基于医疗领域知识图谱的问答系统
该项目是基于医疗领域知识图谱的问答系统,并基于此知识图谱搭建问答系统实现自动问题解析和回答。相比于lhy的项目 (https://github.com/zhihao-chen/QASystemOnMedicalKG) ,
本项目对实体提取在原有硬匹配的基础上增加了近似匹配,对于意图识别,则采用朴素贝叶斯分类进行意图的分类,并进一步进行模板匹配。
本文参考:[https://github.com/zhihao-chen/QASystemOnMedicalKG](https://github.com/zhihao-chen/QASystemOnMedicalKG)
实体提取
实体提取在原有硬匹配的基础上,进行相似匹配,如果硬匹配没有结果,则进一步进行相似度匹配。相似匹配则通过求解输入语句词组与实体特征词间的字重叠率、词向量余弦相似度和DP编辑距离三个指标的平均值,作为与实体特征词的相似度,选取相似度最大且大于0.7的实体特征词作为输入语句的实体提取结果。主要技术点有基于词向量的余弦相似度计算和DP编辑距离。
系统框架如下:
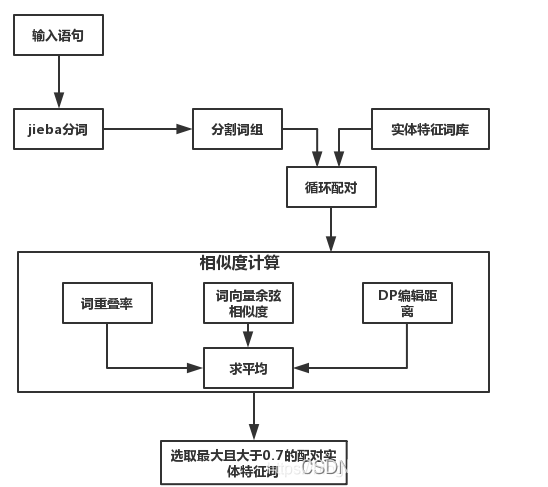
(1)字重叠率
对于选取的输入语句分割词和实体特征库特征词,计算输入语句分割词的字与特征词的字重叠比例。
// An highlighted block
c = len(set(entity+word))
for w in word: #word是一个词,w表示一个字if w in entity: #entity是一个词,某类实体的某一个特征词 sim_num += 1
if sim_num != 0:score1 = sim_num / c # overlap scoretemp.append(score1);
(2)词向量余弦相似度
该指标主要利用gensim模块,通过构建语料库,采用word2vec生成词向量,然后基于word2vec,计算输入语句分割词和实体特征库特征词的余弦相似度。项目中没有给出语料库和word2vec生成词向量的训练过程,直接给出了word2vec模型,即merge_sgns_bigram_char300.txt。
相关资料见:用gensim学习word2vec - 刘建平Pinard - 博客园 (cnblogs.com)
gensim训练word2vec及相关函数与功能理解,gensim训练word2vec及相关函数与功能理解等
(3)DP编辑距离
def editDistanceDP(self, s1, s2):m = len(s1)n = len(s2) solution = [[0 for j in range(n + 1)] for i in range(m + 1)]for i in range(len(s2) + 1):solution[0][i] = i for i in range(len(s1) + 1):solution[i][0] = ifor i in range(1, m + 1):for j in range(1, n + 1):if s1[i - 1] == s2[j - 1]:solution[i][j] = solution[i - 1][j - 1]else:solution[i][j] = 1 + min(solution[i][j - 1], min(solution[i - 1][j], solution[i - 1][j - 1]))
return solution[m][n]
3. 意图分类
意图分类则采用朴素贝叶斯机器学习方法,实际包括特征提取、模型训练、意图预测三部分,项目仅给出了部分特征提取和意图预测代码,没有给出tfidf特征训练和分类模型训练内容,直接给出了模型。
(1)特征提取
特征包括tfidf特征和其他类特征,其中其他类特征根据问题特征词在问句中出现的比例得到,tfidf特征则采用sklearn模块TfidfVectorizer模型,通过语料库训练得到。
sklearn: TfidfVectorizer 中文处理及一些使用参数,使用不同的方法计算TF-IDF值,使用scikit-learn tfidf计算词语权重。
(2)模型训练
基于语料库,标注10类意图训练数据库,采用朴素贝叶斯方法,基于提取特征,训练生成意图识别模型 Python机器学习 — 朴素贝叶斯算法(Naive Bayes)。
// An highlighted block
from sklearn.externals import joblib
import jieba
self.tfidf_model = joblib.load(self.tfidf_path)
self.nb_model = joblib.load(self.nb_path)
// 计算tfidf特征函数
def tfidf_features(self, text, vectorizer):jieba.load_userdict(self.vocab_path)words = [w.strip() for w in jieba.cut(text) if w.strip() and w.strip() not in self.stopwords]sents = [' '.join(words)]tfidf = vectorizer.transform(sents).toarray()return tfidf
// 计算其他特征函数
def other_features(self, text):features = [0] * 7 for d in self.disase_qwds:if d in text:features[0] += 1...m = max(features)n = min(features)normed_features = []if m == n:normed_features = featureselse:for i in features:j = (i - n) / (m - n)normed_features.append(j)
// 计算特征并合并特征
tfidf_feature = self.tfidf_features(question, self.tfidf_model)
other_feature = self.other_features(question)
m = other_feature.shape
other_feature = np.reshape(other_feature, (1, m[0]))
feature = np.concatenate((tfidf_feature, other_feature), axis=1)(3)意图预测
基于特征向量,直接用朴素贝叶斯模型进行预测。
from sklearn.externals import joblib
self.nb_model = joblib.load(self.nb_path)
predicted = self.model_predict(feature, self.nb_model)项目效果
以下两张图是系统实际运行效果:

项目运行方式
我的运行环境
1. 数据库:neo4j
2. 安装包地址:链接:https://pan.baidu.com/s/1JnZt690SkXyHBotBErHrPw?pwd=v18h
注意,neo4j 和JDK的版本是对应的
openjdk和neo4j的环境变量设置:将openjdk和neo4j的解压缩地址放入环境变量中 (参考:https://blog.csdn.net/qq_41744697/article/details/107747136)
3. 点击组合键:Windows+R,输入cmd,启动DOS命令行窗口,进入 neo4J 的bin 目录下,输入 neo4j.bat console,进入其浏览器(localhost:)
出现下图即为成功:

在浏览器中运行“http://localhost:7474/”,出现以下图片
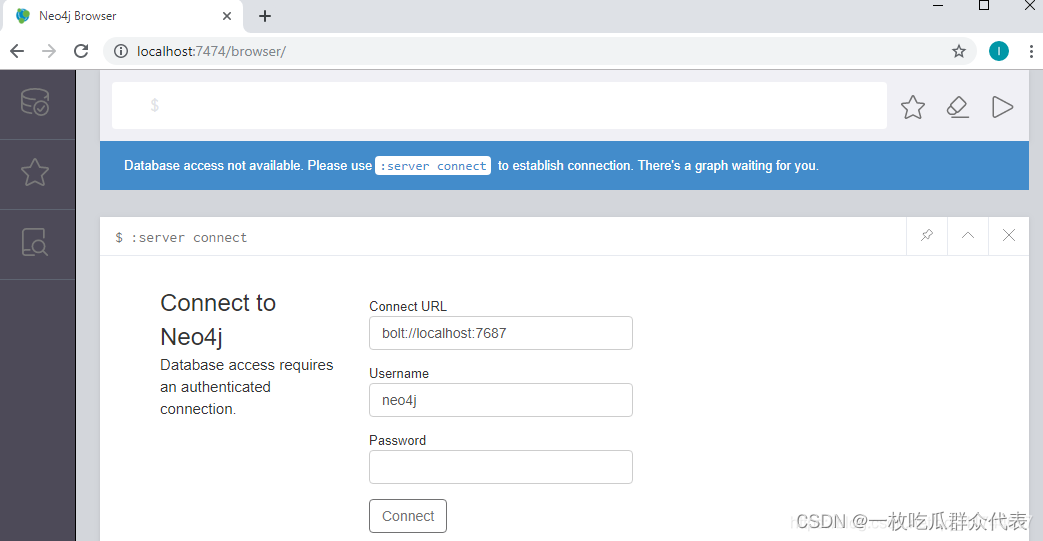
默认的host是bolt://localhost:7687,默认的用户是neo4j,默认的密码是:neo4j,第一次成功connect到Neo4j服务器之后,需要重置密码。
新建知识图谱
python 库安装
pip install py2neo==4.3.0 -i https://pypi.douban.com/simple
pandas
搭建知识图谱
python build_grapy.py。大概几个小时,耐心等待。
启动问答测试
安装库
sklearn(机器学习)、ahocorasick(树,安装时应该安装pyahocorasick)、pandas(数据处理)、numpy(矩阵运算)、jieba(中文分词)
from sklearn.externals import joblib 报错可参考 针对cannot import name ‘joblib’ from ‘sklearn.externals’_学渣研究僧3的博客-CSDN博客
准备数据:
预训练词向量介绍:[https://github.com/Embedding/Chinese-Word-Vectors](https://github.com/Embedding/Chinese-Word-Vectors)或https://pan.baidu.com/s/14JP1gD7hcmsWdSpTvA3vKA
下载地址:链接:https://pan.baidu.com/s/1zmcAM8AE_v6-6Pc2acHU7g?pwd=9dnr
启动问答测试:
python kbqa_test.py
注意修改search_answer.py中的用户名和密码,否则会报错
代码目录分析
data文件夹
- stop_words.utf8 过滤question中的停用词
- merge_sgns_bigram_char300.txt word2vec模型中用来计算相似度的预处理向量文件
- vocab.txt jieba库预加载词汇文件
- disease_vocab.txt 、 symptom_vocab.txt、 alias_vocab.txt、 complications_vocab.txt 模板匹配时使用的关键词
- disease.csv 提供训练所有的数据,使用pandas读取,neo4j配合ahocorasick建立知识图谱模型
model文件夹
model 文件夹
tfidf_model.m TF_IDF统计关键词模型
intent_reg_model.m 朴素贝叶斯模型(统计分类)
code 文件夹
kbqa_test.py 主代码
build_graph.py 建图
entity_extractor.py 分析question的实体、和实体关系、实体属性以及问题意图
search_answer.py 根据question提供的信息在图数据库中寻找答案
数据介绍
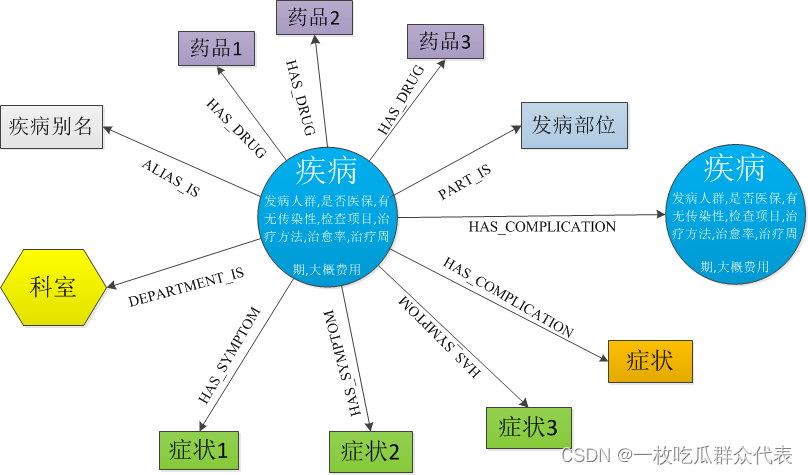
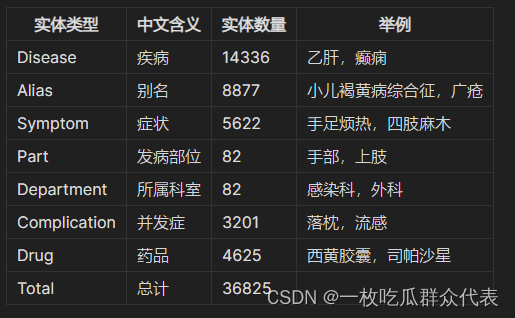
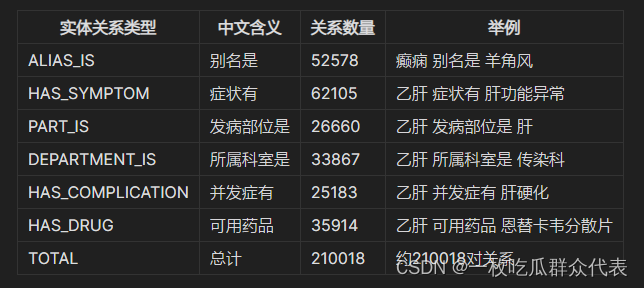
数据源:39健康网。包括15项信息,其中7类实体,约3.7万实体,21万实体关系。
本系统的知识图谱结构如下:
**1.1 知识图谱实体类型**
**1.2 知识图谱实体关系类型**
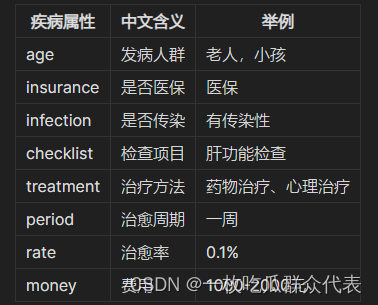
**1.3 知识图谱疾病属性**
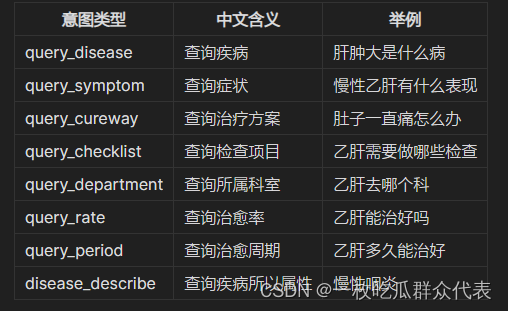
1.4 问题意图识别
基于特征词分类的方法来识别用户查询意图
总结
1、本项目构建简单,通过本项目能了解KBQA的工作流程。
2、本次通过手工标记210条意图分类训练数据,并采用朴素贝叶斯算法训练得到意图分类模型。其最佳测试效果的F1值达到了96.68%。选用NB的原因是通过与SVM训练效果比较后决定的。
3、不足之处:
- 训练数据还是太少,且对问题进行标注时易受主观意见影响。意图类别还是太少,本系统得到分类模型只能预测出上面设定的7类意图。
- 对于问题句子中有多个意图的情况只能预测出一类,今后有时间再训练多标签模型吧。
- 没有实现推理的功能,后续将采用多轮对话的方式来理解用户的查询意图。同时将对检索出的结果进行排序,可靠度高的排在前面。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!