Meta 新模型:如果我每14秒生成一个高清视频,好莱坞的各位要如何应对|「变压器」
利用人工智能来合成视频一直是该领域的难题,因为其中最关键的一环——映射与合成,缺乏优秀的模型算法,只能利用卷积神经网络(CNN)和生成对抗网络(GAN)来不断提取特征、生成、判断,直至最后结果。比如此前曾大火的Deepfake技术,俗称人工智能换脸,生成一个短短几秒的“换头”视频也需要10分钟左右的时间。
以后就不一样了,Meta在12月的月末发布了一篇论文《Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis》。论文提出了一个新的模型,也就是标题中的Fairy。Fairy能够在仅14秒内生成120帧的512×384分辨率视频(30 FPS,时长为4秒),超过了之前的方法至少44倍的速度。

原图Fairy合成的视频
这是一种比较另类的图像编辑扩散模型,使其摇身一变,成为了视频编辑应用。
Fairy的技术核心是“锚点式跨帧注意力”机制,它可以在帧之间隐式传播扩散特征,确保时间上的连贯性和高保真度合成。有了这个机制后,Fairy不仅解决了以前模型中的内存和处理速度限制,还通过独特的数据增强策略改进了时间一致性。这种策略使模型对源图像和目标图像中的仿射变换保持等变性。
“锚点式跨帧注意力”说的直白一点,就是允许模型在不同帧之间建立时间对应关系。
比如下面这几张图,左边的猫和右边的船上面都有一个红点,代表模型定位了图中物体的特征,Fairy模型中,这个红点叫做查询点(query point)。物体开始移动,途中的红点会跟随其移动,这是模型将要分析的另一帧,目的是找到与查询点相对应的区域或特征,而这个几帧后的红点叫做目标帧(target frame)。所谓锚点式跨帧注意力,正是评估查询点在当前帧中的特征,并将这些特征与目标帧中的特征进行比较,以估计最佳匹配。

查询点
那么“锚点”又是指什么呢?如果放在其他模型里,锚点指的是用来参考的点。图片以及视频中的锚点,则特指用于稳定识别、追踪或定位特征的固定参考点。比如上文提到的猫鼻子,就是特定的面部特征锚点(如眼角或嘴角)。视频是有多个连续的图片组成的,在Fairy模型中,会从某一帧图片里的K个锚点帧中提取扩散特征,并将提取出的特征定义为一组全局特征,以便传播到后续帧。
在生成每个新帧时,Fairy模型用跨帧注意力替换自注意力层,这种注意力是针对锚点帧的缓存特征。通过跨帧注意力,每个帧中的token取用锚点帧中展示出相似语义内容的特征,从而增强了一致性。
Fairy通过结合跨帧注意力和对应估计,改进了扩散模型中的特征跟踪和传播方法。模型把跨帧注意力当成是一种相似性度量,以评估不同帧之间token的对应关系。这种方法使得相似的语义区域在不同帧中获得更高的注意力。通过这种注意力机制,Fairy在帧间对相似区域进行加权求和,从而细化和传播当前特征,显著减少帧间特征差异。
这也是为什么Fairy能够那么快就合成出一个新的视频,因为从技术原理上来看,它只合成了一张图片,剩下所有的内容都是这张图片连续扩散的结果。很像是一种讨巧,其实更多的像是“偷懒和投机”。人工智能和人理解世界的方式不同,它所表现出来的,就是对“最低劳动力成本”的完美诠释。

Fairy将原视频转换为新的风格
革视频特效行业的命
Fairy对于视频编辑行业来说,可能会带来一场革命性的变化。当下视频合成最主要的用途是制作特效,我们熟悉的特效大片每一帧都是单独制作的,因此每一帧所耗费的成本大约数百到数千美元,平均下来相当于每分钟烧掉4万美元。
试想一下,一旦采用Fairy,特效大片动辄几千万几百万的特效费用,将会直接减少至几千美金,且制作周期大幅度缩短,以前需要花费几个月来渲染,以后兴许只需要几个礼拜。
有可能你会有疑惑,现在的一些视频软件也可以做到类似的功能,比如抖音、快手,就可以实时美颜,或者添加道具跟随视频中物体移动,为什么他们就不能冲击视频合成行业呢?首先是商业场景对技术的需求不同,需要满足直播、手机等内存比较小的设备这些先天的条件下,就没办法使用像Fairy一样的扩散方法,最后技术产出的表现力也就没办法做到那么出色。
就以论文提到的猫举例,Fairy将视频里的猫变成狮子、给猫配上墨镜、或者把白猫变成黑猫,最多也就花费几秒钟而已。你仔细看,合成后的视频特效是会跟随猫的面部朝向而改变的,在墨镜那张图上,这点表现的最明显。

对同一视频合成不同风格的心视频
而且Fairy目前还只是个“宝宝”。因为任何一个模型从诞生到使用,中间必不可少的一个环节叫做“调试”。调试主要由两件事组成,第一个是调整模型训练、推理以及最后的输出,将其变成更符合实际商业场景化的形式。这个过程可以让模型表现出更好的性能。第二件事是压缩、优化模型,提高模型的运行效率,缩减运行成本,用最短时间完成业务。
另外Fairy除了能够生成高质量视频,还能够以前所未有的速度生成高分辨率的视频,这个提升也是巨大的。论文用生成的1000个视频和现有的方法进行比较,包括TokenFlow、Renderer和Gen-1等方法。评估结果显示,Fairy在质量上超过了之前的最先进方法。因此研究团队对此称道“这是迄今为止视频/视频生成文献中最大规模的评估。”
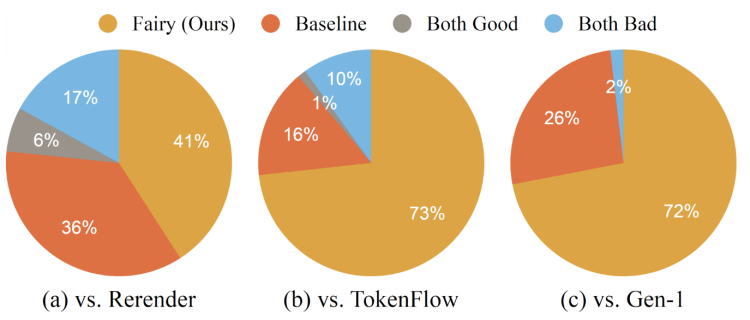
与其他模型的比较,占比越高代表质量越好
Fairy的出现可能会开启一波视频生成热,就像GPT开启文字生成热潮,DALL·E开启图片生成热潮那样。视频合成领域虽然有Deepfake那样的先锋,不过在结合实际的训练、推理、交互、生成等等一系列综合体验来说,Fairy是独树一帜的存在。毕竟它太快了,快到让人觉得有些不可思议。好莱坞的好日子好像又变短了一些。
2017年,来自谷歌的几个研究员写下《Attention is All you need》的题目,给世界带来了Transformer模型架构,它成为了今天“大模型”繁荣背后无可争议的根基,OpenAI的GPT,Meta的Llama以及一众最主流大语言模型都是在Transformer的基础上生长起来,今天还有一批又一批聪明的研究者在不停尝试提出比Transformer更强的模型架构。
某种程度上,今天所有AI模型层面的研究都在围绕对Transformer的掌控与超越展开。但这样一个划时代的研究在当时并未立刻引起所有人的重视,而这种“嗅觉”的差异也很大程度决定了今天的AI格局——OpenAI在这篇论文出现第二天就立刻彻底转向了Transformer架构,然后2020年5月OpenAI基于Transformer架构的GPT-3论文发表,2年后ChatGPT出现,一切都不再相同。
「变压器」这个栏目名来自对Transformer的直译,我们会拆解和介绍关于AI及相关技术的最新论文和最前沿研究,希望像OpenAI当年看到Transformer一样,帮助更多人遇到自己的「变压器」时刻,比一部分人更早进入生成式AI的世代。
作者:苗正
来源公众号:硅星人Pro(ID:Si-Planet),硅(Si)是创造未来的基础,欢迎来到这个星球。
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
