用户的意图,进而通过这个意图计算机去到后台数据库中检索符合意图的所有商品,当商品被检索出来之后,搜索引擎系统首先要通过各类函数和模型对商品进行粗排,再对粗排的结果进行精排,精排的依据就是上面的函数和模型,当然还有类目预测模型和人气模型,这个就是大概的流程;
依然没有结束,首先来看下面这张图:
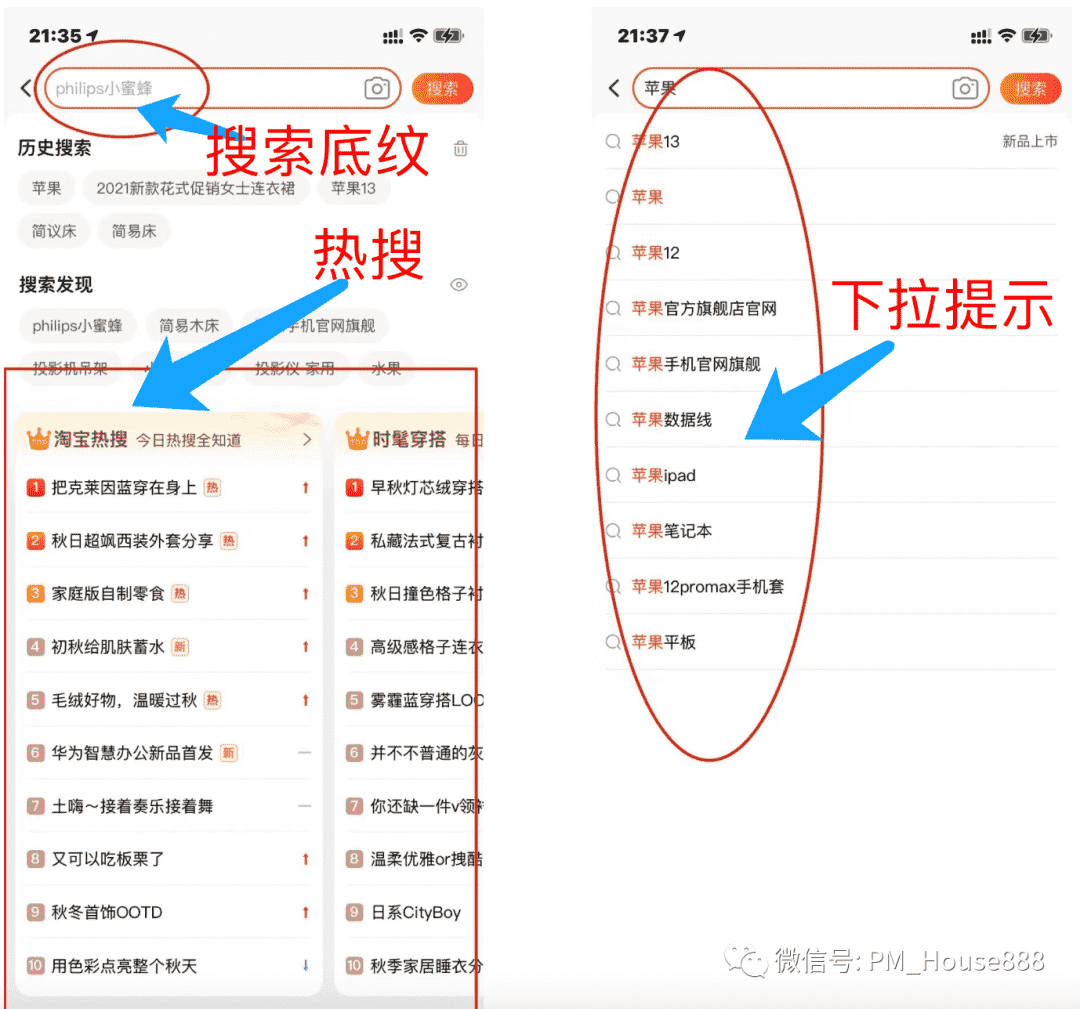
想一想,上面左图中的热搜底纹和热搜列表是怎么来的、右图中的下拉提示又是这么出现的?这个就是原计划需要在今天跟大家讲的引导排序内容;
关于引导排序这块的内容我们放到下一篇继续分享,今天就写到这,再见!
04 预告


作者 @产品研究站
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
