讯飞星火,AI燎原or熄灭?
讯飞星火6月9日迭代在即,一起来看看它是否能成为真的中文ChatGPT?本文将从多种指令角度,全面对比并评测下讯飞星火认知模型与ChatGPT的差异。
讯飞星火:继百度文心一言与众多国内AI平台发布后,讯飞星火发布的一款认知大模型,主要能力包括文本生成、语言理解、知识问答、逻辑推理、数学能力、代码能力、多模态能力。
笔者有幸成为讯飞星火体验的受邀人员,以普通工作者的身份,接下来分别从“文本生成、问答能力、语言翻译、逻辑推理、代码编写、数学计算能力”这几个方面进行评测对比。
(注:ChatGPT测试模型为3.5版本)
一、文本生成
讯飞星火在中文语言理解能力一定程度上是优于ChatGPT的。
可以看到下方对“七言绝句”的处理结果明显好于对方;但是对于日常工作的文本生成,ChatGPT文本更为自然。
对于文学小说故事的生成,讯飞理解更为透彻,而ChatGPT更像是生硬的文字联想堆积而成。整体上,中文的理解能力星火略胜一筹,但普通文本生成的自然度,ChatGPT大部分情况下更为优秀。
关于生成诗词与邮件的对比:


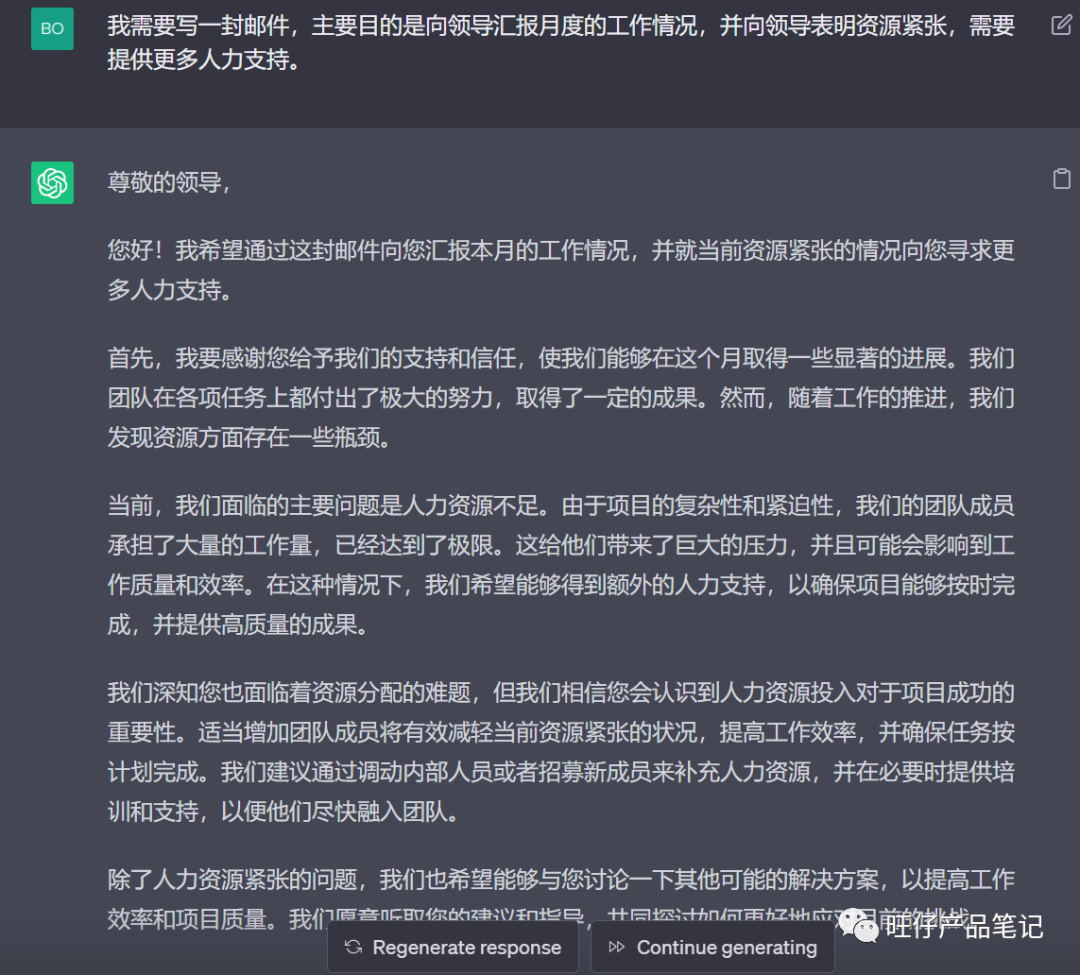
二、问答能力
- 工作上常规问题回答,讯飞星火更为通用化些,ChatGPT更为细致化,从匹配度上说,ChatGPT的参考价值会高些。
- 都能理解普通的上下文记录。ChatGPT的记忆能力略强。
- 中文常识问题,特别涉及到历史文化文学,星火对信息的检索与分析明显优于ChatGPT。
工作问题1:
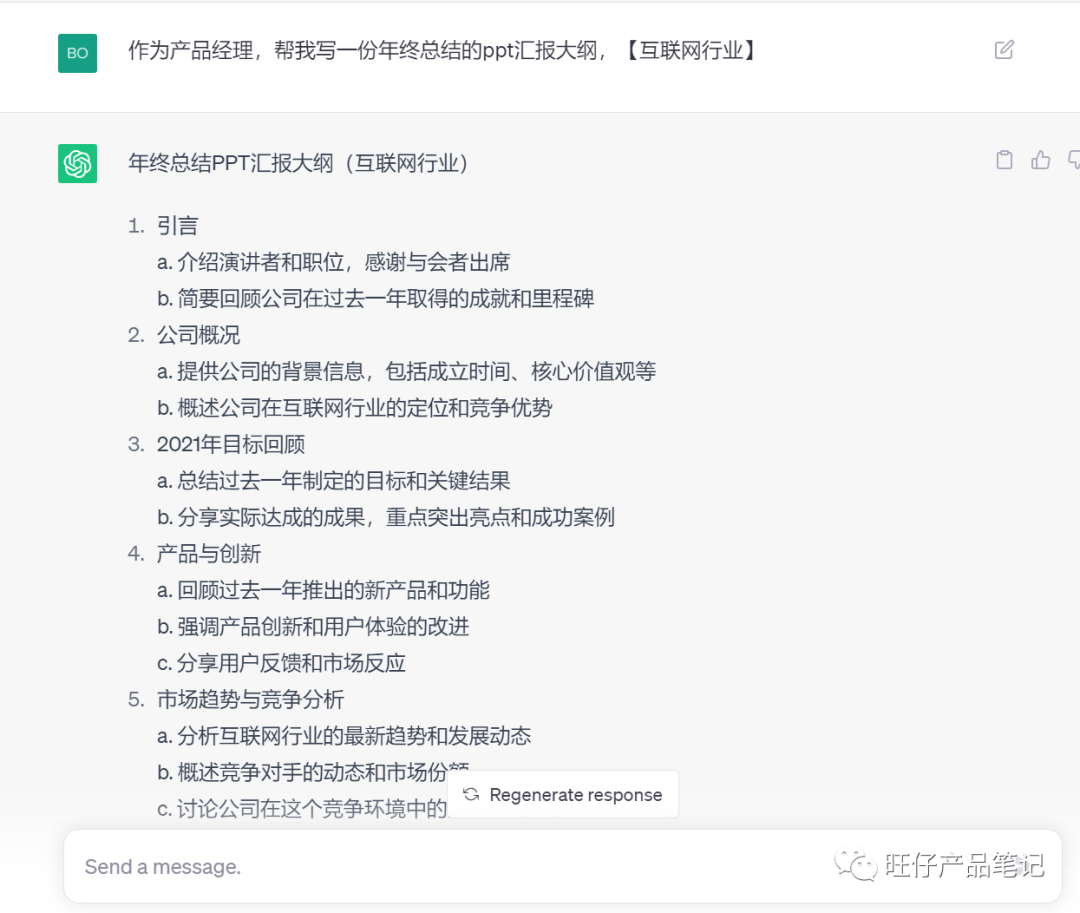
以下是讯飞星火:


工作问题2:

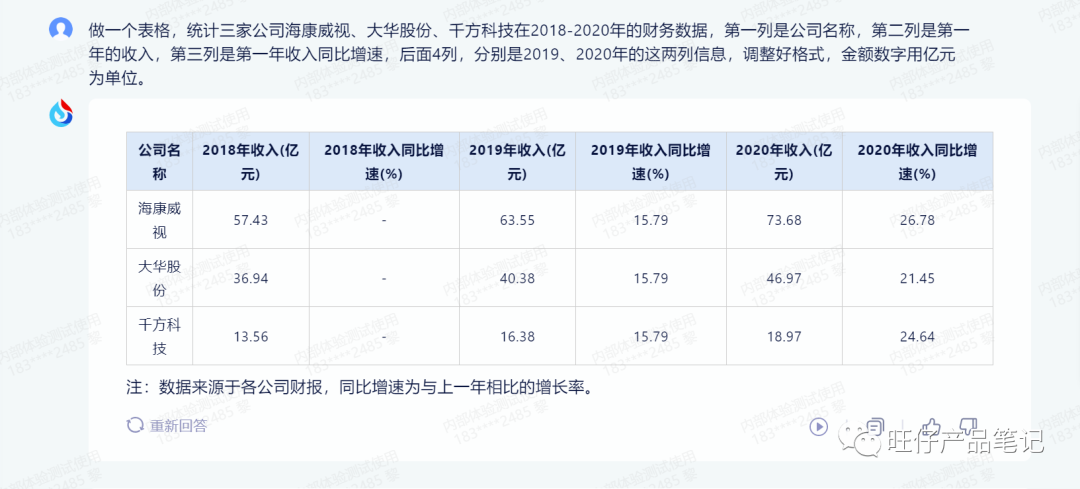
表格与数据检索的处理看起来星火更为厉害,获取了数据,但是数据并不真实,二次让它回答直接变成负增长。虽然ChatGPT无法获取准确数据,但至少不会提供假数据给用户,这点星火急需改进。

常识问题:
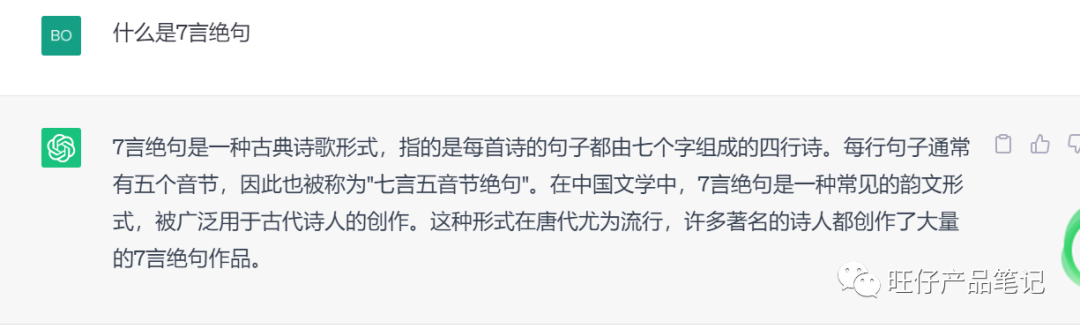





三、语言翻译
两者都具有直译能力,但是涉及到中文的理解力,星火翻译的更有感染力一些.
例如下图示例中,ChatGPT使用的是“sprouting up”-发芽;而星火使用的是“emerging in droves”-“涌现”,明显字意表达更为贴切。


四、逻辑推理
- 逻辑陷阱。例如询问“爸妈结婚为啥不叫我”类似问题时,国内大部分语言模型都无法正确处理,ChatGPT的答案更为全面,星火直接选择不答。
- 基础的逻辑能力两者都具备。对于复杂的逻辑题目,两者回答的出错率都很高
- 逻辑分析的广度、深度总体ChatGPT优于星火。但ChatGPT这类语言模型只要脱离了常见的“常见区域”基本都会犯错,只是在错误中,ChatGPT的错误概率或者出错的离谱度小于星火。
逻辑问题1:


正确答案:

逻辑问题2:

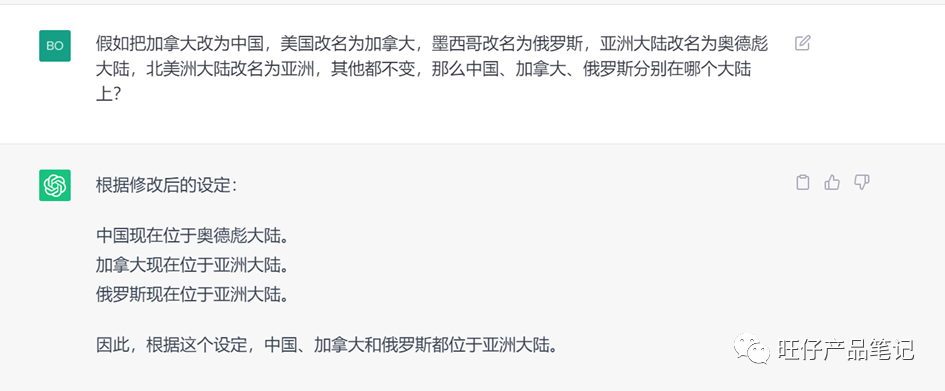
可以看到此时ChatGPT就已经出现错误了,但仍然有一定的正确率。
再看星火,从第二个问题开始,“cpu”就已经被干烧了。


五、代码编写
两者都具备一定的代码编写能力,包括代码编写、代码注释、代码debug能力。
由于笔者不是专业开发人员,不能实际验证是否能真实编译但是从外部资料和输出结果看,讯飞星火对比刚发布时代码编写能力有一定提升,找错的准确度也更好于之前。
咨询过很多开发同学,ChatGPT整体实力上还是比星火优秀。


以上是星火纠错的一个实例。
六、数学计算能力
对于数学计算,所有的语言模型都存在短板,高难度的数学问题是十分严谨的,只要其中一个步骤出错答案就会出错。
而计算机语言并不能人性化去理解一些含义,比如说可能会把“10”理解为“1”和“0”。而且大部分数学问题伴随着很多推理逻辑,计算机再处理这些“定量推理”问题是十分的棘手的。
可以看下星火的数学计算实例:



可以看到,星火连题意都没理解清楚,但ChatGPT至少举例了一种情况。
七、总结
在全面体验讯飞星火后,同时将其与其他产品在工作中使用的情况进行对比,我发现在问题处理和多次prompt的情况下,ChatGPT提供的答案在参考价值和回答广度方面仍然更优。
但作为国内的AI模型,自从百度文心一言以来,讯飞星火目前是我使用过的最好、最流畅的产品。可以说它完全配得上“星星之火”的称号。
然而,与OpenAI的技术相比,仍存在一定差距。同时,作为生产力工具,它的实用性稍弱一些。但在中文语言理解和特定常识问题方面,它具有一定的优势。
客观地说,讯飞已经取得了很大的进步,希望国内的互联网科技公司能够加紧追赶,不要让“西方成为潮流”,让“华流才是最吊的”。
本文作者 @旺仔产品笔记 。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
