自然语言处理之智能问答系统
目录
一、问答系统简介
二、搭建基于检索的问答系统
三、其他相似度计算
相关参考:
一、问答系统简介
问答系统通常分为任务型机器人、闲聊机器人和解决型机器人(客服机器人),三者的设计分别针对不同的应用场景。A):任务型机器人主要用于完成用户的某些特定任务,比如:买机票、话费充值或者天气咨询。B):闲聊机器人主要用于深入的和用户进行无目的交流;C):解决型机器人(客服机器人)用于解决用户的问题,比如:商品购买咨询、商品退货咨询等。这里通过一些案例分析来介绍不同情况的算法选型:
任务型问题,1):“成都今天天气怎么样”;2):“明天呢";3):“后天呢”。
Slot Filling
首先,“成都今天天气怎么样”属于天气类问题(其中包含实体“地点”、“时间”),已经能够完成应答;然后,“明天呢”该句话仅包含实体信息(”时间“),并未包含地点信息,如果直接采用意图分类,不能完成此次应答;最后,”后天呢“同样是只包含实体信息(”时间“)。针对此类的多轮对话场景,可采用slot filling的方式进行应答(slot filling是多个槽值组成,例如:天气场景需要实体槽值“地点”和“时间”)。”明天呢“和”后天呢“只包含”时间“实体,但是上文”成都今天天气怎么样“则包含了”地点“实体,只需要将下文的实体(“时间”)替换上文的实体(“时间“)即可。
解决型问题,1):”iphone X多少钱“;2):”邮费是多少呢”;3):“可以无理由退货么?”。
特征拼接上下文模型
针对此处的多轮对话,涉及到商品的购买、售前运费和退换货政策三个意图,并且后面的意图分析需要前文的会话意图,就是一个典型的多轮对话过程。首先,“iphone X多少钱”可以通过单句的意图分类即可完成应答;而“运费是多少呢”则需要判断用户咨询的属于售前运费还是售后运费,此时可通过结合上文问题的方式进行意图分析(1:抽取上文的意图特征加入当前问题可解决部分上下文场景问题;2:结合上文和当前问题采用深度学习的算法进行上下文的意图分析)。最后,“可以无理由退货么”需要知道商品的信息才可以回答用户的问题,因此需要上文商品“iphone X”(可以将对话中实体、商品信息保存用于下文应答)。
解决型问题,1):”https://item.jd.com/6577511.html?jd_pop=67fb9e1c-df43-4cf9-9509-37998e9c983a&abt=0“;2):”多少“;3):”钱?“
层级上下文模型(H-CNN-GRU)
此时多轮对话过程中,涉及到用户输入过程中单句输入不完整。slot filling和简单抽取上文特征的方式并不适合,而组合多句输入则可以完成此处的应答(具体方式见此处)。
闲聊型问题
聊天记录
针对闲聊型问题,由于用户并无明确的意图,因此不适合做意图分类,这里我们可以采用生成式模型,根据大量用户历史的闲聊语料生成相应的答案(生成式模型得到的答案可能存在语法、连贯性问题,但是闲聊场景的对话对语句语法和连贯性要求不高,相对随意)。
seq2seq模型
总结:我们在分析一个人的时候通常涉及IQ和EQ两个方面,IQ在于解决问题的能力,而EQ在于解决问题的方式。在实现一个机器人问答系统的时候,我们也应该考虑IQ和EQ两个方面。这里只是针对问答系统中的一些特殊案例进行分析,一个完整的问答系统仍需要大量其他方面的工作,比如:让问答系统的回答更加拟人化(用户情感分析)。
二、搭建基于检索的问答系统
基于检索的问答系统,其主要实现是将用户的输入问题与数据库中的问题进行相似度匹配,将相似度最高的问题的答案返回给用户(也可以返回topn个最相似的问题,待用户选择最相似度的问题后,返回给用户答案)
数据介绍:
dev-v2.0.json: 这个数据包含了问题和答案的pair, 以JSON格式存在。
打印如下:
442
Out[23]:
{'paragraphs': [{'context': 'Beyoncé Giselle Knowles-Carter (/biːˈjɒnseɪ/ bee-YON-say) (born September 4, 1981) is an American singer, songwriter, record producer and actress. Born and raised in Houston, Texas, she performed in various singing and dancing competitions as a child, and rose to fame in the late 1990s as lead singer of R&B girl-group Destiny\'s Child. Managed by her father, Mathew Knowles, the group became one of the world\'s best-selling girl groups of all time. Their hiatus saw the release of Beyoncé\'s debut album, Dangerously in Love (2003), which established her as a solo artist worldwide, earned five Grammy Awards and featured the Billboard Hot 100 number-one singles "Crazy in Love" and "Baby Boy".','qas': [{'answers': [{'answer_start': 269, 'text': 'in the late 1990s'}],'id': '56be85543aeaaa14008c9063','is_impossible': False,'question': 'When did Beyonce start becoming popular?'},{'answers': [{'answer_start': 207, 'text': 'singing and dancing'}],'id': '56be85543aeaaa14008c9065','is_impossible': False,'question': 'What areas did Beyonce compete in when she was growing up?'},{'answers': [{'answer_start': 526, 'text': '2003'}],'id': '56be85543aeaaa14008c9066','is_impossible': False,'question': "When did Beyonce leave Destiny's Child and become a solo singer?"},{'answers': [{'answer_start': 166, 'text': 'Houston, Texas'}],'id': '56bf6b0f3aeaaa14008c9601','is_impossible': False,'question': 'In what city and state did Beyonce grow up? '},{'answers': [{'answer_start': 276, 'text': 'late 1990s'}],'id': '56bf6b0f3aeaaa14008c9602','is_impossible': False,'question': 'In which decade did Beyonce become famous?'},{'answers': [{'answer_start': 320, 'text': "Destiny's Child"}],'id': '56bf6b0f3aeaaa14008c9603','is_impossible': False,'question': 'In what R&B group was she the lead singer?'},{'answers': [{'answer_start': 505, 'text': 'Dangerously in Love'}],'id': '56bf6b0f3aeaaa14008c9604','is_impossible': False,'question': 'What album made her a worldwide known artist?'},{'answers': [{'answer_start': 360, 'text': 'Mathew Knowles'}],'id': '56bf6b0f3aeaaa14008c9605','is_impossible': False,'question': "Who managed the Destiny's Child group?"},{'answers': [{'answer_start': 276, 'text': 'late 1990s'}],'id': '56d43c5f2ccc5a1400d830a9','is_impossible': False,'question': 'When did Beyoncé rise to fame?'},{'answers': [{'answer_start': 290, 'text': 'lead singer'}],'id': '56d43c5f2ccc5a1400d830aa','is_impossible': False,'question': "What role did Beyoncé have in Destiny's Child?"},{'answers': [{'answer_start': 505, 'text': 'Dangerously in Love'}],'id': '56d43c5f2ccc5a1400d830ab','is_impossible': False,'question': 'What was the first album Beyoncé released as a solo artist?'},{'answers': [{'answer_start': 526, 'text': '2003'}],'id': '56d43c5f2ccc5a1400d830ac','is_impossible': False,'question': 'When did Beyoncé release Dangerously in Love?'},{'answers': [{'answer_start': 590, 'text': 'five'}],'id': '56d43c5f2ccc5a1400d830ad','is_impossible': False,'question': 'How many Grammy awards did Beyoncé win for her first solo album?'},{'answers': [{'answer_start': 290, 'text': 'lead singer'}],'id': '56d43ce42ccc5a1400d830b4','is_impossible': False,'question': "What was Beyoncé's role in Destiny's Child?"},{'answers': [{'answer_start': 505, 'text': 'Dangerously in Love'}],'id': '56d43ce42ccc5a1400d830b5','is_impossible': False,'question': "What was the name of Beyoncé's first solo album?"}]},......
1.导入所需的库
import json
from matplotlib import pyplot as plt
import re
import string
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from queue import PriorityQueue as PQueue
from functools import reduce2. 读取文件
读取训练文件,把内容分别写到两个list里(一个list对应问题集,另一个list对应答案集)
def read_corpus():"""读取给定的语料库,并把问题列表和答案列表分别写入到 qlist, alist 里面。 在此过程中,不用对字符换做任何的处理qlist = ["问题1", “问题2”, “问题3” ....]alist = ["答案1", "答案2", "答案3" ....]务必要让每一个问题和答案对应起来(下标位置一致)"""qlist = []alist = []with open("data/train-v2.0.json", 'r') as path:fileJson = json.load(path)json_list=fileJson['data']for data_dict in json_list:for data_key in data_dict:if data_key=="paragraphs":paragraphs_list=data_dict[data_key]for content_dict in paragraphs_list:for qas_key in content_dict:if "qas" == qas_key:qas_list = content_dict[qas_key]for q_a_dict in qas_list:if len(q_a_dict["answers"]) > 0:qlist.append(q_a_dict["question"])alist.append(q_a_dict["answers"][0]["text"])print("qlist len:" + str(len(qlist)))print("alist len:" + str(len(alist)))assert len(qlist) == len(alist) # 确保长度一样return qlist, alist3.理解数据(可视化分析/统计信息)
对数据的理解是任何AI工作的第一步,需要充分对手上的数据有个更直观的理解。
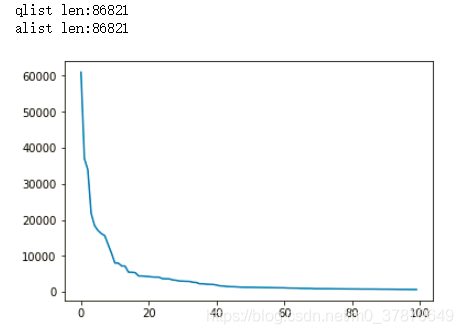
def data_analysis(data):# TODO: 统计一下在qlist 总共出现了多少个单词? 总共出现了多少个不同的单词?# TODO: 统计一下qlist中每个单词出现的频率,并把这些频率排一下序,然后画成plot.qlist_word = []word_dic = {}for sentences in data:cur_word = sentences[:len(sentences) - 1].strip().split(" ")qlist_word += cur_wordfor word in cur_word:if word in word_dic.keys():word_dic[word] = word_dic[word] + 1else:word_dic[word] = 1#统计一下在qlist总共出现了多少个不同单词word_total = len(set(qlist_word)) # 53306word_dic=sorted(word_dic.items(), key = lambda x:x[1], reverse = True)# 出现频率前100的单词进行可视化x = range(100)y = [c[1] for c in word_dic[:100]]plt.figure()plt.plot(x, y)plt.show()qlist, alist = read_corpus()
data_analysis(qlist)打印如下:
4.文本预处理
对于qlist, alist做文本预处理操作。 可以考虑以下几种操作:
停用词过滤 (去网上搜一下 “english stop words list”,会出现很多包含停用词库的网页,或者直接使用NLTK自带的)
转换成lower_case: 这是一个基本的操作
去掉一些无用的符号: 比如连续的感叹号!!!, 或者一些奇怪的单词。
去掉出现频率很低的词:比如出现次数少于10,20…
对于数字的处理: 分词完只有有些单词可能就是数字比如44,415,把所有这些数字都看成是一个单词,这个新的单词我们可以定义为 “#number”
stemming(利用porter stemming): 因为是英文,所以stemming也是可以做的工作
请注意,不一定要按照上面的顺序来处理,具体处理的顺序思考一下,然后选择一个合理的顺序
def data_pre(temp_list):stop_words = set(stopwords.words('english'))stemmer = PorterStemmer()pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))#正则匹配特殊符号word_list_list = []word_dict = {}for line in temp_list:temp_word_list = []sentence = pattern.sub("", line) # 1.去掉一些无用的符号sentence = sentence.lower() # 2.转换成lower_caseword_list = sentence.split()for word in word_list:if word not in stop_words: # 3.过滤停用词word = "#number" if word.isdigit() else word # 4.数字特殊处理word = stemmer.stem(word) # 5.词干提取(包括词形还原)word_dict[word] = word_dict.get(word, 0) + 1temp_word_list.append(word)word_list_list.append(temp_word_list)return word_dict, word_list_list#6. 去掉出现频率很低的词
def filter_words(in_list=[], in_dict={}, lower=0, upper=0):word_list = []for key, val in in_dict.items():if val >= lower and val <= upper:word_list.append(key)new_list = []for line in in_list:words = [w for w in line if w in word_list]new_list.append(' '.join(words))return new_list5.文本表示
这里使用Tf-idf的表示方法,这里使用sklearn里面提供的包。
from sklearn.feature_extraction.text import TfidfVectorizervectorizer = TfidfVectorizer() # 定一个tf-idf的vectorizer
X = vectorizer.fit_transform(qlist) # 结果存放在X矩阵
6.对于用户的输入问题,找到相似度TOP5高的问题,并把5个潜在的答案做返回
def top5results(input_q):"""给定用户输入的问题 input_q, 返回最有可能的TOP 5问题。这里面需要做到以下几点:1. 对于用户的输入 input_q 首先做一系列的预处理,然后再转换成tf-idf向量(利用上面的vectorizer)2. 计算跟每个库里的问题之间的相似度3. 找出相似度最高的top5问题的答案"""stop_words = set(stopwords.words('english'))stemmer = PorterStemmer()pattern = re.compile('[{}]'.format(re.escape(string.punctuation))) # 正则匹配特殊符号input_q = pattern.sub("", input_q) # 1.去掉一些无用的符号input_q = input_q.lower() # 2.转换成lower_caseword_list = input_q.split()temp_word_list=[]for word in word_list:if word not in stop_words: # 3.过滤停用词word = "#number" if word.isdigit() else word # 4.数字特殊处理word = stemmer.stem(word) # 5.词干提取(包括词形还原)temp_word_list.append(word)new_input=' '.join(temp_word_list)vectorizer = TfidfVectorizer(smooth_idf=False) # 定义一个tf-idf的vectorizerX = vectorizer.fit_transform(new_qlist) # 结果存放在X矩阵#注意fit_transform是训练,transform是加入新数据input_vec = vectorizer.transform([new_input])# 结果存放在X矩阵res = cosine_similarity(input_vec, X)[0]#即输出前k个高频词使用优先队列,优化速度pq = PQueue()for i, v in enumerate(res):pq.put((1.0 - v, i))top_idxs = [] # top_idxs存放相似度最高的(存在qlist里的)问题的下表for i in range(5):top_idxs.append(pq.get()[1])print(top_idxs) # top_idxs存放相似度最高的(存在qlist里的)问题的下表# hint: 利用priority queue来找出top results. 思考为什么可以这么做?# 因为优先级队列的第一个值可以是浮点数,所以用1.0-相似度,就可以转换为优先级result = [alist[i] for i in top_idxs]return result # 返回相似度最高的问题对应的答案,作为TOP5答案qlist, alist = read_corpus()
q_dict, q_list_list = data_pre(qlist)
new_qlist = filter_words(q_list_list, q_dict, 2, 1000)print(top5results("when did Beyonce start becoming popular?"))
print(top5results("what languge does the word of 'symbiosis' come from"))打印如下:
qlist len:86821
alist len:86821
[0, 60835, 39267, 23136, 693]
['in the late 1990s', 'mandolin-based guitar programs', 'Particularly since the 1950s, pro wrestling events have frequently been responsible for sellout crowds at large arenas', 'early DJs creating music in their own homes', 'Agnèz Deréon']
[7786, 41967, 8154, 27470, 7844]
['Greek', 'living together', 'Persian and Sanskrit', '1570s', 'the evolution of all eukaryotes']
7.使用倒排表的方法进行优化
上面的算法,一个最大的缺点是每一个用户问题都需要跟库里的所有的问题都计算相似度。假设我们库里的问题非常多,这将是效率非常低的方法。 这里面一个方案是通过倒排表的方式,先从库里面找到跟当前的输入类似的问题描述。然后针对于这些candidates问题再做余弦相似度的计算。这样会节省大量的时间。
基于倒排表的优化。在这里,我们可以定义一个类似于hash_map, 比如 inverted_index = {}, 然后存放包含每一个关键词的文档出现在了什么位置,也就是,通过关键词的搜索首先来判断包含这些关键词的文档(比如出现至少一个),然后对于candidates问题做相似度比较。
from functools import reduceinverted_idx = {} # 定一个一个简单的倒排表
for i in range(len(qlist)):for word in qlist[i].split():if word in inverted_idx:inverted_idx[word].append(i)else:inverted_idx[word] = [i]for key in inverted_idx:inverted_idx[key] = sorted(inverted_idx[key])# 求两个set的交集
def intersections(set1, set2):return set1.intersection(set2)def top5results_invidx(input_q):"""给定用户输入的问题 input_q, 返回最有可能的TOP 5问题。这里面需要做到以下几点:1. 利用倒排表来筛选 candidate2. 对于用户的输入 input_q 首先做一系列的预处理,然后再转换成tf-idf向量(利用上面的vectorizer)3. 计算跟每个库里的问题之间的相似度4. 找出相似度最高的top5问题的答案"""# 处理输入字符串stop_words = set(stopwords.words('english'))stemmer = PorterStemmer()pattern = re.compile('[{}]'.format(re.escape(string.punctuation))) # 正则匹配特殊符号sentence = pattern.sub("", input_q)sentence = sentence.lower()word_list = sentence.split()result_list = []for word in word_list:if word not in stop_words:word = "#number" if word.isdigit() else wordword = stemmer.stem(word)result_list.append(word)# 找到倒排表中相关的索引,用于答案的候选集candidate_list = []for word in result_list:if word in inverted_idx:idx_list = inverted_idx[word]candidate_list.append(set(idx_list))# 候选问题的索引# print(candidate_list)candidate_idx = list(reduce(intersections, candidate_list))input_seg = ' '.join(result_list)vectorizer = TfidfVectorizer(smooth_idf=False) # 定义一个tf-idf的vectorizerX = vectorizer.fit_transform(new_qlist) # 结果存放在X矩阵input_vec = vectorizer.transform([input_seg])# 计算所有候选索引中的相似度similarity_list = []for i in candidate_idx:similarity = cosine_similarity(input_vec, X[i])[0]similarity_list.append((i, similarity[0]))res_sorted = sorted(similarity_list, key=lambda k: k[1], reverse=True)print(type(res_sorted))# 根据索引检索top 5答案answers = []i = 0for (idx, score) in res_sorted:if i < 5:answer = alist[idx]answers.append(answer)i += 1return answers
8.文本表示优化:使用词向量表示文本
上面所用到的方法论是基于词袋模型(bag-of-words model)。这样的方法论有两个主要的问题:1. 无法计算词语之间的相似度 2. 稀疏度很高。 在2.7里面我们 讲采用词向量作为文本的表示。词向量方面需要下载: https://nlp.stanford.edu/projects/glove/ (下载glove.6B.zip),并使用d=100的词向量(100维)。
读取glove.6B
读取每一个单词的嵌入。这个是 D*H的矩阵,这里的D是词典库的大小, H是词向量的大小。 这里面我们给定的每个单词的词向量,那句子向量怎么表达?其中,最简单的方式 句子向量 = 词向量的平均(出现在问句里的), 如果给定的词没有出现在词典库里,则忽略掉这个词。
def load_glove(path):#第一元素存储全为0的向量,代表词典里不存在的vocab = {}embedding = []vocab["UNK"] = 0embedding.append([0] * 100)with open(path, 'r', encoding='utf8') as f:i = 1for line in f:row = line.strip().split()vocab[row[0]] = iembedding.append(row[1:])i += 1return vocab, embedding
9.对于用户的输入问题,找到相似度TOP5高的问题,并把5个潜在的答案做返回
def top5results_emb(input_q=''):"""给定用户输入的问题 input_q, 返回最有可能的TOP 5问题。这里面需要做到以下几点:1. 利用倒排表来筛选 candidate2. 对于用户的输入 input_q,转换成句子向量3. 计算跟每个库里的问题之间的相似度4. 找出相似度最高的top5问题的答案"""path = "data/glove.6B.100d.txt"# vacab为词典库,embedding为len(vacab)*100的矩阵。vocab, embedding= load_glove(path)stop_words = set(stopwords.words('english'))pattern = re.compile('[{}]'.format(re.escape(string.punctuation)))sentence = pattern.sub("", input_q)sentence = sentence.lower()word_list = sentence.split()result_list = []for word in word_list:if word not in stop_words:word = "#number" if word.isdigit() else wordresult_list.append(word)input_q = " ".join(result_list)qlist, alist = read_corpus()q_dict, q_list_list = data_pre(qlist)new_qlist = filter_words(q_list_list, q_dict, 2, 1000)inverted_idx = {} # 定一个一个简单的倒排表for i in range(len(new_qlist)):for word in new_qlist[i].split():if word in inverted_idx:inverted_idx[word].append(i)else:inverted_idx[word] = [i]for key in inverted_idx:inverted_idx[key] = sorted(inverted_idx[key])candidates = []for word in result_list:if word in inverted_idx:ids = inverted_idx[word]candidates.append(set(ids))candidate_idx = list(reduce(intersections, candidates)) # 候选问题索引input_q_vec=word_to_vec(input_q,vocab, embedding)scores = []for i in candidate_idx:vec = word_to_vec(new_qlist[i], vocab, embedding)score = cosine_similarity([input_q_vec, vec])[0]scores.append((i, score[1]))scores_sorted = sorted(scores, key=lambda k: k[1], reverse=True)# 根据索引检索top 5答案answers = []i = 0for (idx,score) in scores_sorted:if i < 5:answer = alist[idx]answers.append(answer)i += 1return answersprint(top5results_emb("when did Beyonce start becoming popular?"))
print(top5results_emb("what languge does the word of 'symbiosis' come from"))
print(top5results_emb("In her music, what are some?"))
三、其他相似度计算
word2vec、WMD、doc2vec等
优化,使用ES,自带的TF-IDF
调试问题 1:TypeError: 'float' object is not iterable
1.data文件中:
def split_word(self, query):"""结巴分词,去除停用词:param query: 待切问题:param stop_list: 停用词表:return:"""words = jieba.cut(query)result = ' '.join([word for word in words if word not in self.stop_list])return result如上代码修改为:
def split_word(self, query):"""结巴分词,去除停用词:param query: 待切问题:param stop_list: 停用词表:return:"""words = jieba.cut(query)result = ' '.join([str(word) for word in words if word not in self.stop_list])return result发现:
则Wmd_model.py文件中出现如下问题:
print(self.content[:2])print(type(w2v_size))self.w2v_model = Word2Vec(self.content, workers=3, size=w2v_size)w2v_end = time()print('w2v took %.2f seconds to run.' % (w2v_end - w2v_start))报错:TypeError: 'float' object is not iterable
原因是
self.content中的元素有的是float类型。
self.content的生成是在如下,因此,说明word中有float类型数据,因此,需要使用str转换。
result = ' '.join([word for word in words if word not in self.stop_list])
相关参考:
问答系统设计的一些思考: https://www.jianshu.com/p/13f0f32a6dab
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!