如何用AI大模型打造超级召回引擎
召回模型的目的是从海量的内容或商品中,快速地找出最符合用户需求或兴趣的候选集,为后续的排序和推荐做准备。召回模型的好坏,直接影响了用户体验和业务收益,因此是数字化营销中不可或缺的核心环节。
然而,召回模型的构建并不容易,它面临着以下几个挑战:
- 数据量巨大:随着互联网的发展,内容或商品的数量呈指数级增长,如何在有限的时间和资源内,从海量的数据中筛选出最相关的候选集,是一个非常困难的问题。
- 用户行为复杂:用户的需求或兴趣是多样的,而且随着时间、场景和情境的变化而变化,如何准确地捕捉和理解用户的行为,是一个非常复杂的问题。
- 内容或商品多样:内容或商品的类型和属性是多样的,而且可能存在多种关联和相似度,如何有效地表示和匹配内容或商品,是一个非常多样的问题。
为了解决这些挑战,我们需要借助人工智能大模型的力量,利用深度数据处理的方法,构建更智能的召回模型。人工智能大模型是指那些具有大量参数和强大计算能力的人工智能模型,它们可以从海量的数据中学习复杂的规律和知识,从而实现更高层次的智能任务。人工智能大模型在自然语言处理、计算机视觉、语音识别等领域都取得了令人惊叹的成果,也为数字化营销提供了新的机遇和可能。
本文将介绍如何应用人工智能大模型实现基于深度数据处理的召回模型,包括以下四个方面:
- 基于知识图谱的召回模型:利用人工智能大模型构建知识图谱,表示和关联内容或商品的多维属性和关系,从而实现基于语义和逻辑的召回。
- 基于用户实时意图的召回模型:利用人工智能大模型捕捉和理解用户的实时意图,从而实现基于场景和情境的召回。
- 基于深度学习的召回模型:利用人工智能大模型学习和预测用户的长期兴趣和短期偏好,从而实现基于行为和兴趣的召回。
- 多路召回融合:利用人工智能大模型融合多种召回策略,从而实现基于综合和优化的召回。
接下来,我们将分别介绍这四个方面的内容,希望能给你带来一些有用的信息和启示。
一、基于知识图谱的召回模型
知识图谱是一种用于表示和存储知识的结构化数据,它由实体、属性和关系组成,形成了一个复杂的网络。知识图谱可以帮助我们理解和关联内容或商品的多维属性和关系,从而实现基于语义和逻辑的召回。
例如,如果我们要召回一些与“苹果”相关的内容或商品,我们可以利用知识图谱中的信息,根据不同的维度和关系,找出不同的候选集,如下图所示:
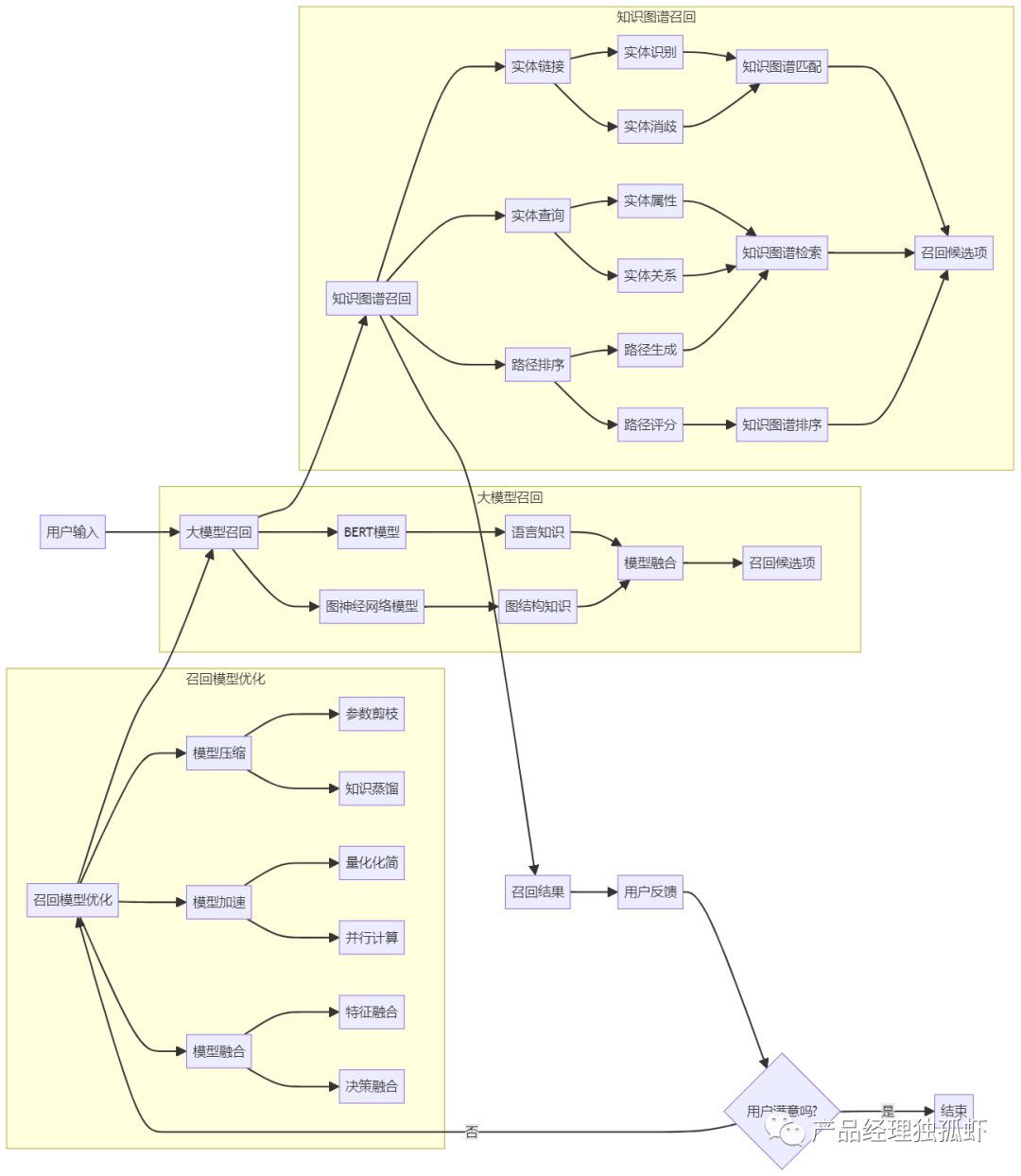
从图中可以看出,知识图谱可以帮助我们从多个角度和层次来召回与“苹果”相关的内容或商品,如:
- 根据类型维度,召回与“苹果”同类的内容或商品,如“梨”、“香蕉”等。
- 根据属性维度,召回与“苹果”具有相同或相似属性的内容或商品,如“红色”、“甜的”等。
- 根据关系维度,召回与“苹果”存在某种关系的内容或商品,如“苹果公司”、“苹果手机”等。
- 根据层次维度,召回与“苹果”属于同一层次或不同层次的内容或商品,如“水果”、“食物”等。
利用知识图谱的召回模型,可以提高召回的精度和覆盖度,同时也可以提高召回的多样性和丰富性,为用户提供更多的选择和发现。
那么,如何构建知识图谱呢?这就需要借助人工智能大模型的能力,从海量的数据中抽取和挖掘实体、属性和关系,然后将它们组织和存储成为知识图谱的形式。这是一个非常复杂的过程,涉及到多个步骤和技术,如:
- 实体识别:从文本、图像、音频等数据中识别出实体,如“苹果”、“梨”、“香蕉”等
- 属性抽取:从数据中抽取出实体的属性,如“苹果”的颜色、味道、产地等
- 关系抽取:从数据中抽取出实体之间的关系,如“苹果”和“苹果公司”的创始人关系、“苹果”和“水果”的属于关系等
- 实体链接:将不同来源或形式的实体链接到同一个实体,如“苹果”、“Apple”、“🍎”等
- 实体消歧:将有歧义的实体区分开,如“苹果”(水果)和“苹果”(公司)等
- 知识融合:将不同来源或形式的知识融合成一个统一的知识图谱,解决知识的冲突和不一致等问题
这些步骤和技术都需要大量的数据和计算资源,而且涉及到多种人工智能领域,如自然语言处理、计算机视觉、语音识别等。人工智能大模型可以帮助我们在这些领域实现更高的准确率和效率,从而构建更完善和更丰富的知识图谱。
例如,我们可以利用人工智能大模型来实现以下几个功能:
- 从文本中抽取实体、属性和关系,如利用BERT等预训练模型来实现命名实体识别、实体关系抽取等任务。
- 从图像中抽取实体、属性和关系,如利用YOLO等目标检测模型来实现图像中的实体识别、属性识别等任务。
- 从音频中抽取实体、属性和关系,如利用Wav2Vec等语音识别模型来实现音频中的实体识别、属性识别等任务。
- 将不同形式的实体链接到同一个实体,如利用SimCSE等语义相似度模型来实现文本、图像、音频等不同形式的实体链接任务。
- 将有歧义的实体消歧,如利用ERNIE等知识增强模型来实现实体消歧任务。
- 将不同来源的知识融合,如利用KGCN等知识图谱协同网络模型来实现知识融合任务。
通过这些功能,我们可以从海量的数据中构建出一个包含了内容或商品的多维属性和关系的知识图谱,从而为召回模型提供了强大的支持。
二、基于用户实时意图的召回模型
用户的需求或兴趣是动态的,它们会随着时间、场景和情境的变化而变化。例如,用户在早上可能想要看一些新闻或教育的内容,而在晚上可能想要看一些娱乐或游戏的内容。用户在工作时可能想要购买一些办公用品,而在休闲时可能想要购买一些运动用品。用户在不同的地点、天气、心情等情况下,可能有不同的需求或兴趣。因此,我们需要捕捉和理解用户的实时意图,从而实现基于场景和情境的召回。
例如,如果我们要召回一些与“电影”相关的内容或商品,我们可以利用用户的实时意图信息,根据不同的场景和情境,找出不同的候选集,如下图所示:
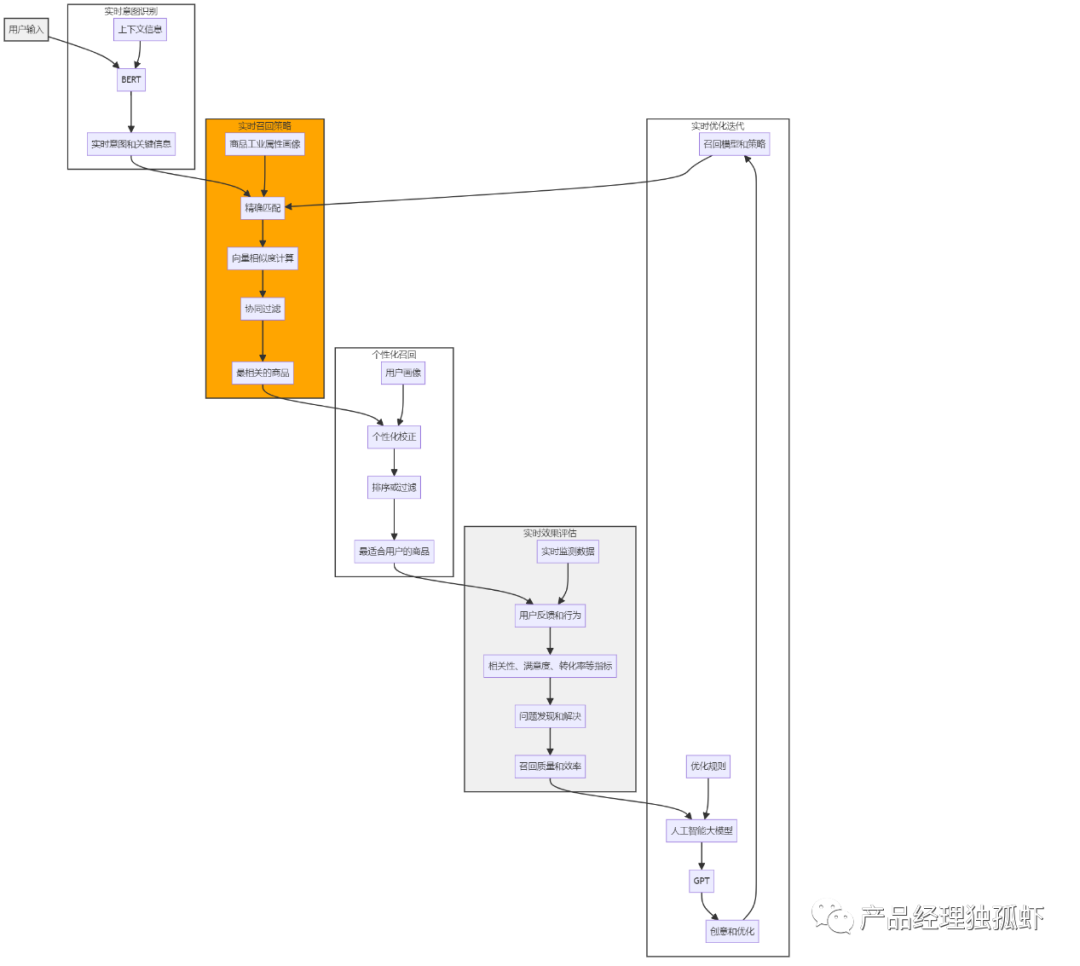
从图中可以看出,用户的实时意图信息可以帮助我们从多个角度和层次来召回与“电影”相关的内容或商品,如:
- 根据时间维度,召回与用户当前时间段相关的内容或商品,如“最新上映的电影”、“即将下架的电影”等。
- 根据场景维度,召回与用户当前场景相关的内容或商品,如“家庭观影的电影”、“影院观影的电影”等。
- 根据情境维度,召回与用户当前情境相关的内容或商品,如“适合情侣看的电影”、“适合孩子看的电影”等。
- 根据层次维度,召回与“电影”属于同一层次或不同层次的内容或商品,如“电视剧”、“小说”等。
利用用户的实时意图的召回模型,可以提高召回的灵活性和个性化,同时也可以提高召回的时效性和实用性,为用户提供更多的满足和惊喜。
那么,如何捕捉和理解用户的实时意图呢?这就需要借助人工智能大模型的能力,从多种数据源中获取和分析用户的实时意图信息,然后将它们转化为召回的策略和条件。这是一个非常复杂的过程,涉及到多个步骤和技术,如:
- 实时意图识别:从用户的输入、行为、反馈等数据中识别出用户的实时意图,如“想看恐怖片”、“想看喜剧片”等
- 实时意图理解:从用户的上下文、历史、偏好等数据中理解用户的实时意图,如“想看恐怖片是因为想刺激一下”、“想看喜剧片是因为想放松一下”等
- 实时意图转化:将用户的实时意图转化为召回的策略和条件,如“根据用户的喜好和评分,召回最符合用户想看恐怖片的电影”、“根据用户的地理位置和时间,召回最符合用户想看喜剧片的电影”等
这些步骤和技术都需要大量的数据和计算资源,而且涉及到多种人工智能领域,如自然语言理解、用户行为分析、推荐系统等。人工智能大模型可以帮助我们在这些领域实现更高的准确率和效率,从而捕捉和理解用户的实时意图。
例如,我们可以利用人工智能大模型来实现以下几个功能:
- 从用户的输入中识别实时意图,如利用GPT-3等生成式预训练模型来实现自然语言理解和生成等任务。
- 从用户的行为中识别实时意图,如利用RL4REC等强化学习模型来实现用户行为分析和预测等任务。
- 从用户的反馈中识别实时意图,如利用BERT等预训练模型来实现情感分析和意图识别等任务。
- 从用户的上下文中理解实时意图,如利用TransNet等注意力机制模型来实现上下文建模和理解等任务。
- 从用户的历史中理解实时意图,如利用DIN等深度学习模型来实现用户历史建模和理解等任务。
- 从用户的偏好中理解实时意图,如利用NCF等神经网络模型来实现用户偏好建模和理解等任务。
- 将用户的实时意图转化为召回策略,如利用MAB等多臂老虎机模型来实现召回策略的选择和优化等任务。
- 将用户的实时意图转化为召回条件,如利用SQL2Seq等序列到序列模型来实现召回条件的生成和执行等任务。
通过这些功能,我们可以从多种数据源中获取和分析用户的实时意图信息,从而为召回模型提供了强大的支持。
三、基于深度学习的召回模型
用户的需求或兴趣是多样的,它们由用户的长期兴趣和短期偏好共同决定。例如,用户可能有一个长期的兴趣爱好,如“喜欢看科幻电影”,但也可能有一个短期的偏好,如“最近想看一些悬疑电影”。用户的长期兴趣和短期偏好可能是相互影响和相互调节的,如“因为喜欢看科幻电影,所以最近想看一些科幻悬疑电影”。因此,我们需要学习和预测用户的长期兴趣和短期偏好,从而实现基于行为和兴趣的召回。
例如,如果我们要召回一些与“电影”相关的内容或商品,我们可以利用用户的长期兴趣和短期偏好信息,根据不同的行为和兴趣,找出不同的候选集,如下图所示:
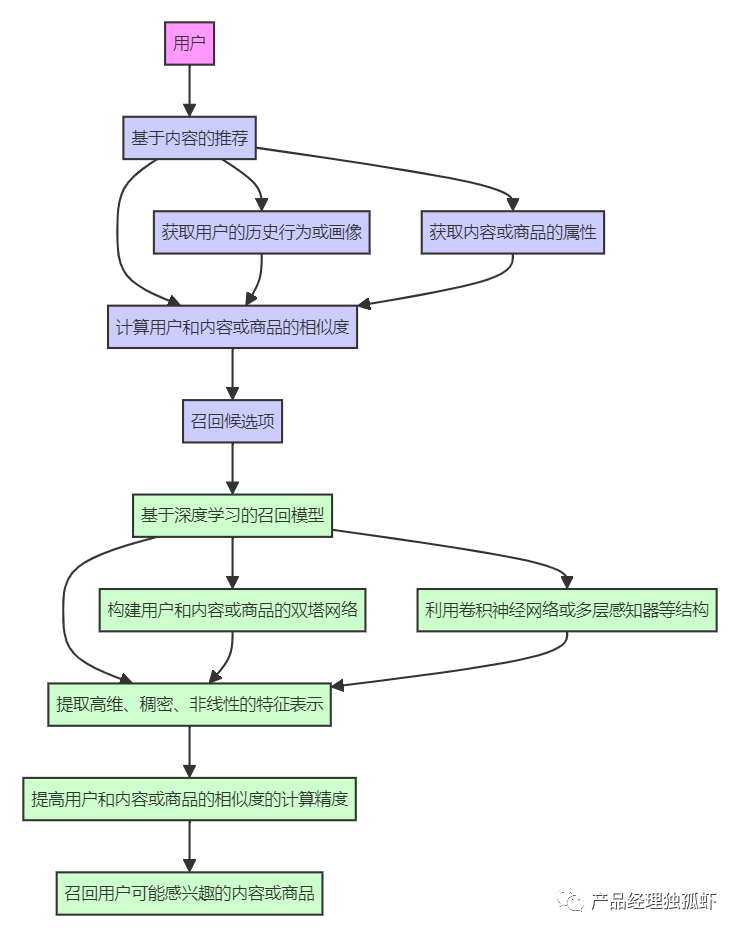
从图中可以看出,用户的长期兴趣和短期偏好信息可以帮助我们从多个角度和层次来召回与“电影”相关的内容或商品,如:
- 根据长期兴趣维度,召回与用户长期兴趣相关的内容或商品,如“科幻电影”、“动作电影”等。
- 根据短期偏好维度,召回与用户短期偏好相关的内容或商品,如“悬疑电影”、“喜剧电影”等。
- 根据行为维度,召回与用户行为相关的内容或商品,如“最近浏览过的电影”、“最近收藏过的电影”等。
- 根据兴趣维度,召回与用户兴趣相关的内容或商品,如“最感兴趣的电影”、“最可能购买的电影”等。
利用用户的长期兴趣和短期偏好的召回模型,可以提高召回的精准性和个性化,同时也可以提高召回的稳定性和灵活性,为用户提供更多的匹配和推荐。
那么,如何学习和预测用户的长期兴趣和短期偏好呢?这就需要借助人工智能大模型的能力,从用户的历史和实时的行为数据中学习用户的长期兴趣和短期偏好的表示,然后将它们用于召回的模型中。这是一个非常复杂的过程,涉及到多个步骤和技术,如:
- 长期兴趣学习:从用户的历史行为数据中学习用户的长期兴趣的表示,如“喜欢看科幻电影”、“喜欢看动作电影”等
- 短期偏好学习:从用户的实时行为数据中学习用户的短期偏好的表示,如“最近想看悬疑电影”、“最近想看喜剧电影”等
- 行为预测:根据用户的长期兴趣和短期偏好的表示,预测用户的未来行为,如“最有可能浏览的电影”、“最有可能收藏的电影”等
- 兴趣预测:根据用户的长期兴趣和短期偏好的表示,预测用户的未来兴趣,如“最感兴趣的电影”、“最可能购买的电影”等
这些步骤和技术都需要大量的数据和计算资源,而且涉及到多种人工智能领域,如深度学习、推荐系统、机器学习等。人工智能大模型可以帮助我们在这些领域实现更高的准确率和效率,从而学习和预测用户的长期兴趣和短期偏好。
例如,我们可以利用人工智能大模型来实现以下几个功能:
- 从用户的历史行为数据中学习长期兴趣,如利用DSSM等深度语义匹配模型来实现用户和内容或商品的语义匹配和兴趣学习等任务。
- 从用户的实时行为数据中学习短期偏好,如利用DIEN等深度兴趣演化模型来实现用户的兴趣演化和偏好学习等任务。
- 根据用户的长期兴趣和短期偏好预测行为,如利用DRL等深度强化学习模型来实现用户行为的动态预测和优化等任务。
- 根据用户的长期兴趣和短期偏好预测兴趣,如利用NPA等神经个性化注意力模型来实现用户兴趣的动态预测和优化等任务。
通过这些功能,我们可以从用户的历史和实时的行为数据中学习用户的长期兴趣和短期偏好的表示,从而为召回模型提供了强大的支持。
四、多路召回融合
我们已经介绍了三种基于深度数据处理的召回模型,分别是基于知识图谱的召回模型、基于用户实时意图的召回模型和基于深度学习的召回模型。这三种召回模型各有优势和局限,它们可以从不同的角度和层次来召回与用户需求或兴趣相关的内容或商品,但也可能存在一些问题,如:
- 基于知识图谱的召回模型,可以提高召回的精度和覆盖度,但也可能召回一些与用户不太相关或不太感兴趣的内容或商品,如“苹果”和“牛顿”、“电影”和“导演”等。
- 基于用户实时意图的召回模型,可以提高召回的灵活性和个性化,但也可能召回一些与用户不太匹配或不太适合的内容或商品,如“想看恐怖片”的用户召回一些过于恐怖或低质量的电影等。
- 基于深度学习的召回模型,可以提高召回的精准性和稳定性,但也可能召回一些与用户过于相似或过于单一的内容或商品,如“喜欢看科幻电影”的用户召回一些缺乏新意或多样性的电影等。
为了解决这些问题,我们需要利用人工智能大模型的能力,融合多种召回策略,从而实现基于综合和优化的召回。多路召回融合是一种将多种召回模型的结果进行融合和优化的方法,它可以综合考虑多种召回模型的优势和局限,从而提高召回的效果和效率。
例如,如果我们要召回一些与“电影”相关的内容或商品,我们可以利用多路召回融合的方法,根据不同的召回模型的结果,进行融合和优化,找出最终的候选集,如下图所示:
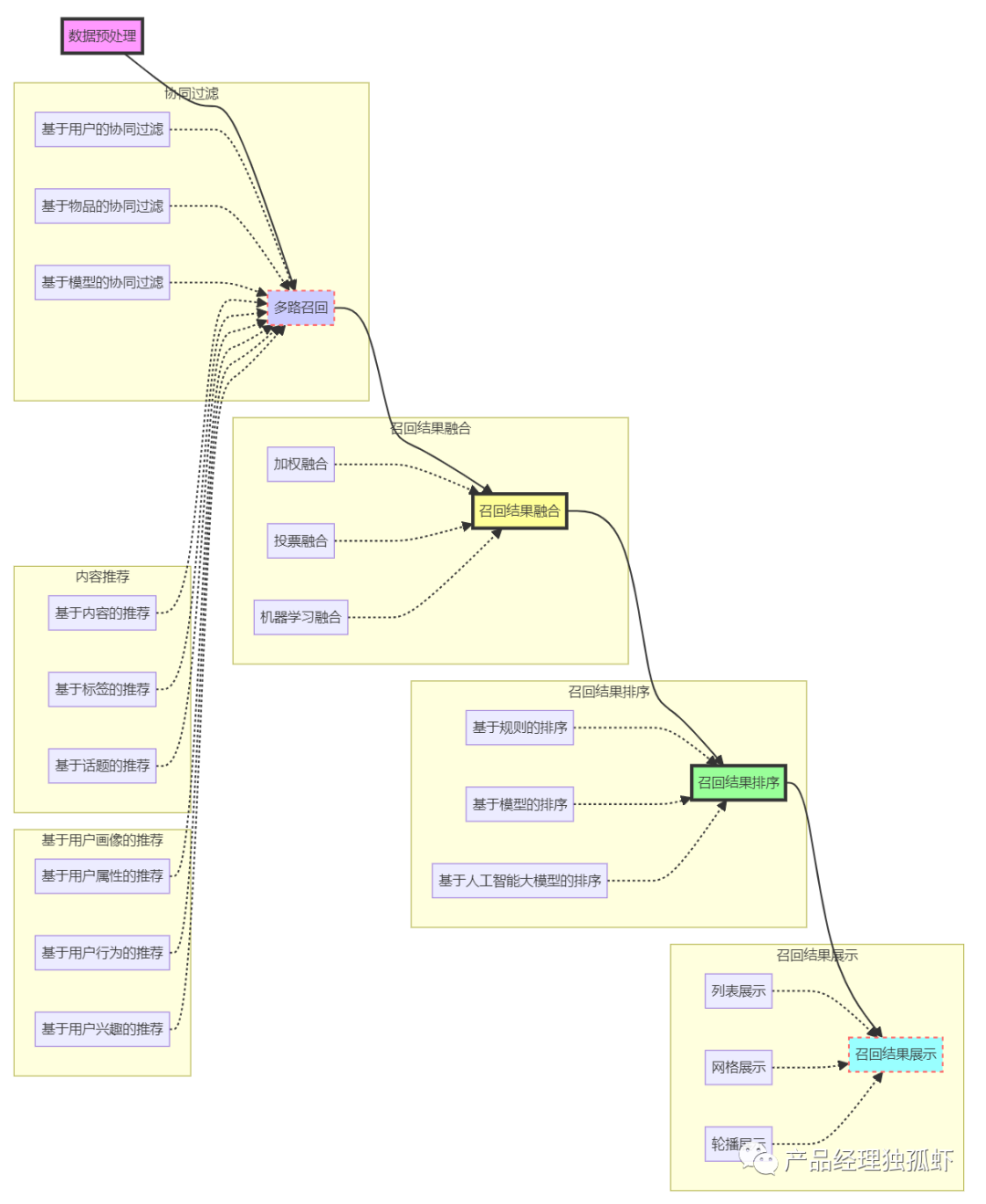
从图中可以看出,多路召回融合的方法可以帮助我们从多种召回模型的结果中,选择和组合最合适的内容或商品,从而实现基于综合和优化的召回,如:
- 根据基于知识图谱的召回模型的结果,召回与“电影”相关的内容或商品,如“科幻电影”、“悬疑电影”等。
- 根据基于用户实时意图的召回模型的结果,召回与用户当前场景和情境相关的内容或商品,如“家庭观影的电影”、“适合情侣看的电影”等。
- 根据基于深度学习的召回模型的结果,召回与用户长期兴趣和短期偏好相关的内容或商品,如“最感兴趣的电影”、“最可能购买的电影”等。
- 根据多路召回融合的方法,融合和优化多种召回模型的结果,召回最终的候选集,如“最符合用户需求和兴趣的电影”等。
利用多路召回融合的方法,可以提高召回的综合性和优化性,同时也可以提高召回的平衡性和协调性,为用户提供更多的优质和合适的内容或商品。
那么,如何实现多路召回融合呢?这就需要借助人工智能大模型的能力,从多种召回模型的结果中,选择和组合最合适的内容或商品,然后将它们作为最终的候选集。这是一个非常复杂的过程,涉及到多个步骤和技术,如:
- 多路召回选择:从多种召回模型的结果中,选择最符合用户需求或兴趣的内容或商品,如“根据用户的实时意图,选择最符合用户当前场景和情境的内容或商品”等
- 多路召回组合:将多种召回模型的结果进行组合,形成一个更丰富和更多样的候选集,如“将基于知识图谱的召回模型和基于深度学习的召回模型的结果进行组合,形成一个包含了语义和兴趣的候选集”等
- 多路召回优化:对多种召回模型的结果进行优化,提高候选集的质量和效率,如“根据用户的反馈和评价,优化候选集的排序和展示”等
这些步骤和技术都需要大量的数据和计算资源,而且涉及到多种人工智能领域,如推荐系统、机器学习、优化算法等。人工智能大模型可以帮助我们在这些领域实现更高的准确率和效率,从而实现多路召回融合。
例如,我们可以利用人工智能大模型来实现以下几个功能:
- 从多种召回模型的结果中选择最合适的内容或商品,如利用MAB等多臂老虎机模型来实现多路召回选择的策略和优化等任务。
- 将多种召回模型的结果进行组合,如利用MMoE等混合专家模型来实现多路召回组合的模型和方法等任务。
- 对多种召回模型的结果进行优化,如利用ESMM等端到端模型来实现多路召回优化的目标和方法等任务。
通过这些功能,我们可以从多种召回模型的结果中,选择和组合最合适的内容或商品,从而为召回模型提供了强大的支持。
五、总结
本文从产品经理的视角,介绍了如何应用人工智能大模型实现基于深度数据处理的召回模型,包括:
- 基于知识图谱的召回模型:利用人工智能大模型构建知识图谱,表示和关联内容或商品的多维属性和关系,从而实现基于语义和逻辑的召回。
- 基于用户实时意图的召回模型:利用人工智能大模型捕捉和理解用户的实时意图,从而实现基于场景和情境的召回。
- 基于深度学习的召回模型:利用人工智能大模型学习和预测用户的长期兴趣和短期偏好,从而实现基于行为和兴趣的召回。
- 多路召回融合:利用人工智能大模型融合多种召回策略,从而实现基于综合和优化的召回。
本文还给出了一些实例和示意图,帮助读者理解和应用这些模型。本文是《用AI驱动数字化营销业绩增长》专栏的一部分,欢迎关注我的个人号“产品经理独孤虾”(全网同号),获取更多关于如何在电商、广告营销和用户增长等数字化营销业务上应用人工智能大模型来优化业务的精彩内容。
本文的主要目的是为了让产品经理和运营人员了解人工智能大模型在召回模型中的应用和价值,从而能够更好地设计和优化数字化营销的业务流程和策略。本文并不涉及过于技术化的细节和原理,如果你想了解更多关于人工智能大模型的原理和实现,你可以参考本文提到的一些参考文献,或者关注我的个人号“产品经理独孤虾”(全网同号),我会在后续的文章中分享更多关于人工智能大模型的技术和应用的内容。
希望本文能够对你有所帮助和启发,如果你有任何问题或建议,欢迎在评论区留言。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
