OpenAI最强推理模型O1正式发布,一起回顾那些提升大模型推理能力的黑科技
9月13日凌晨,OpenAI爆出重磅消息,正式发布了OpenAI O1推理模型。
O1模型的特殊之处在于其强大的推理能力,和OpenAI其他模型不同,O1模型更像人类大脑的“系统2”,擅长慢思考,在作出回答之前会进行“深思熟虑”,产生一个长长的思维链,并尝试通过不同的策略进行推理和反思,从而确保回答的质量和深度。
因此,相比其他模型,O1模型“更大,更强,更慢,也更贵”。
Greg Brockman这样评价O1模型:
“可以这样理解,我们的模型进行系统 I 思考,而思维链则解锁了系统 II 思考。人们已经发现,提示模型「一步步思考」可以提升性能。但是通过试错来训练模型,从头到尾这样做,则更为可靠,并且——正如我们在围棋或 Dota 等游戏中所见——可以产生极其令人印象深刻的结果。”
这种强大推理能力使o1在多个行业中具有广泛的应用潜力,尤其是复杂的科学、数学和编程任务。
同时,为了凸显O1模型在推理上的巨大进步,OpenAI也设计了一套完整的评估方案。测试结果令人振奋,在绝大多数需要深度思考和复杂推理的任务中,O1模型都要明显好于GPT-4o模型。
下图是在数学竞赛、编码竞赛和科学问答中的表现,O1要高出gpt4o一大截。
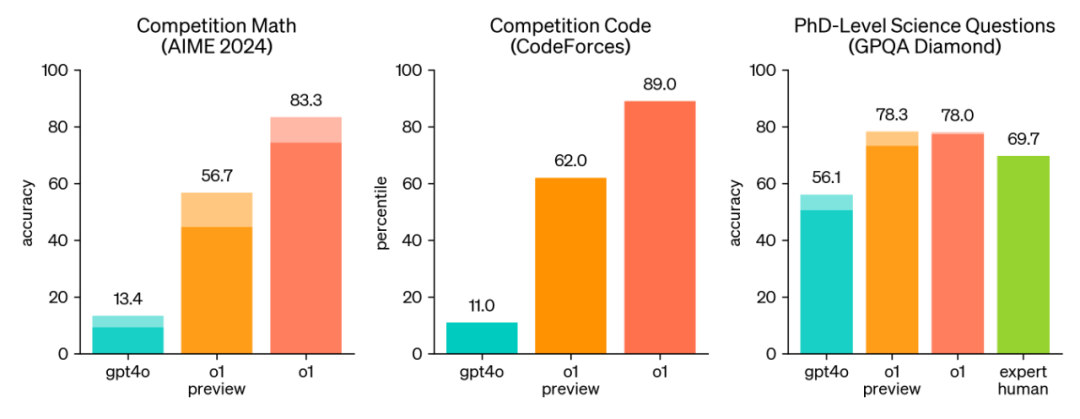
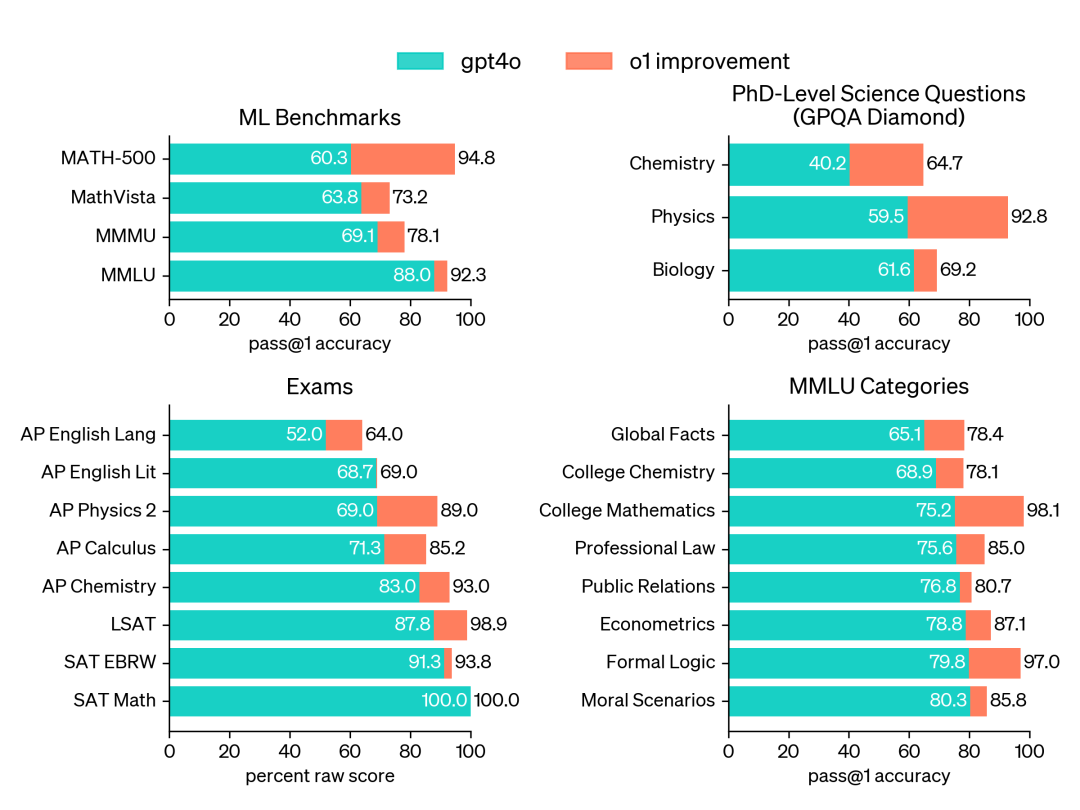
在其他学科领域,比如化学、物理、生物、经济学、逻辑学等领域,o1相比gpt4o也有显著提升。
目前,o1系列包含三款模型,OpenAI o1、OpenAI o1-preview和OpenAI o1-mini。OpenAI o1作为最高级的推理模型,暂不对外开放。OpenAI o1-preview,这个版本更注重深度推理处理,每周可以使用30次。OpenAI o1-mini,这个版本更高效、划算,适用于编码任务,每周可以使用50次。
从目前公开的消息得知,O1模型的核心是思维链(COT,chain of thought),但从实际表现来看,背后一定用到了其他更强大的推理模型,因为单独的COT无法让模型获得如此强的推理结果。
下面,让我们一起回顾一下,那些大幅提升模型推理能力的黑科技。未来随着O1模型的公开和解密,其中很可能就会有风叔介绍到的推理框架。
1. 初级推理框架:COT、COT-SC和TOT
初级推理框架的核心主张,是将大型任务分解为更小、更易于管理的子目标,从而高效处理复杂任务。
主要的子任务分解方式包括:思维链COT(Chain of thought)、自洽性思维链(COT-SC)、思维树TOT(Tree of thought)。
1.1 思维链COT
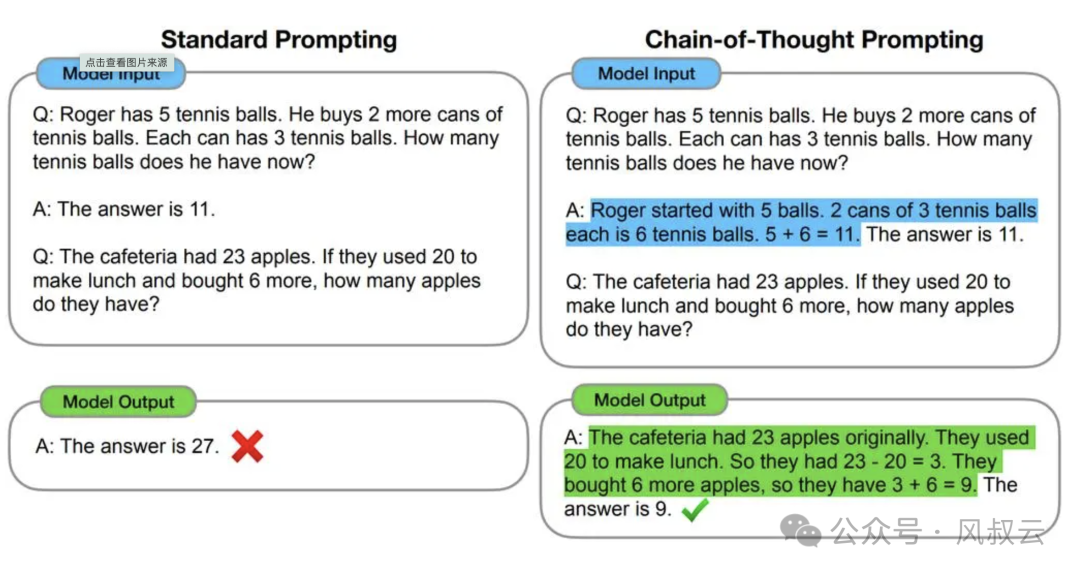
思维链COT的全称是Chain of Thought,当我们对LLM这样要求「think step by step」,会发现LLM会把问题分解成多个步骤,一步一步思考和解决,能使得输出的结果更加准确。这就是思维链,一种线性思维方式。
思维链适用的场景很多,包括各种推理任务,比如:数学问题、尝试推理、符号操作等。思维链方法的好处在于,不用对模型进行训练和微调
在下图的案例中,通过few-shot propmt,引导大模型先对问题进行拆解,再进行解答。其效果要远远好于直接询问。
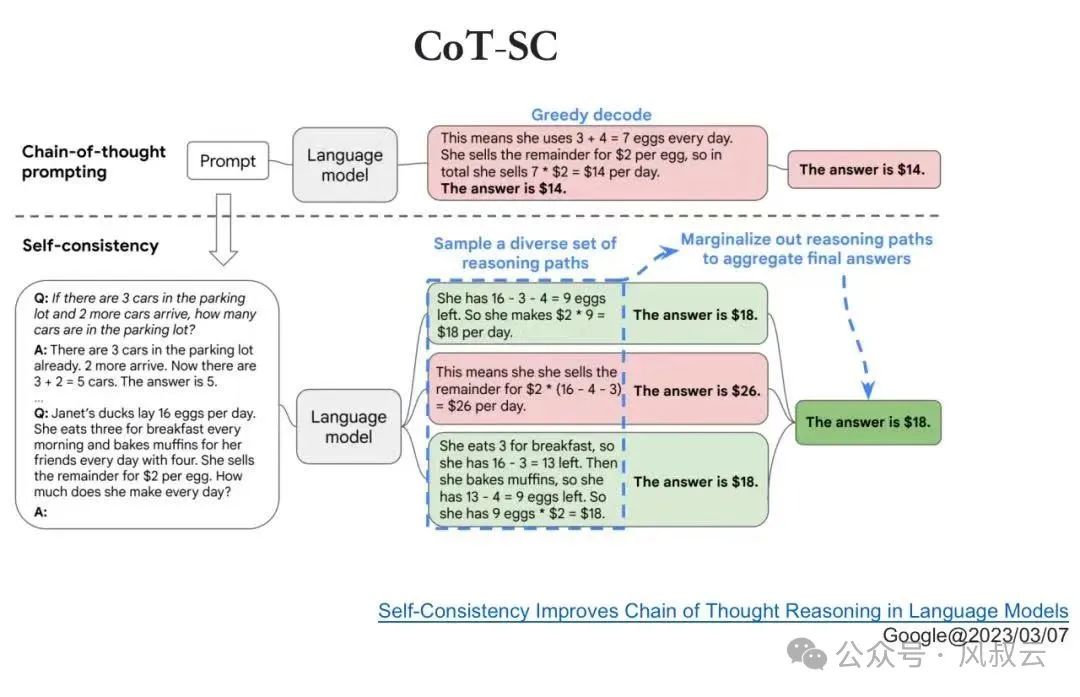
1.2 自洽性COT
所谓自洽性,是指一种为同一问题,生成多个不同的思维链,并对模型进行训练从中挑选出最合适的答案的方法。一个CoT出现错误的概率比较大,我们可以让大模型进行发散,尝试通过多种思路来解决问题,然后投票选择出最佳答案,这就是自洽性CoT。
这种方法特别适用于需要连续推理的复杂任务,例如思维链提示法。它在多个评估标准上显著提升了CoT提示的效果,如在GSM8K上提升了17.9%,在SVAMP上提升了11.0%,在AQuA上提升了12.2%。
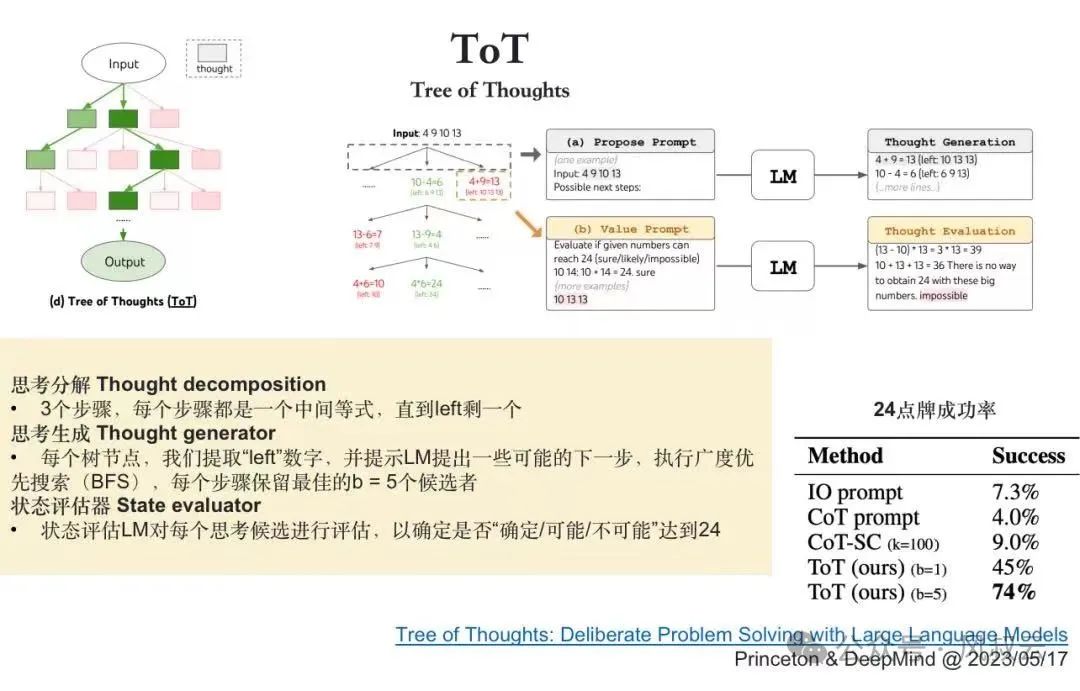
1.3 思维树TOT
思维树TOT是对思维链CoT的进一步扩展,在思维链的每一步,推理出多个分支,拓扑展开成一棵思维树。使用启发式方法评估每个推理分支对问题解决的贡献。选择搜索算法,使用广度优先搜索(BFS)或深度优先搜索(DFS)等算法来探索思维树,并进行前瞻和回溯。
2. 中级推理框架:ReAct、Plan & Execute和Self Discover
初级推理框架的优势是简单,但缺点是缺少可控性,我们很难约束和控制大模型朝哪个方向推理。当推理方向存在错误时,也缺少纠错机制。
因此,以ReAct、Plan & Execute和Self Discover为代表的推理框架,更主张约束大模型的推理方向,并根据环境反馈进行推理纠错。
2.1 ReAct
ReAct通过结合语言模型中的推理(reasoning)和行动(acting)来解决多样化的语言推理和决策任务,因此提供了一种更易于人类理解、诊断和控制的决策和推理过程。
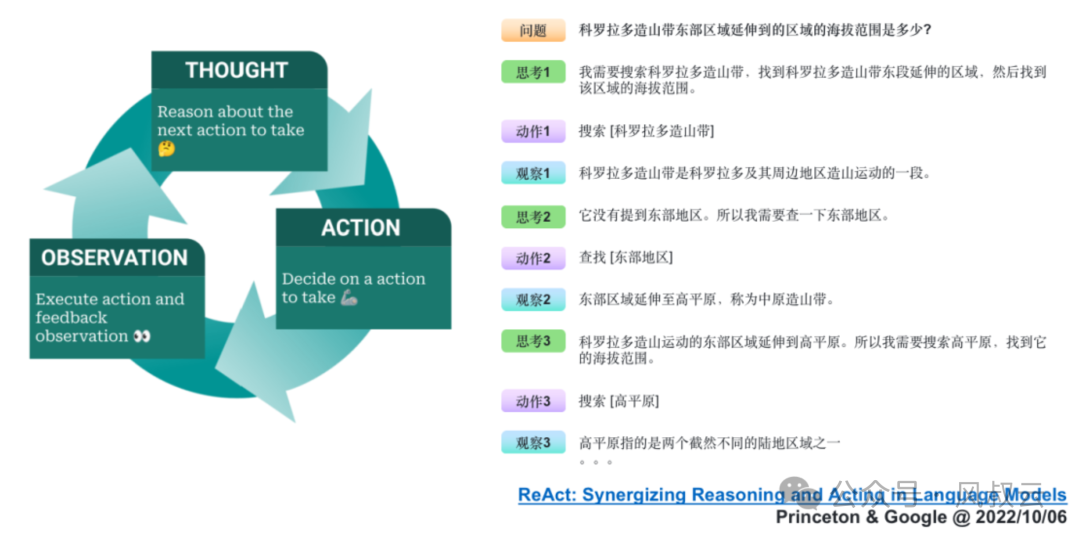
它的典型流程如下图所示,可以用一个有趣的循环来描述:思考(Thought)→ 行动(Action)→ 观察(Observation),简称TAO循环。
思考(Thought):面对一个问题,我们需要进行深入的思考。这个思考过程是关于如何定义问题、确定解决问题所需的关键信息和推理步骤。
行动(Action):确定了思考的方向后,接下来就是行动的时刻。根据我们的思考,采取相应的措施或执行特定的任务,以期望推动问题向解决的方向发展。
观察(Observation):行动之后,我们必须仔细观察结果。这一步是检验我们的行动是否有效,是否接近了问题的答案。
如果观察到的结果并不匹配我们预期的答案,那么就需要回到思考阶段,重新审视问题和行动计划。这样,我们就开始了新一轮的TAO循环,直到找到问题的解决方案。
关于ReAct的更多原理和实践,可参考《AI大模型实战篇:AI Agent设计模式 – ReAct》
2.2 Plan & Execute
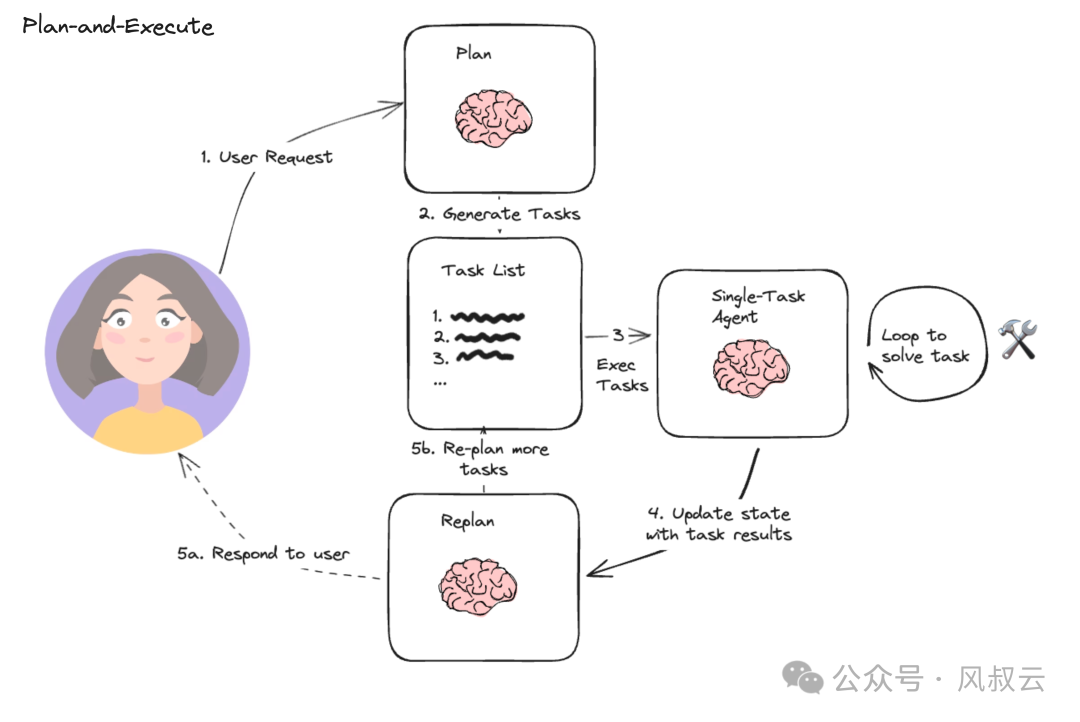
Plan & Execute方法的本质是先计划再执行,即先把用户的问题分解成一个个的子任务,然后再执行各个子任务,并根据执行情况调整计划。
Plan&Execute相比ReAct,最大的不同就是加入了Plan和Replan机制,其架构上包含规划器、执行器和重规划器:
- 规划器Planner负责让 LLM 生成一个多步计划来完成一个大任务,在实际运行中,Planner负责第一次生成计划;
- 执行器接收规划中的步骤,并调用一个或多个工具来完成该任务;
- 重规划器Replanner负责根据实际的执行情况和信息反馈来调整计划
关于Plan & Execute的更多原理和实践,可参考《AI大模型实战篇:AI Agent设计模式 – Plan & Execute》
2.3 Self Discover
这种方法的核心是一个自发现过程,它允许大型语言模型在没有明确标签的情况下,自主地从多个原子推理模块(如批判性思维和逐步思考)中选择,并将其组合成一个推理结构。
Self-Discover框架包含两个主要阶段,如下图所示:
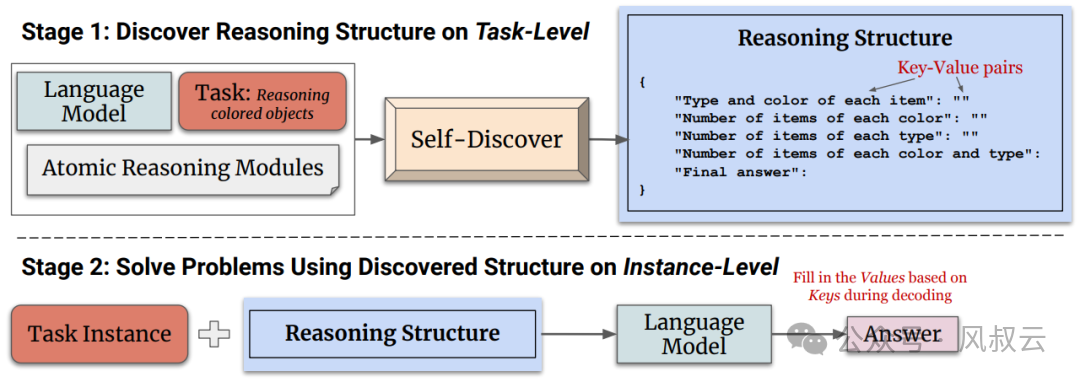
阶段一:自发现特定任务的推理结构
包含三个主要动作:选择(SELECT)、适应(ADAPT)和实施(IMPLEMENT)。
选择:在这个阶段,模型从一组原子推理模块中选择对于解决特定任务有用的模块。模型通过一个元提示来引导选择过程,这个元提示结合了任务示例和原子模块描述。选择过程的目标是确定哪些推理模块对于解决任务是有助的。
适应:一旦选定了相关的推理模块,下一步是调整这些模块的描述使其更适合当前任务。这个过程将一般性的推理模块描述,转化为更具体的任务相关描述。例如对于算术问题,“分解问题”的模块可能被调整为“按顺序计算每个算术操作”。同样,这个过程使用元提示和模型来生成适应任务的推理模块描述。
实施:在适应了推理模块之后,Self-Discover框架将这些适应后的推理模块描述转化为一个结构化的可执行计划。这个计划以键值对的形式呈现,类似于JSON,以便于模型理解和执行。这个过程不仅包括元提示,还包括一个人类编写的推理结构示例,帮助模型更好地将自然语言转化为结构化的推理计划。
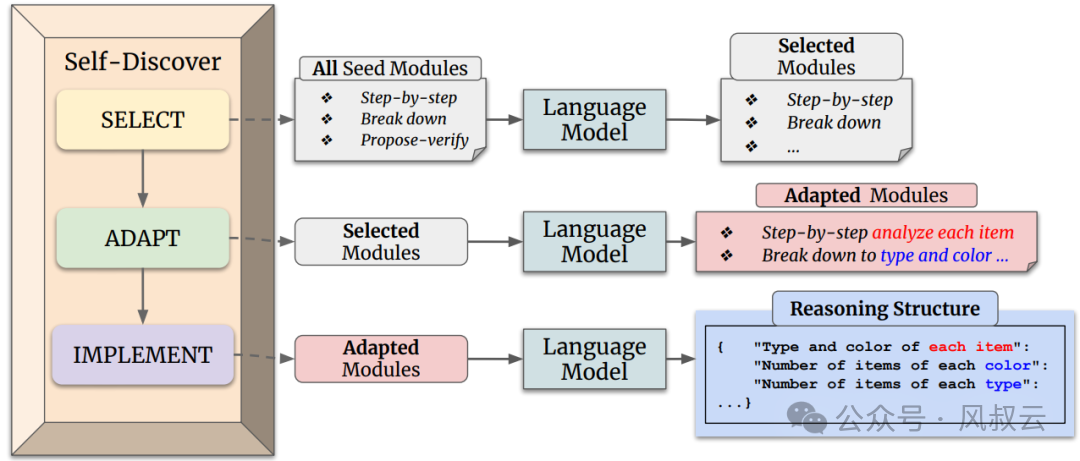
阶段二:应用推理结构
完成阶段一之后,模型将拥有一个专门为当前任务定制的推理结构。在解决问题的实例时,模型只需遵循这个结构,逐步填充JSON中的值,直到得出最终答案。
关于self discover的更多原理和实践,可参考《AI大模型实战篇:Self Discover框架,万万想不到Agent还能这样推理》
3. 高级推理框架,Reflexion和LATS
大模型经过初级和中级推理框架的优化后,能准确地处理一些相对简单的问题,但是在处理复杂的推理任务时,仍然会显得力不从心。
因此,高级推理框架的核心主张就是,通过强化学习技术进行训练,专门用于思考链条更长、反思环节更多的复杂推理任务。
3.1 Reflexion
Reflexion的本质是强化学习,完整的Reflexion框架由三个部分组成:
- 参与者(Actor):根据状态观测量生成文本和动作。参与者在环境中采取行动并接受观察结果,从而形成轨迹。
- 评估者(Evaluator):对参与者的输出进行评价。具体来说,它将生成的轨迹(也被称作短期记忆)作为输入并输出奖励分数。根据人物的不同,使用不同的奖励函数(决策任务使用LLM和基于规则的启发式奖励)。
- 自我反思(Self-Reflection):这个角色由大语言模型承担,能够为未来的试验提供宝贵的反馈。自我反思模型利用奖励信号、当前轨迹和其持久记忆生成具体且相关的反馈,并存储在记忆组件中。Agent会利用这些经验(存储在长期记忆中)来快速改进决策。
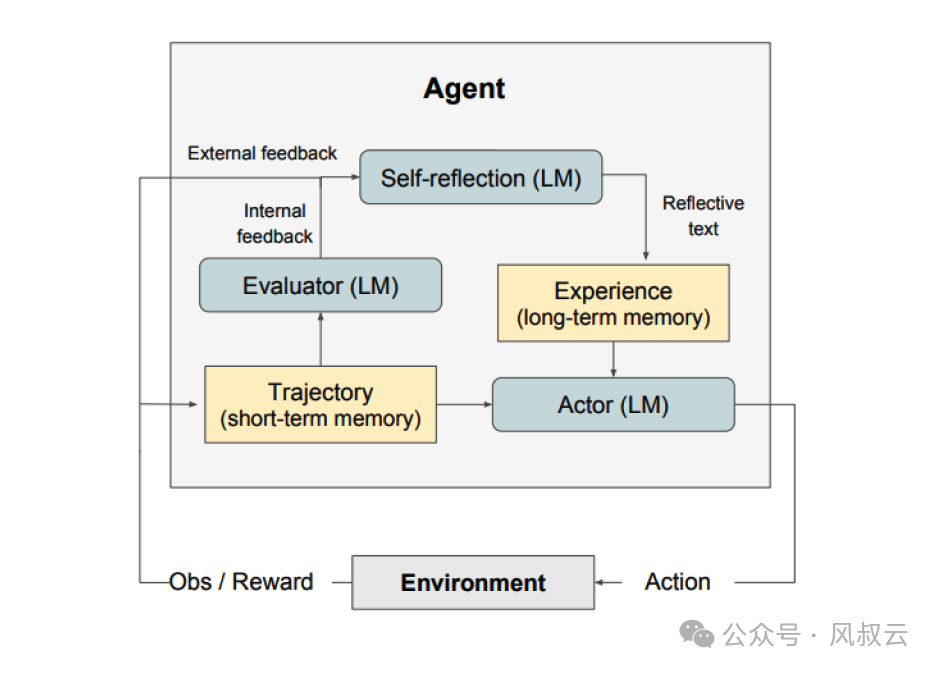
因此,Reflexion模式非常适合以下情况:
大模型需要从尝试和错误中学习:自我反思旨在通过反思过去的错误并将这些知识纳入未来的决策来帮助智能体提高表现。这非常适合大模型需要通过反复试验来学习的任务,例如决策、推理和编程。
传统的强化学习方法失效:传统的强化学习(RL)方法通常需要大量的训练数据和昂贵的模型微调。自我反思提供了一种轻量级替代方案,不需要微调底层语言模型,从而使其在数据和计算资源方面更加高效。
需要细致入微的反馈:自我反思利用语言反馈,这比传统强化学习中使用的标量奖励更加细致和具体。这让大模型能够更好地了解自己的错误,并在后续的试验中做出更有针对性的改进。
后续,风叔也会专门写一篇文章来详细介绍Reflexion框架。
3.2 LATS,可能是目前最强的推理框架
LATS,全称是Language Agent Tree Search,说的更直白一些,LATS = Tree search + ReAct + Plan&Execute+ Reflexion。
ReAct、Plan&Execute、Reflexion的原理在前文都做了介绍,这里不再赘述,详细介绍下Tree Search。
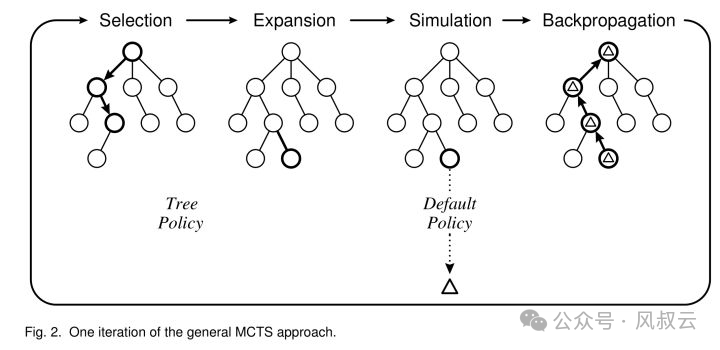
Tree Search是一种树搜索算法,LATS 使用蒙特卡罗树搜索(MCTS)算法,通过平衡探索和利用,找到最优决策路径。
蒙特卡罗树搜索(MCTS)则是一种基于树结构的蒙特卡罗方法。它在整个 2^N(N 为决策次数,即树深度)空间中进行启发式搜索,通过反馈机制寻找最优路径。MCTS 的五个主要核心部分是:
- 树结构:每一个叶子节点到根节点的路径都对应一个解,解空间大小为 2^N。
- 蒙特卡罗方法:通过随机统计方法获取观测结果,驱动搜索过程。
- 损失评估函数:设计一个可量化的损失函数,提供反馈评估解的优劣。
- 反向传播线性优化:采用反向传播对路径上的所有节点进行优化。
- 启发式搜索策略:遵循损失最小化原则,在整个搜索空间上进行启发式搜索。
MCTS 的每个循环包括四个步骤:
- 选择(Selection):从根节点开始,按照最大化某种启发式价值选择子节点,直到到达叶子节点。使用上置信区间算法(UCB)选择子节点。
- 扩展(Expansion):如果叶子节点不是终止节点,扩展该节点,添加一个或多个子节点。
- 仿真(Simulation):从新扩展的节点开始,进行随机模拟,直到到达终止状态。
- 反向传播(Backpropagation):将模拟结果沿着路径反向传播,更新每个节点的统计信息。
LATS的工作流程如下图所示,包括以下步骤:
- 选择 (Selection):即从根节点开始,使用上置信区树 (UCT) 算法选择具有最高 UCT 值的子节点进行扩展。
- 扩展 (Expansion):通过从预训练语言模型 (LM) 中采样 n 个动作扩展树,接收每个动作并返回反馈,然后增加 n 个新的子节点。
- 评估 (Evaluation):为每个新子节点分配一个标量值,以指导搜索算法前进,LATS 通过 LM 生成的评分和自一致性得分设计新的价值函数。
- 模拟 (Simulation):扩展当前选择的节点直到达到终端状态,优先选择最高价值的节点。
- 回溯 (Backpropagation):根据轨迹结果更新树的值,路径中的每个节点的值被更新以反映模拟结果。
- 反思 (Reflection):在遇到不成功的终端节点时,LM 生成自我反思,总结过程中的错误并提出改进方案。这些反思和失败轨迹在后续迭代中作为额外上下文整合,帮助提高模型的表现。
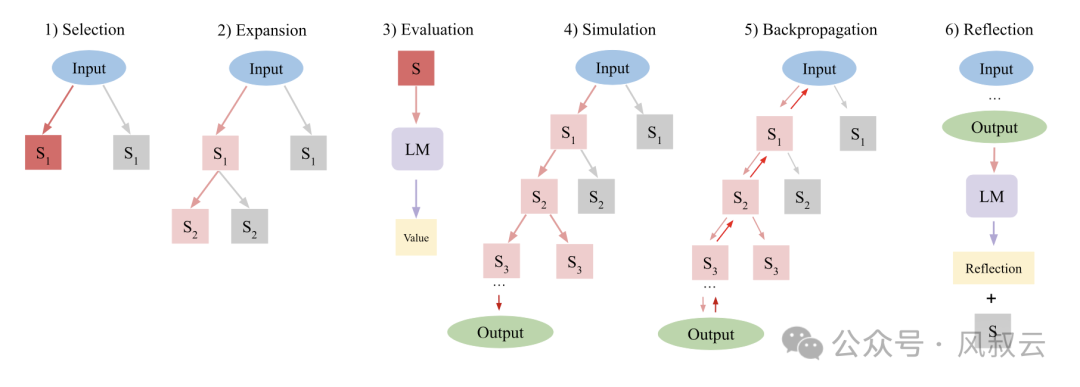
当采取行动后,LATS不仅利用环境反馈,还结合来自语言模型的反馈,以判断推理中是否存在错误并提出替代方案。这种自我反思的能力与其强大的搜索算法相结合,使得LATS更适合处理一些相对复杂的任务。
总结
O1模型的发布,将继续吹响大模型军备竞赛的号角。在处理物理、化学和生物问题时,o1的表现已经和该领域的博士生水平不相上下。在国际数学奥林匹克的资格考试,o1的正确率为83%,成功进入了美国前500名学生的行列。
这样的发展速度令人惊叹,也令人担忧。AGI未来的发展能达到什么上限,我们不得而知。我们能做的,唯有持续学习,跟上AI发展的步伐。
作者:风叔产品总监,公众号:风叔云
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
