数仓界的大神之Inmon数据仓库建设(3范式建模)
上一篇(最详细!深入浅出理解「3层6类」数据分层)我们把数仓的分层情况讲解清楚:数仓的背景、逻辑、应用等等。
有心的同学一定会问了,这些分层是谁制定的呢?有相关的标准吗?
想要了解这个问题,你要先了解两个人,Inmon和Kimball,这两位大师就像唐诗界的李白和杜甫,如果想要透彻了解清楚数仓,一定要了解下这两位大师的对数仓的建设和推动做了哪些事情。
了解大师最好的方式就是去阅读原著,由于今天的主角是Inmon大师,所以我精读他的著作《Building the data warehouse》。第一遍我看的是中文版本,但是很多精髓在翻译过程中有缺失,所以又去看了两遍原著。
一、Inmon对数仓的定义
数据仓库是在企业管理和决策中面向主题的、集成的、与时间相关的、不可修改的数据集合。
- 面向主题:按照特定的业务特点来决定,例如:对一个保险公司来说,问题是:汽车保险、健康保险等等;对公司来说,问题是:顾客、保险单、保费、索赔。不同类型的公司主题集合不同。
- 集成的(重点):最为重要,把各个操作系统汇集到数据仓库,要进行转换、格式化、重新排列、汇总等。进入数据仓库之前,需要消除不一致性,例如:有的性别维值是“男女”,有的是“f/m”。命名习惯、关键字结构、属性度量单位以及数据物理特点。
- 不可修改:操作系统环境一般是定期更新,数仓通常是批量载入与访问(一般不进行传统意义的更新)。数仓的载入是以静态快照进行。
- 随时间变化
在他的原著《Building the data warehouse》中,以上这些特征都是和传统的操作型环境对比而得出的特点。由于操作性环境不具备上述特征无法满足需求,所以inmon的数据仓库才得以应运而生。
二、Inmon模型实施步骤
整体过程抽象出来可以分为两步,分别是抽出(从操作型环境到数据仓库)和迁入(数据模型的建设)。
第1步:抽出——从操作型环境到数据仓库
这个过程简单来理解就是有很多熊猫分布在北京、天津、河北等地方,但是由于熊猫不适合生存在这些地方,需要把他们整体迁移到四川。第一步需要把熊猫们从现有地方抽出来。但在这个过程中会有很多问题,例如:熊猫长得比较像无法区分、熊猫的身高体重需要统一标准去度量,以便我们更高的去搬运。
回到我们真实的场景中,由于在抽出数据的过程中会遇到如下问题,需要重点去考虑:
- 命名规范:例如相同的数据以不同名字存在不同地方;相同数据在不同地方用相同方式标注;相同数据相同名字用了不同度量
- 编码规范:例如有的性别维值是“男女”,有的是“f/m;有的是cm,有的是英寸
- 存储适配:不同的操作系统有不同的格式存储,有的在DB2中,有的在VSAM中
所以相应的,我们需要去解决以下问题:
- 去除纯粹用于操作系统型环境中的数据
- 企业模型的关键字结构中增加时间元素
稳定性分析:根据各个属性是否经常变化,而把属性进行拆分,很少变化、不时变化、经常变化。
第2步:迁入——数据模型的建设
终于把熊猫们从各个地方抽离出来了,那么如何把他们迁入他们最需要去的四川呢?是囫囵吞枣把熊猫们塞到四川呢?还是要先对他们进行分类(幼崽熊猫、青年熊猫、老年熊猫)分别进行有针对性的管理呢?
数据建模分为三个层次:高层模型、中间层模型、底层模型。
(1)高层模型(实体关系)
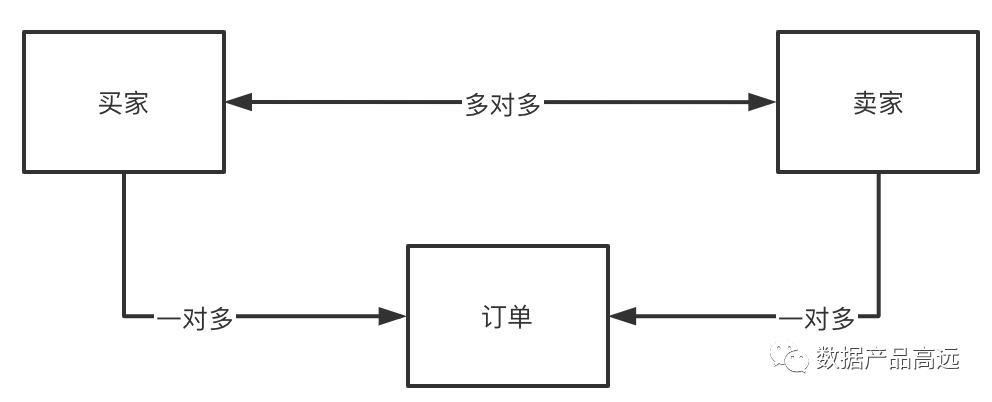
最抽象原始的一层,整个业务环境中最显著的关系。例如:我们现在要进行电商业务的实体关系抽象(买家、卖家、订单)。简化一下这个模型,并且表明实体之间的关系是:一对一、一对多、多对多。
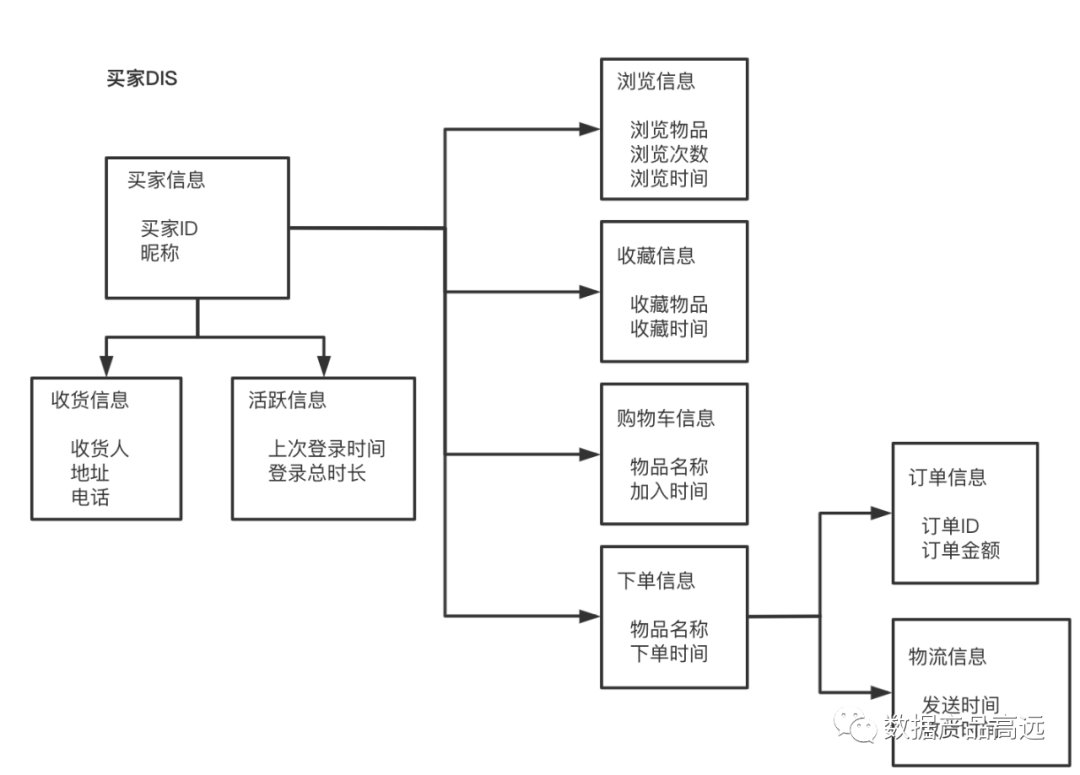
(2)中间层模型(数据项集或者DIS)
对高层模型中每个实体建一个中间层模型。即:上述模型中每一个实体(卖家、买家、订单)都对应一个DIS。中间层模型的4个基本构造:
- 主要数据分组:每个主题域有且只有一个主要数据分组。例如:下图中的买家信息
- 二级数据分组:每个主题域存在多次的属性。例如:下图中的收货信息
- 连接器:表示各个主题域之间关联的外键。
- 数据的类型:这里可以理解为某个分组中具体的分类。例如:买家信息可以拆分为他的浏览信息、收藏信息、购物车信息、下单信息。而下单信息又可以分为订单信息和物流信息
(3)底层模型(物理模型)
从中间层模型细化而来,有时也称物理模型为关系表。如果要搭建好这一层,你需要进行如下两步操作:
第一步:确定数据粒度。
啥是“数据的粒度”?数据粒度:数据最小的单元和数据汇总的单元,粒度越小表示越细,粒度越大表示越粗。例如:分钟级别的数据粒度一定比月级别的数据粒度小。
?为啥要预估数据的粒度?好处是啥?
要回答好这个问题,首先要回忆一下上篇文章讲解的「3层6类」数据分层。数据分层的方式有很多,针对不同体量、不同业务需求的数据会有不同的设计架构。并且数据粒度的预估同时可以带来如下的好处:
- 多视角分析数据:可以通过不同的粒度对数据进行分析。
- 低粒度数据灵活:有了最小粒度的数据,可以定位到根本的原因
- 高粒度数据概括:对于高度概括的数据,可以对整体业务进行把控
- 未知数据需求:对于未来的各种预测场景,可以通过所搭建的各类数据建设去进行解决

数据粒度的分档有哪些?
数据粒度的预估过程如下:对数仓中将来的数据行数和所需的DASD(直接存取存储设备)数进行粗略估算。分档可以按照如下进行分档:
- 少量数据:数据有10000行:啥粒度都可以,闭眼建粒度
- 中等数据:数据有10000000行:需要一个低粒度级别,例如:天和周比起来就是低粒度,秒和分钟比起来就是低粒度
- 大量数据:数据有100亿行:需要高粒度级+数据移到溢出存储器。
如何预估数据粒度?
对一个已知的表,预估的方式如下:
一张表的总空间=每行空间的大小*行数*时间+索引数据的大小*时间
总空间=表1的空间+表2的空间+….+表N的空间
每行空间的大小要分别从最大和最小考虑:
每行空间的大小 = [每行的最小估计值(下限),每行的最大估计值(上限)]
行数的预估,同样需要需要预估下时间范围内的最大和最小值:
行数=[最小行数(下限),最大行数(上限)]
时间范围可以暂且按照一年和五年这两个时间去预估考虑下。
注意:
溢出存储器中的数据。一年内总行数超过100000000,需小心设计,可以把一部分数据转移到溢出存储器中,从而应对数据量过大对性能造成的影响
确定粒度级别。首先要靠常识和行业处理经验进行合理的推断,接着要考虑对数据仓库获取数据的各个不同的体系结构实体的需求进行预测
第二步:考虑各种因素的核心物理I/O的使用情况。
物理IO就是将数据从外部存储器调入计算器,或将数据从计算器送到外部存储器。为啥要进行物理IO的考虑?
为什么要考虑这一步?
首先数据模型输出的都是表,每张表上承载的数据是有限的,所以需要通过表和表之间的关联进行关联。关联的方式就显得异常重要,如何设计表和表之间的链接,显得尤为重要。如果设计好了可以减少访问次数,降低IO;如果设计不好就会造成数据冗余,访问困难,会提升IO。
如何进行规范化从而降低物理IO?
数据在计算机和外部存储之间的传送以块为单位。从性能来看,物理IO重要是因为:存储器和计算器间的数据传输速度比计算器运算速度要慢2-3个数量级。物理IO是影响性能的主要因素。那么如何进行规范化降低物理IO,可以根据情况使用如下方式:
- 数据数组:数据放在数组的一行中,这样可以一次性去获取所需数据。
- 合并表:常用数据合并为一张表
- 选择冗余:特意引入冗余数据。常用信息散落各个表中,便于查看
- 分离数据:从访问次数这个角度把一张表中的数据分为高频数据和低频数据。分别建一张高频表和一张低频表
- 导出数据:生成一个字段来存储计算出的数据
- 预格式化
- 人工关系
- 预连接表
三、Inmon模型适用范围
Inmon模型的特点是:开发进度慢,实施成本高,建设周期很长。尤其是建设前期需要花费大量时间,后期投入相对比较小,对开发人员的要求比较高,一般会选择专家团队进行开发,维护起来相对而言比较容易。
适合对设计科学性和规范性较高的企业,在业务模式较固定的行业应用较好,比如金融、电信、石油等行业。
四、Inmon模型小结
优点:可以系统性的满足企业需求。因为Inmon采用的思路是自上而下的的建设方法,统一接入系统元数据,统一根据业务部门需求建设数据集市。因为建设较为规范,所以后期的维护成本非常小
缺点:瀑布式建设,前期建设人力(需要专家团队建设)、资源等投入很大。由于它的思路是从数据源头进行系统性的全面建设,一次性接入所有数据,打通所有数据,建好所有模型,所以建设的代价很大。
本文作者 @数据产品高远
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
