风控中必做的数据分析
编辑导语:处于大数据时代的我们,离不开数据分析,风控行业也是如此。本文以风控数据分析为例,拆解其数据分析过程,由此说明,风控中的数据分析跟其他的互联网业务是互通的,而数据分析技能在任何互联网行业都是通用的。
大数据领域就没有不做数据分析的,大数据风控也不例外。我的观点是风控和其他互联网业务都是互通的,本文介绍下风控中必做的数据分析,用以说明数据分析是一通百通的。
工欲善其事,必先利其器。先说下数据分析的工具。分析工具,最通用的包括 Excel、SQL 和 Python。
即使大家是技术岗位,也没有必要技能歧视,用 Python 并不会比用 Excel 和 SQL 高级。算法工程师都自嘲 SQL boy。SQL 是数据分析师以及算法工程师用的最多的技能。
能不能从海量的业务数据中取出正确的数据,是解决问题的前提。而 Excel 透视表强大到万物皆可透视。不夸张地说,我就没见过透视表解决不了的问题。
数据分析平台,开源的有 metabase,收费的有 tableau,都可以连接数据库实时交互,并提供丰富的智能仪表盘。
个人推荐开源的 BI 工具 Metabase,它具有可视化操作界面的数据分析和查询功能,让不懂 SQL 的用户可能够快速掌握业务数据,也支持团队共享业务数据,是一个很不错的 BI 解决方案。
一、业务理解
如果一家金融机构聘请你给他们的风控业务做咨询,你知道怎么办吗?
别告诉我,你想硬搬风控建模比赛的那套东西。不要掉价。
解决方案一定是针对当前业务和用户客群独家定制的。你可以嫁接 kaggle 比赛的经验,但要站在巨人的肩膀上。好比你训练一个人脸识别工具,你不能找到了经典的网络结果就万事大吉了,你需要去 fine-tune。
那么怎么理解业务?
这个问题等同于怎么理解你的客户。客户是你业务唯一重要的资源。Know your customer!
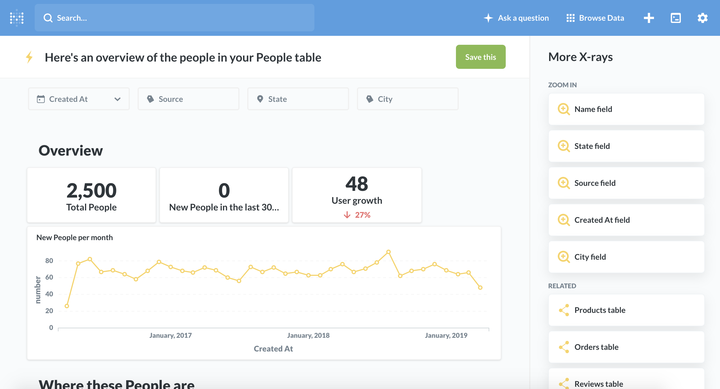
用户画像是了解你的客户的有效方式,常见的用户画像包括但不限于年龄、性别、手机归属地、学历、职业、婚姻状态、机型、银行卡、消费、app 偏好等。互金用户还有新老户比例、额度、息费、多头程度、借款次数、借款金额、展期次数、逾期次数、逾期升期等。
客户的城市分布就可以通过统计作图如下,从而对业务覆盖范围有清楚的认识。
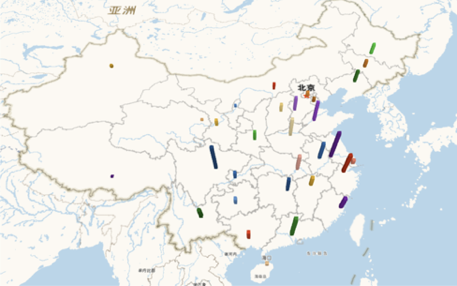
客群基础信息的画像适合于任何一个互联网 to C 的业务场景,可以据此了解自己的客群分布。如果要拓展新用户,它就帮你确定了投放渠道和产品定价等。
但要想真正对业务提供 sense,与业务直接相关的数据是最重要的。上面的新老户比例、额度息费、多头、借款次数与金额、展期次数、逾期次数、逾期升期等就是这样的数据。
我们可以围绕这些数据构建出对业务的理解,例如统计出如下数据结果。
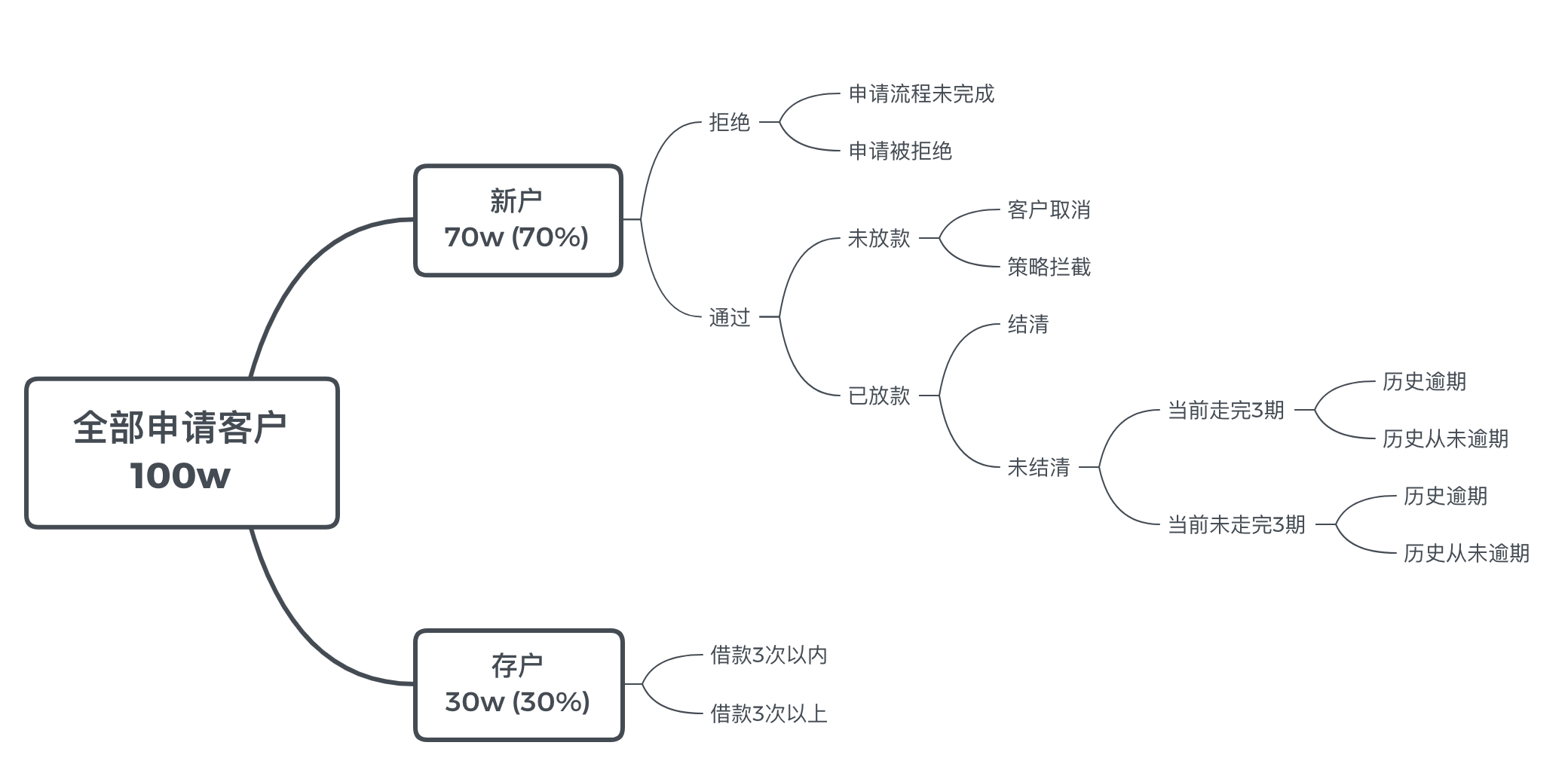
需要说明的是,对于业务的理解,需要分析的绝不止以上内容。
通过 KYC,你可以大致知道发力的方向在哪里,是拓展新户还是挖掘存户,是提升风控能力还是优化产品设计,等等。
二、漏斗分析
进件漏斗分析可以帮助我们定位到产品设计的薄弱位置,从而针对优化。
不失一般性,进件漏斗可以是,点击->下载->点击申请->个人信息->运营商认证->人脸识别->规则通过->模型通过->绑定银行卡->开始借款—>放款。
在这,申请流程假设为填写个人信息,再手机号认证,再人脸识别,再进行强规则审批,再到模型审批,通过之后再绑卡,后进行借款。这套流程设计控制了客户转化链路,审批前除必要的信息外,绑卡操作进行了后置,尽量减少转化损失。
这个漏斗分析很容易就可以计算出来,我们可以区分关注的渠道,在贷前场景中我们一般很关注不同渠道的转化情况,以便对渠道进行优化。转化链路还可以往后追加。
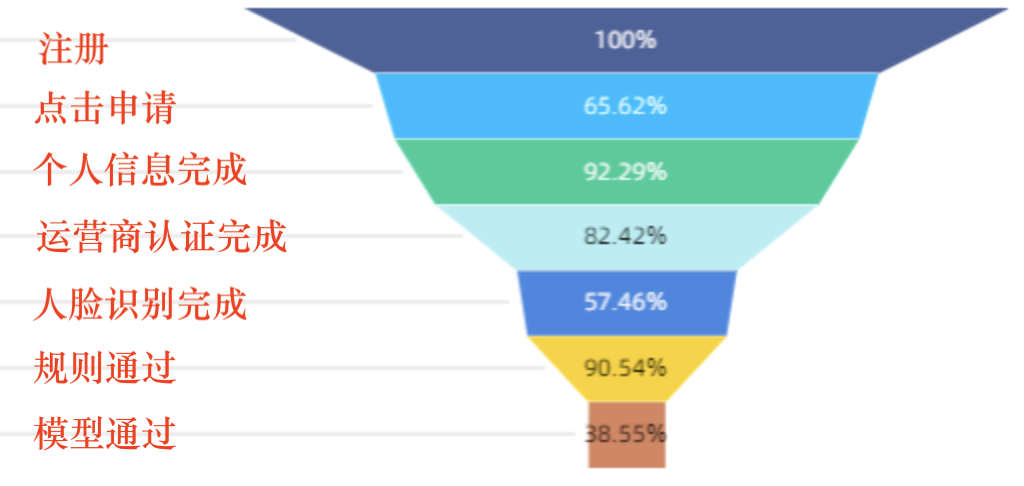
你的产品形式也许需要关注的点会和上面有所差异,但思路应该没有区别。漏斗转化能帮助你了解到用户容易在什么环节发生流失。转化流和行业一般情况做对比,就可以快速了解你的产品设计有没有大的问题。
不同时期业务的重心可能不同,需要关注的转化也可能不同。
三、前端分析
前端指的是用户在申请时就可以统计得到的数据,例如申请量、通过率、PSI、CSI 和拒绝瀑布流等,漏斗分析一般也是前端分析。
申请流量和质量的变化,可以关注到天的粒度,甚至可以是小时的粒度。一张折线图就可以表现出来,不同渠道可以放在同一张图里方便对比。用户质量可以通过模型分的分布或者查询的重要变量的分布衡量出来,如多头、收入等。
PSI是群体稳定性指标(Population Stability Index),刻画了不同期样本在各分数段分布的稳定性。每个月申请流量的评分分布差异大不大,直接影响了决策结果的分布。
CSI是特征稳定性指标(Characteristic Stability Index),用来衡量特征层面的变化。PSI 对应模型分,CSI 对应特征变量。特征有时候不像模型分能分布地那么开,像性别就只有男、女,如果还有未知,也就三种。
因为模型分是由特征经过一套算法流计算出来的,模型分是一系列特征的表现。PSI 异常的话,必然是某个或者某些特征发生异常,通过 CSI 分析就可以定位到哪些特征出现了问题。后续就是针对性排除原因。
在申请环节,拒绝是一个瀑布流的过程。反欺诈拒绝的人,不用往后进入到政策审批环节,政策拒绝也不用在考虑模型拒不拒绝,因而这个流程可以统计出来,以监控拒绝瀑布流的稳定性。
四、后端分析
后端指的是用户在申请时,你无法得知,需要后延一个表现期才能计算得到的数据,例如逾期率、模型效果等。表现期可长可短,也可以是首逾,取决于具体的业务目标和数据情况。
逾期率,各家定义可能不太一样,例如当季逾期贷款剩余本金/当季度放款总剩余本金,可以用来从横向比较一下坏账的波动。对于模型层面,逾期率往往指的是坏用户占比,是人数而非金额的比例。
这个指标计算是需要经过一个时间窗口的,今天的用户会是什么风险,需要以后才能知道。这也就是为什么前端分析很重要了,申请通过用户的质量通过模型分和重要特征分布已经进行了一轮刻画了。当然,这些前端信息并不能完全衡量出后端的风险。
Vintage分析是反映不同账龄周期用户的风险情况,直白地说,是各个时间阶段(如月份)申请人在往后各个账龄下有没有出现过 M1+逾期(或其他)的统计结果。
vintage 分析把不同期的样本放在了一起,可以用来观察不同期客群风险的变化,然后确定是流量本身的变化,还是宏观形形势的变化,还是风控策略的变化等等。
另外,vintage 最常见的用途是确定表现期,因为你观察到了各个账龄下的风险表现,取一个合适的账龄长度就有据可循了。
迁徙率和滚动率,我都觉得它俩本质上并没有说很么区别,是反应用户状态变化的比例。迁徙率呢,贷款从某一状态进入到下一个状态,如正常还款到 M1 期还款状态,M1 变化成 M2 期还款状态。
滚动率呢,首逾的用户有多少会变成逾期 7+,然后有多少会变成 M1+,到 M2+,到 M3+等。逾期状态的滚动分析有助于我们确定建模目标。假如逾期 7+的人有很多人还会还,但逾期 30+的人基本就不还款了,那我们就可以以 30+为坏定义。大抵如此。
排序性和准确性,用来量化模型效果,主要通过 Lift、Odds、KS、AUC、Gini 等指标进行反映,其中 KS 值应用尤为场景。KS 值的优势在于它反应的就是取最优决策点时好坏用户被拒绝掉的差异,和策略制定是直接相关的,可通过 SQL 和 Excel 计算。
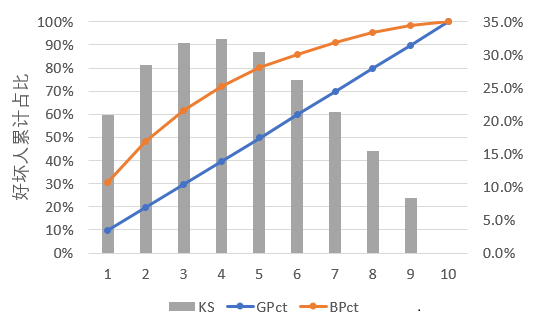
如大家所见,在风控领域所在的数据分析,应该和其他互联网领域的数分并无本质区别。
因为风控和其他业务一样,本质都是用户生命周期管理。基于相同的底层逻辑,数据分析必然也并无二致。
作者@雷帅
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
