抢人、抢数据,AI原生应用“难产”困局
自ChatGPT发布以来,大模型风潮在国内外如雨后春笋般涌现。
从百模大战的火热到如今对原生应用的推崇,短短一年间,大模型经历了千山万水的“奇妙征程”。
2023年3月16日,百度率先发布首个和ChatGPT竞争的大模型“文心一言”,截至10月,国内已经涌现出了238个大模型,几乎每一天都有新的大模型问世。2023年第一季度,超过17万家中国AI企业如涌泉般冒了出来。
然而,与竞争激烈的赛道形成鲜明对比的是,基于大模型的应用产品却寥寥无几。
过去几个月,无数互联网巨头反复强调AI原生应用的重要性。百川智能创始人、CEO 王小川认为,大模型的创业核心,是好技术如何匹配产品;360集团创始人周鸿祎表示,360的人工智能战略用四个字形容就是“两翼齐飞”,先占据应用场景,同步全力发展核心算法技术;李彦宏更是直言不讳:“中国的大模型很多,但是基于大模型开发出来的AI原生应用却非常少。”
其实大厂们也并非“光说不练”,今年下半年,百度一口气发布超过20款AI原生应用;腾讯云推出高性能应用服务 HAI,号称10分钟开发专属AI应用;字节跳动成立新部门Flow发力AI应用层……但事实是,截至目前,相比国外动辄千百个大热的AI原生应用,国内真正称得上火热的应用仍然“难产”。
如此现状不得不让人追问,AI原生应用,究竟还要跨过几道坎?
一、变现之难:赚取真金白银的门槛提高
如何赚钱,是每一家人工智能公司无法回避的问题。
身处大模型赛道,即使是“家大业大”的大厂,也面临着“大象难以转身”的问题。零一万物CEO李开复曾表示,大厂的优势是资源多、GPU多、人多、钱多、数据多,但大厂们有一个挑战:很难放弃已有的商业模式。
“开发一个新应用需要克服两个主要问题:一是要超越已有的大型应用,这非常困难;二是要开发新的应用取代旧的应用,就像一家公司很难在拥有QQ的同时再开发一个微信一样,因为已有的平台价值巨大,不愿意放弃。在这种情况下,创业公司虽然没有丰富的资源,但他们的优势在于没有历史包袱。”
然而,创业者们的处境同样艰难,事实证明,像OpenAI那样直接面向C端用户的模式,在国内市场面临着巨大的挑战,因为国内C端用户的付费意愿相对较弱。因此,更多的大模型创业公司选择为特定垂直行业,如医疗、金融、法律等开发专门的解决方案,为不同行业提供定制化的大模型服务,为B端客户提供服务并收取费用。
这些公司需要面对To B型产品的固有问题,包括依赖高续约率、回款周期长等,对于“烧钱如烧纸”的大模型赛道,无疑提高了门槛。
北京开放传神科技有限公司创始人、CEO陈冉在接受媒体采访时表示,国内应用都在试图产生价值,但很少实现盈利,做数字人的“小作坊”倒是真挣钱了。
更雪上加霜的是,随着企业在大模型领域布局的时间越长,需要的资本就越多,融资轮次越多,投资人对于企业在技术实力和盈利转化能力方面的要求就越严苛。
多位接受《IT时报》采访的业内人士表示,当前投资人对于大模型赛道初创公司的热情正在“降温”。与过去“井喷期”投资者慷慨解囊不同,现在投资者在考虑投资大模型项目时,会对市场需求、技术实力、商业模式以及团队能力等方面进行更为全面的评估,他们对于“投概念”和“产生收入”的容忍期正在缩短。
量子位智库发布的《2023十大AI商业落地趋势》显示,今年上半年,国内约有二十家大模型公司获得超过60亿元的融资,全球金额占比仅为6%,国内实际交易金额较少。
“目前的环境是雷声大雨点小,公司多收入少。”北京医者信息科技有限公司CEO刘呈辉此前在接受《IT时报》记者采访时表示,国内应用层能产生实际应用和实际收入的场景和公司还非常少,相比之下,有自己的垂直模型、场景能挣到钱的公司,才能真正获得投资者青睐。
二、数据之争:高质量数据成本高、获取难
近日,谷歌发布的Gemini新模型陷入数据使用争议,据称其中文部分使用了文心一言进行训练,这一事件引发了全球关于大模型数据短缺问题的广泛讨论。
图源:谷歌
无论是原生应用还是其底层基础大模型,数据至关重要。然而,高质量的语料匮乏已成为限制这一领域发展的关键瓶颈之一。
业内人士指出,尽管公有数据如互联网上的信息易于获取,但质量和针对性往往难以满足专业模型的需求。
相比之下,私有数据具有高度的专业性和针对性,对于训练精准的垂直类模型具有极高的价值。
以医疗数据为例,获取高质量的数据集至关重要,但由于医疗数据的获取和标注需要大量的人力、物力和时间,因此其成本相对较高,获取的渠道也十分有限。这类数据不仅难以在互联网上找到,而且由于涉及个人隐私,获取和使用也需遵守严格的法规和伦理标准。
浦因科技(上海)有限公司首席科学家秦兴虎告诉《IT时报》记者,在其所负责的医学大模型项目中,团队初期购买了英国生物银行的公共数据进行大模型训练,这些数据主要来自欧洲人群。为确保模型在国内的普适性,他们还需要使用中国人群的数据来更新和训练模型,这在无形中增加了项目成本。
对于国内企业而言,他们还面临着即使有钱也难以购买到合适数据的困境。中文语料库的内容相对匮乏,进一步加剧了数据获取的挑战。
因此,对于企业来说,如何合法、有效地获取和使用高质量数据,将其转化为模型训练、开发AI原生应用的宝贵资源,确实是一个重要的战略问题。
五、人才之困:5个岗位争夺2个人才
AI原生应用作为大模型产业的核心产品,在研发和落地试错过程中面临诸多不确定性。人才成为决定成功与否的关键因素,也成了现阶段大模型竞争中的重要砝码。
关于国内人工智能人才的储备,回顾中国的大模型产业发展史,可以发现“清华系”的身影无处不在。
当国内对人工智能的研究还是一片空白的时期,清华大学最早开出的人工智能课程,也孕育出了目前国内人工智能领域的熠熠群星。无论是王小川还是智浦AI联合创始人唐杰,抑或欲打造“中国版OpenAI”光年之外的原美团联合创始人王慧文,都来自这里。
在此轮大模型创业背后的投资方中,“清华系”的创投者们也颇为瞩目,包括图灵创投、卓源资本、清华控股、水木清华校友种子基金、无限基金SEE Fund等清华系创投机构也频频出手。
尽管如此,必须看到的是,由于大模型技术门槛较高,国内大模型人才主要分布在少数顶尖高校和科研机构,人才短缺问题日益严重,许多创业公司甚至面临着招聘困难。
“现在国内做基座类模型的人才90%都出自清华,国内真正会调模型、训练模型的甚至不超过200个人。”刘呈辉表示,由于行业本身的人才储备有限,加上大模型的突然“火爆”,人才短缺问题显得尤为突出,如果不在高校具备一定的人才资源,创业公司连招人都会变得很困难。
知名咨询公司麦肯锡一份关于人工智能的报告显示,预计2030年中国对AI专业人员的需求将增至2022年的6倍,人才缺口将达到400万人。
据脉脉高聘11月发布的《2023人工智能人才洞察》报告显示,2023年1—8月,人工智能新发岗位量已与2022年全年持平。2022年人工智能行业人才供需比为0.63,而2023年1—8月下探至0.39,相当于5个岗位要争夺2个人才。
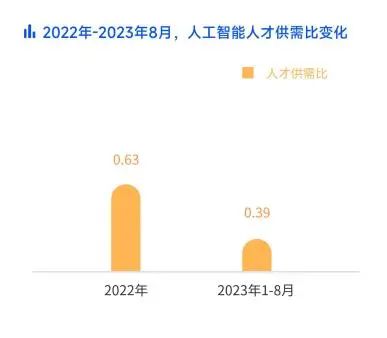
图源:脉脉高聘
可以看到,AI原生应用“难产”的背后,面临着变现之难、数据之争和人才之困等多重挑战。Gartner发布的《2023年中国数据分析和人工智能技术成熟度曲线》指出,当前国内生成式AI技术仍处于“期望膨胀期”。只有当整个AI行业在“期望膨胀期”中保持谨慎,才能意识到将大模型的潜能转化为创新应用尚需克服不小的挑战。
作者:贾天荣,编辑:潘少颖,孙妍
来源公众号:IT时报(ID:vittimes),做报纸,也懂互联网。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
