从 0 到 1 构建数据生态系列之五:让你的数据生态变得更高效

接这个系列的上一篇《从0到1构建数据生态系列之四:与研发的爱恨情仇》。
好像间隔的时间有点长了,中间插了好几篇其他主题的文章,我们再回归到这个系列。
从早期的数据迁移、数据上报体系的建立,再到数据多维分析BI体系的建立,再到后续的各种不同数据应用服务,诸如各种推荐服务、搜索服务、各种榜单数据的推送服务,整个数据生态已经逐渐丰满了。
随着内部数据业务的逐渐增多,我们对于这些业务服务的把控能力就越低,那么这个时候提升效率将是我们重点关注的问题。
例如:
数据分析BI业务从之前的简单几个统计报表,逐渐增加,越来越复杂,依赖的基础计算数据也越来越多,报表生成出错难以追踪来源,无法很好的建立不同层级的中间数据依赖关系。
数据上报是否正常,有没有异常波动的上报点位,是属于正常情况还是上报异常,比如重放攻击,机器点击。
上一篇提到的,如何提升埋点测试的效率以及准确性,进一步释放人力,减少这种重复性、建设性较低的劳动量。
业务部门大量的数据分析需求,数据提取需求,如何进一步降低这种重复性,建设性比较低BI分析工作,释放BI人员的人力。
各种五花八门的数据服务,如何能有效的监控起来,随时感知服务的故障,并且及时投入人力进行处理。
任务调度系统
在数据上报体系搭建的同时,我们同步开始进行各个业务团队的BI体系的搭建。
我们需要为运营、内容、电商、市场以及产品等各个业务团队提供天、月以及季度等维度的BI报表,以便各个业务团队进行数据化运营、决策。
单纯每天的BI报表多达数十个,每个报表内可能又包含N个维度的数据。
这些BI报表的基础数据来源为:上报体系提供的上报数据,业务方产生的业务数据,各种服务产生的服务数据。
先不说一些实时性的数据分析业务,单论上述的周期性的BI报表业务,我们来看一下整个业务体系的复杂程度:
数十个近百的业务表需要将数据进行周期通过sqoop迁移到大数据中心,进行统一计算。
而对于业务服务产生的服务log,我们需要进行log文件的周期迁移,迁移之后进行数据清洗规整入库,加入到数据中心的原始数据集中。
对于上报体系的数据,由于量大,我们同样需要周期性进行切分,规整合并,以减少HDFS的IO资源消耗。
计算方面,我们进行分层级计算,每个层级之间会有依赖关系。
对于最上层的BI报表,我们有详细的详情业务分析报表,也有汇总的概览报表,他们之间也有依赖关系。
对于涉及的业务类型,有shell脚本、python脚本、java服务、MySQL表操作、Sqoop迁移操作、MR计算任务、Spark计算任务,以及涉及最多的Hive计算。
...
单纯的BI分析业务就涉及到各种复杂的任务依赖关系,一旦前面的环出现问题,后续的其他环节容易受到影响,甚至需要花费巨大的代价去追踪哪些数据是错误的,哪些数据是不受影响的。
对于各个任务的管理也是巨大的问题,他们执行结果的跟踪,依赖网络关系的管理等等。
所以,一方面提升整个业务体系的健壮性,另一方面提升业务体系的效率,有必要引入调度系统进行整个业务体系的调度。
简单服务内部级别的时间调度Timer,再高级点的ScheduledExecutorService,JCronTab等,当然也有系统级别的略微重度的Quartz。
但他们都是基于时间维度的调度框架,对于我们的需求来说,依然太过于轻量级,无法满足需求。
我们需要的是一个系统级别,能够进行任务进行调度,对任务依赖关系进行管理,对任务执行进行追踪等,具备这些复杂功能的调度系统。
我们曾一度调研过早期阿里开源出来的Zeus,并且在之前的工作经历中也曾一度使用过它。
首先宙斯出自于淘宝,品质相对有保障,应用于hadoop作业调度而生,对整个生态契合度高,支持MR、Shell、Hive等各种界面化调度,并且各种配置可视化,使用成本相对较低。
更多的优点就不多说了,感兴趣的可以查找一些资料了解,它还曾一度获得过热门开源项目的头衔。
但结合实际,我们最终还是舍弃了它,一方面我们整个集群使用的是CDH体系,想要嵌入宙斯需要改动的东西很多,二次开发的成本略大,并且实际部署略微复杂,BUG还不少,就目前这个状态,我们并没有太多的时间去折腾。
并且, 整个项目好像维护的并不是很好 ,这意味着一旦上线了,风险还是蛮大的。
最终我们选择了oozie+Hue的方案。
CDH对他天然支持,能够与我们目前的集群体系无缝对接,省却了所有的部署成本,暂时阶段只需要把精力放到学习使用上即可。
通过oozie的工作流机制,加上hue的可视化配置,基本可以满足我们上述的那些问题。
使用oozie+hue的方案,进行各种服务的管理,hive依赖任务的调度,错误的报警,错误日志的追踪等,一站式解决问题。
不过,我们在使用的过程,依然遇到了一些坑,以及解决了一些坑。
例如中文编码的问题,又例如如何处理日渐壮大的依赖树,一旦底层依赖出现故障会造成大片上层依赖任务的中断等等。
我们把部分的依赖判断回归到程序中,而不是统统交给oozie的依赖树来管理,避免部分底层依赖错误造成大面积上层任务中断,这样可以做到部分任务可以继续执行,进行依赖分拆,减少大范围任务重跑的风险。
数据上报体系的监控
这里其实有个故事。
曾有一天,业务人员反馈BI分析报表数据好像有问题,整个数据对不上。
数据测马上启动了对问题的排查,通过一顿的各种数据查询,汇总计算,才发现早在三四天前数据就开始异常了,再进行跟踪,发现那天刚好更新了新版本。
再跟踪问题,发现客户端很多模块进行重构,而之前的相关埋点点位受到了影响,客户端方面没有进行知会, 在测试时又没有进行这部分抽查回归测试。
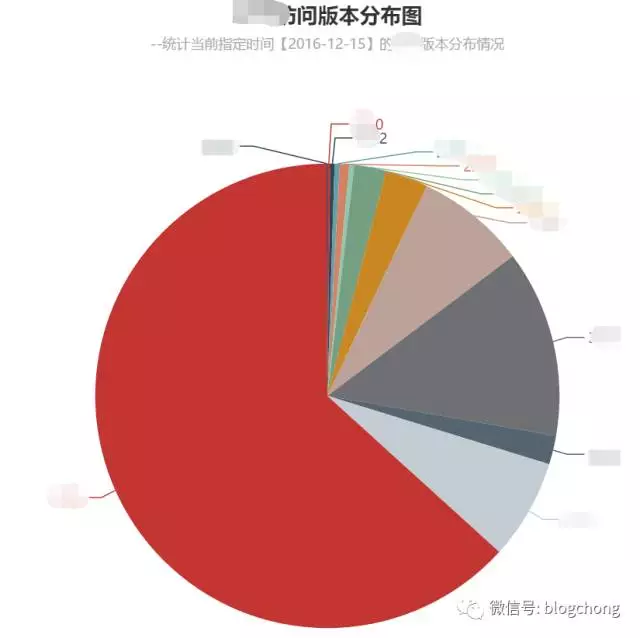
于是,随着版本的更新覆盖,丢失了很多基础数据。
这是一个惨痛的教训,随后,我们一方面制定埋点测试的方案、进行埋点完整性质保方面的梳理,另一方面数据测启动了对数据上报体系的监控。

于是就有了如图,我们对每天,一些重要维度的上报进行了数据统计可视化,检测点位的数据量波动,每天可以随时查看上报情况,此外,根据实际情况建立异常报警模型,一旦发生上报异常进行主动邮件预警,及时跟进。
趋势图是使用echarts画的,页面是spring boot+jsp框架,数据部门从此又多了前端技能,哈哈。
整个检测体系很简单,很粗暴,但是确实有效,对于内部使用,实时掌握上报动态,足够了。
此外,我们还简单的通过守护脚本进程,替代了ganglia+nagios的系统性方案,对各个节点的服务进行监控,进行图表可视化监控,主动预警等。
足够的节省人力,足够的敏捷,以有限的人力解决阶段性的需求为出发点。当然,在一定的阶段之后,必然还是会回归到系统性监控方案中去的。
数据上报完整性测试的痛点
在上一篇中,我们描述过数据上报完整性测试的痛处。
我们需要花费巨大的人力去保证整个上报体系的健壮,因为对于H5页面还好,但对于客户端埋点,客户端一旦发布,出现故障只能通过发布紧急修复版本进行解决,但一样会耽误很多时间,因为整个发布周期至少都是好几天的。
出现如上故事之后,我们着手进行埋点完整性测试机制的搭建。
我们通过测试账号注册的机制,来分离正常账号的流量以及测试账号的流量,通过时间将点位轨迹进行串联,再打通整个实时流程,并且进行点位访问轨迹界面化展示。
基本实现一边点击点位,一边看到上报轨迹,完全同步,一改往日通过日志拦截的方式进行点位测试,根据埋点的编码表,普通的测试人员都可以介入。
数据上报测试机制的完善,大大降低了埋点故障率,确保了上层BI分析业务的健壮性。
开放自助查询体系
即使我们每天为业务部门提供了数十个BI分析的报表,但依然避免不了,我们的BI童鞋每天为各种BI需求奔走。
诸如,电商活动的各种数据调研,产品端各种调研性的数据提取,运营方不同运营位不同运营活动的跟踪等等,这些都是很难做到常规化BI的数据分析提取需求。
但是很多又确确实实是重复性工作,只是因为变量太多,无法做到自动化。
于是,我们开始着手尝试,是否能将部分查询分析的工作转移到业务人员身上,让他们自己去获取自己需要的数据,降低数据团队的压力呢?
我们开始逐渐完善以HUE为核心的自助查询系统,健全自助数据分析体系。
我们对一些Hive的表权限进行隔离,对不同的业务方定制查询模板,模板上注明详细的使用方式,让不懂SQL的业务人员也能根据模板进行一些数据的查询提取等。
例如,运营人员根据查询模板就可以很愉快的改改URL变量,改改时间变量等,拿到他们所需要的对应运营位的各种活动数据,对于我们数据的依赖程度大大降低。
不过,讲真。HUE的整个体系对于那些一点SQL基础的业务人员还是有些使用成本,所以在时机成熟的情况下,还是有必要封装一套高度界面化的自助查询分析系统。
此外,就是我们需要对权限进行严格的隔离,对使用频度进行限制,不然大批量错误的查询会让我们的机器资源过度浪费。
不管怎么样,开放自助查询定然是一个需要去做的事情,将数据童鞋的人力进一步释放出来,放到更有意义的方向上去。
结语
在数据时代,效率至上,所谓效率,不单纯是整体业务的效率,同样也是对应于内部效率的提升。
所以,在不同的阶段下,我们都需要随时反思如何能够进一步的提升效率,结合阶段性的成本投入,进行灵活的健全自己的数据生态效率体系。
不需要说足够完整,在有限的资源下,能够有限解决当前的问题,能够提升一定程度的效率,就是可执行的方案。
下一篇,我们将会把目标放到最上层,即数据从底层一路流转,最终到上层的价值体现。
下一篇暂定为《从0到1构建数据生态系列之六:数据价值体现》。
相关阅读:
从 0 到 1 构建数据生态系列之一:蛮荒时代
从 0 到 1 构建数据生态系列之二:拓荒
从 0 到 1 构建数据生态系列之三:拆解架构图
从 0 到 1 构建数据生态系列之四:与研发的爱恨情仇
从 0 到 1 构建数据生态系列之五:让你的数据生态变得更高效
从 0 到 1 构建数据生态系列之六:数据价值挖掘
来源|数据虫巢
文·blogchong
关键字:数据, 产品经理
版权声明
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处。如若内容有涉嫌抄袭侵权/违法违规/事实不符,请点击 举报 进行投诉反馈!
