物流业务分析师的机器学习神器——Amazon SageMaker Canvas产品测评
随着数字化进程和人工智能的加速普及,企业人工智能(AI)和机器学习(ML)开发人员严重短缺,面对日益兴起的数据分析需求,亚马逊云科技推出了让人兴奋的机器学习新功能——Amazon SageMaker Canvas。
Amazon SageMaker Canvas进一步降低了机器学习使用门槛,运营分析师们掌握无需编码,即可使用点击式界面进行更准确的机器学习预测。这允许了任何有兴趣学习更多关于ML的人,可以免费尝试使用这项技术。
话不多说,下面我以物流垂直细分领域的常见数据,来体验下SageMaker Canvas的魅力!
一、分析场景和数据准备
1. 分析场景
分析每次的拣配数量与耗时和质量的相关性,本次从各环节规定时间内运送的箱数、各环节耗时、各环节箱质量状态这几个因子中找出关联。
2. 业务场景
模拟物流作业人员在规定时间内拣配不同数量的箱子,最终的完成率和质量是不一样的,分析找出单次作业最佳的拣配箱数。给业务运营同学在制定运送任务策略时,有数据可参考,做出更合理高效的作业策略。
分析的结论是否正确不重要,重要的是模拟出关联+探索不同角度的分析方法+不同工具的使用。
3. 数据来源
脱敏和虚拟的仓库内部物流数据。
4. 数据集定义
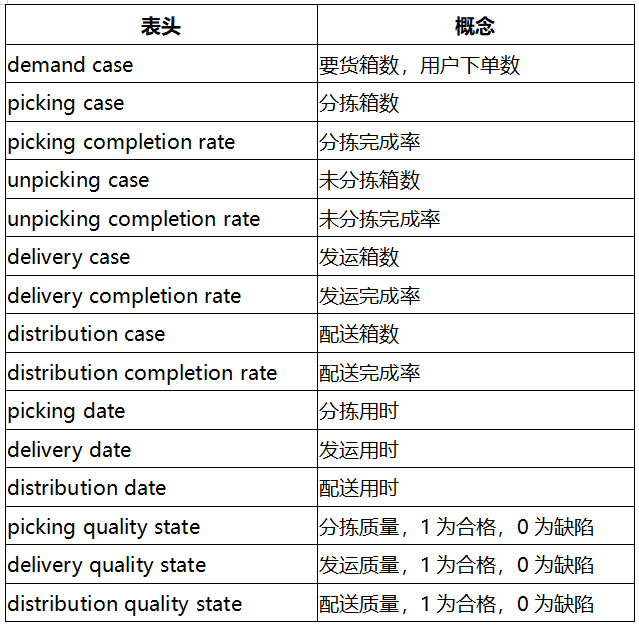
某厂仓库内的物流作业过程,有一段是“下发要货任务——分拣物品——发运物品——配送物品”,每个过程按要货箱数进行运送,每个运送环节按一定的时间截取当前的完成率,每次运送的用时情况、每个环节物品的质量情况,分别记录为以下内容:
二、测评体验步骤和数据分析结构
1. 登陆账号
注册和登录账号,在控制台搜索SageMaker,点击进入SageMaker控制台。

2. 导入和管理数据
在S3里新建储存桶,导入数据。导入格式注意是.csv,文档内不能有中文,刚开始体验时没注意格式规范,导入失败了几次。整体体验还是比较流畅的,第一次登陆和设置时需要多读指引文档和留意页面提示。

3. 启动应用程序
在SageMaker Domain里,找到Canvas(中文版为:画布) ,点击启动【画布】。
4. 部署
大概1分钟,后端应用部署完成。

5. 新建模型
在SageMaker Canvas里,点击【+New Model】。

6. 导入数据
导入刚才在 S3里的数据。
7. 选择目标列
本次分析我选了【demand case】为目标列,SageMaker Canvas会自动用适合的模型进行分析。
为什么选【demand case】为目标列呢,因为【demand case】是要货箱数,所有的物流作业,都基于【demand case】才有后续的过程、耗时、质量的分析。再例如,如果你的分析是广告投放、市场推广类的,目标列的可以是营销漏斗的第一层。

8. 选择有效字段进行分析
字段【NO.】是序号,与数据不相关,不勾选该字段,不然会影响预测;其他字段相关性较高,进行保留。
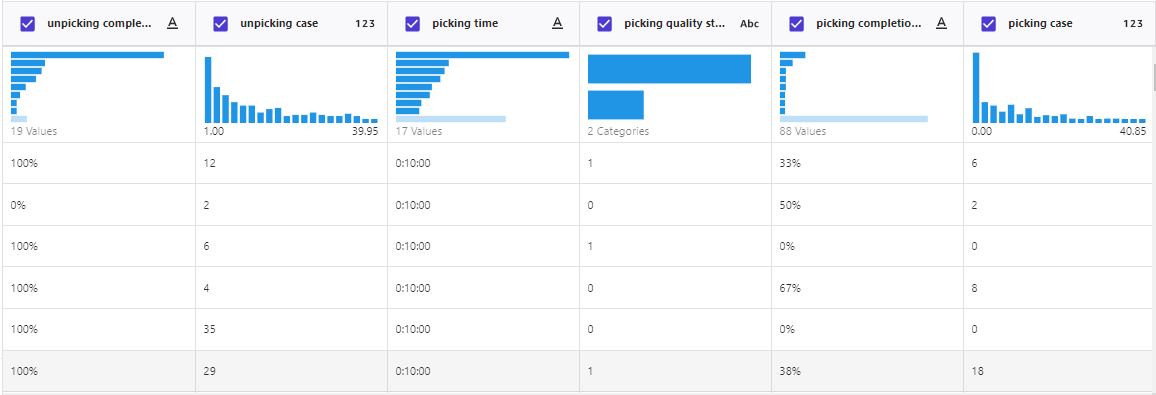

切换图标和列表样式,都可以进行有效字段的筛选。

9. 构建模型
我们来个简单的,点击【Preview model】,可查看模型的预测准确率。我这个模型准确率算蛮高的,达到了96.154%。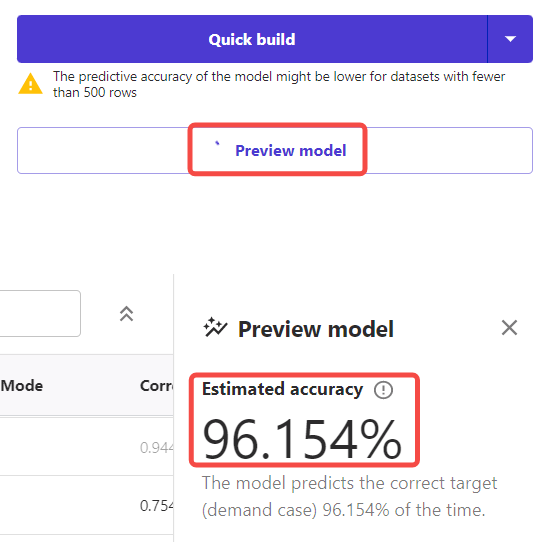
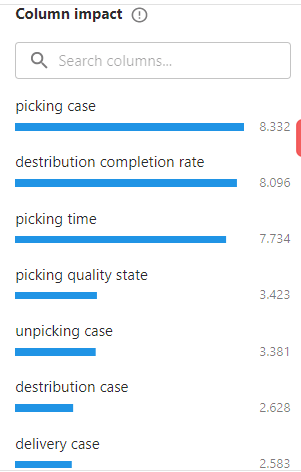
然后点击相应的列,可以查看每列数对预测结果的影响。
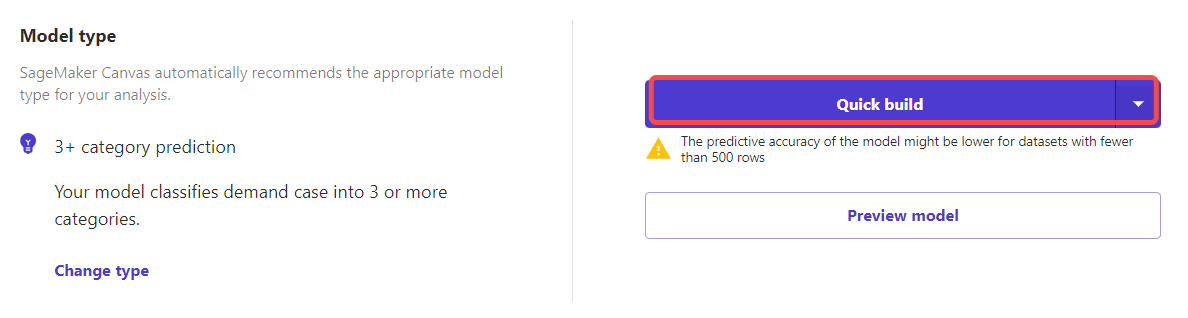
点击【Quick build】可以进行简易分析,还有标准模式,那个等待用时久一些。
下图展示了构建模型的过程。
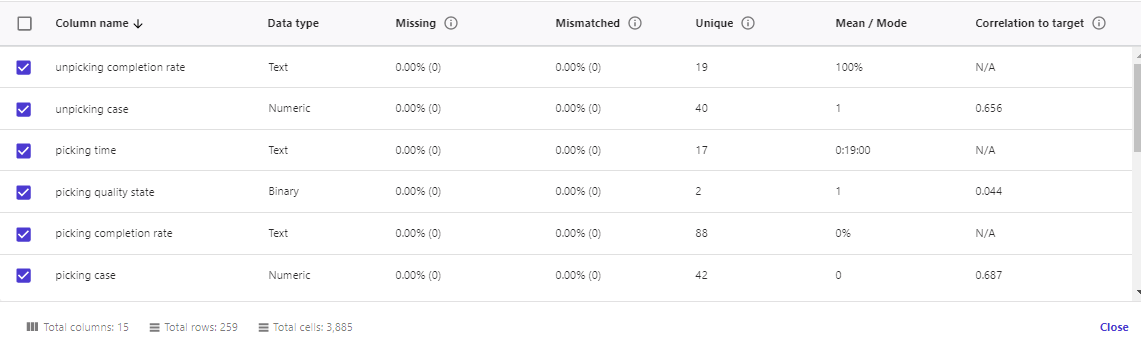
10. 模型评估
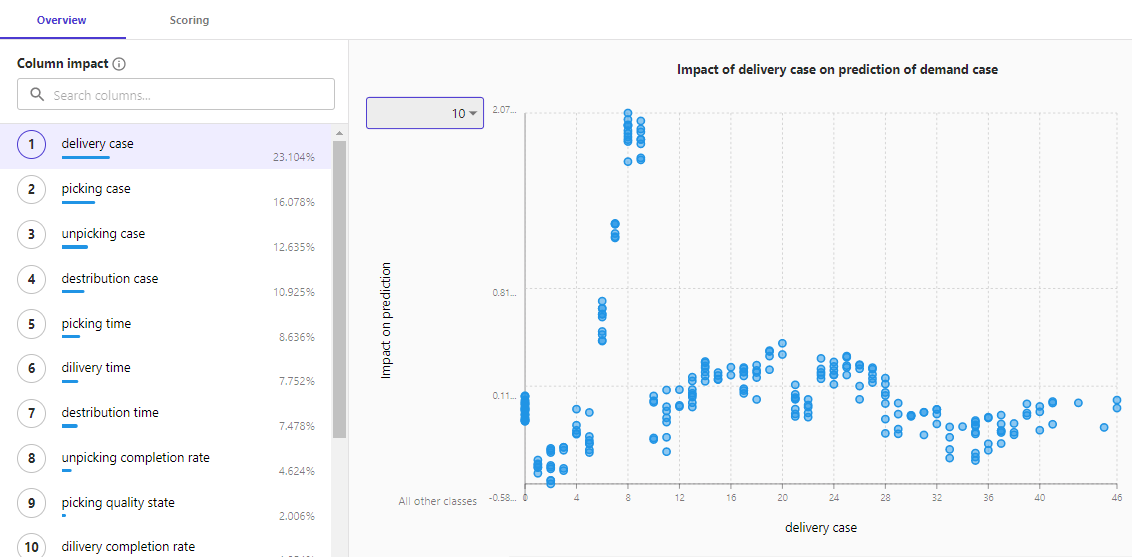
在使用模型对新数据进行预测前,还可以评估模型的执行情况、每列数据对预测结果产生的影响情况。下图展示了评估页面、评估得分以及不同列的影响情况。
还可以通过更改输入值,来查看预测值的变化情况。
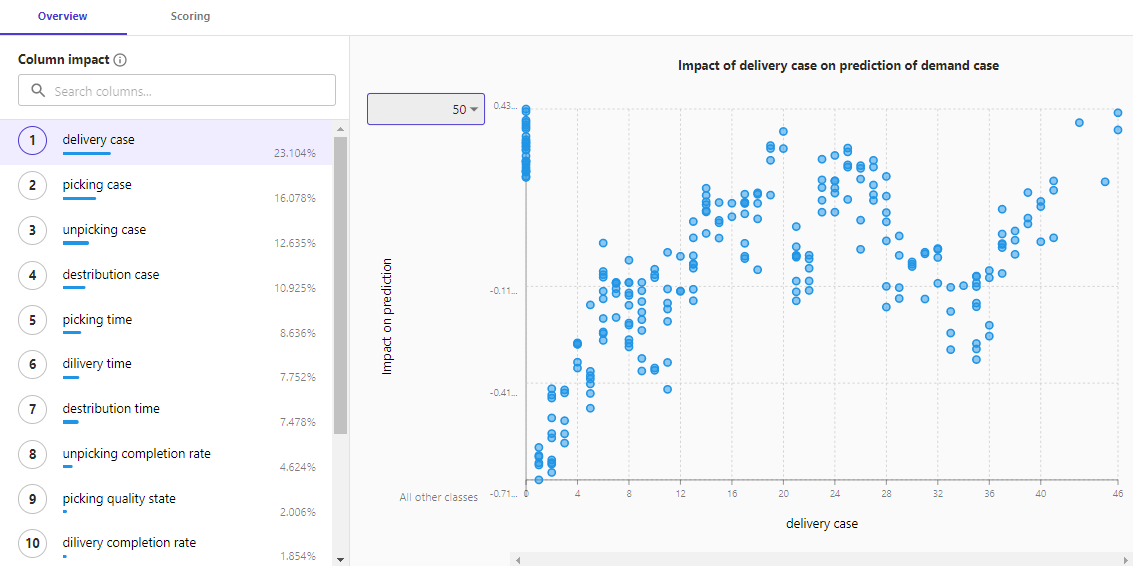
点击【Scoring】选项卡,查看模型预测的相关可视化结果和指标。
在箱数较少时,一次作业能完成的概率比较大,说明安排此类物流任务时,一次作业10箱或更少箱时,作业人员能比较顺手。
此时,运营分析师可以分析原因:可能是不同搬运工具和工具可承载情况的影响;找出可能的策略:增加不同类型的搬运工具、调整搬运组合可能对效率有正向影响等。

11. 做出预测
SageMaker Canvas有两种预测方案:
- Batch——针对整个数据集进行预测。
- Single——针对指定的单一数值进行预测。
我们分别来体验一下:
1)预测方案A:选择Batch进行预测
对于每一组预测,SageMaker Canvas返回如下内容:
- 预测得到的值;
- 预测的值为正确结果的可能性;
- 指定用于生成预测所用的数据集。

下载所有数据,可以再次进行二次分析(这也是体验最棒的模块):
例如:可能性超过98%的数据占到了总数据的86%。该数据匹配上作业ID和员工ID,即可分析出员工在不同时间里,不同作业数量情况下的作业效率、准确率的分布趋势,可以模拟出员工的作业稳定度。
又例如:可能性低于80%的数据里,这些数据匹配上作业工具ID,可以分析出员工在不同作业要求下,他们的工具的使用习惯分布的预测。
然后定位到优秀员工的工具使用习惯里,可以推荐出哪些工具更适合多采购,哪些工具可以加强培训等,哪些员工优秀的作业技巧多等。
可能性的数据可以匹配很多关联字段进行联想思考,为运营带来更多策略参考。

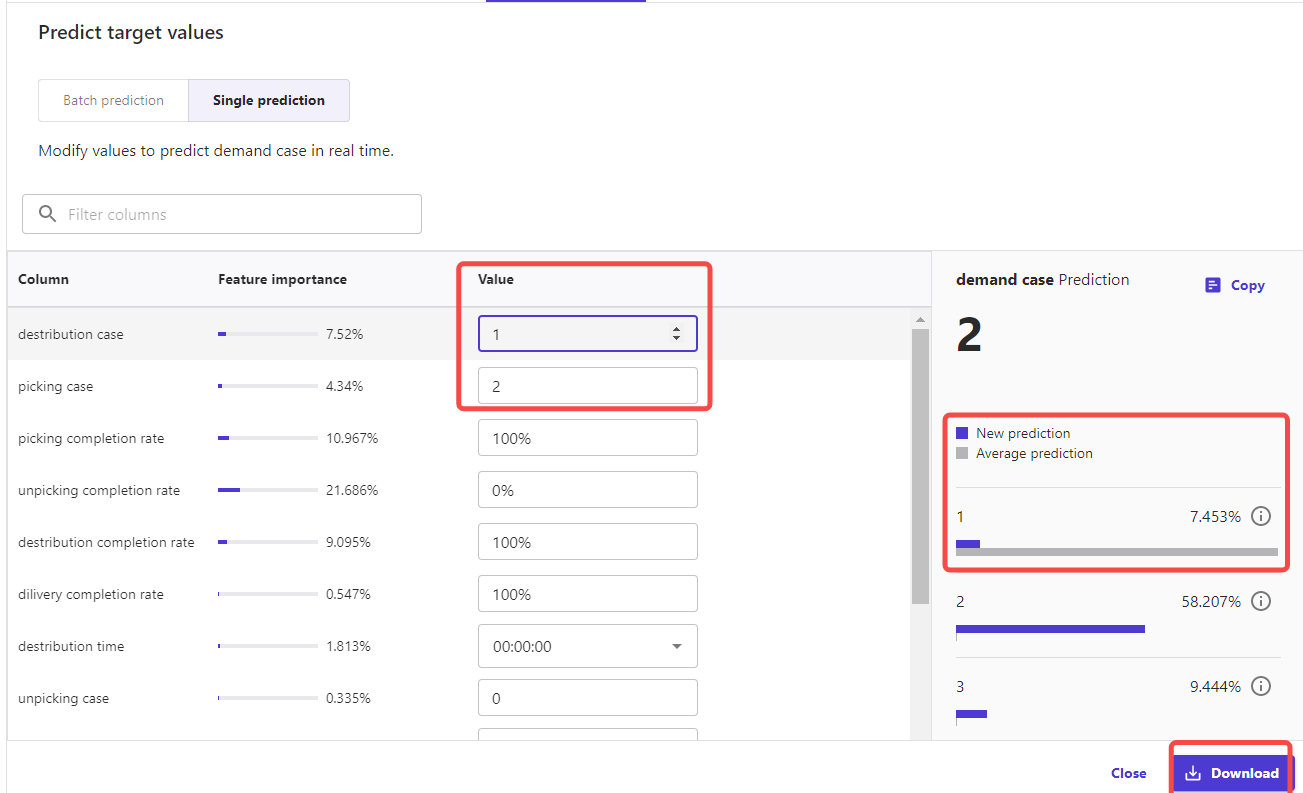
2)预测方案B:选择Single prediction进行预测
我更改了【distributioncase】的值,查看预测值相对于平均预测结果的变化情况。
点击【Update】 ,生成预测数据。

更改多个【Value】,预测值会有变动,可以直观地结果发现,处于流程上游的值变动的话,对最终数据影响更大(这也符合逻辑)。
综上,对于运营分析师来说,千头万绪的数据中,要分析出关键点和趋势,更推荐选择Batch,数据越多,干货越多,还有意想不到的内容。
三、总结一下
Amazon SageMaker Canvas提供了一个可视化的、 点击式的用户界面,让运营分析师可以轻松地生成预测,无需代码即可进行机器学习预测,简单方便好上手。
在数据的准备上,可以把结果字段,例如合格率、完成率、成功率、转化率、用量、耗时等进行整理,不要直接用过程数据,这样分析会更直接。
在数据分析上,可以与关联ID打通,在跨流程、跨主题的数据里,寻找关联点。这也是数据分析师提高数据敏感度、深入了解业务的过程了。
希望以上的体验分析,能给您带带一点点启发~
作者:Felice,某厂资深产品经理&产品运营
本文作者 @ToB Talk 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
